Hướng dẫn chi tiết cách Deploy AI Agent lên Production hiệu quả

Deploy AI Agent là quá trình đưa tác nhân AI từ môi trường phát triển lên môi trường production với yêu cầu rõ ràng về kiến trúc, bảo mật và khả năng mở rộng. Bài viết này tập trung vào các bước và thực tiễn kỹ thuật để deploy AI Agent một cách ổn định, bao gồm thiết kế kiến trúc, chọn hạ tầng, mô hình trạng thái, quy trình triển khai, tối ưu chi phí, kiểm thử và giám sát chất lượng.
Những điểm chính
- Kiến trúc hệ thống: Hiểu rõ thiết kế đa lớp giúp bạn quản lý rủi ro vận hành và linh hoạt thay đổi mô hình ngôn ngữ mà không ảnh hưởng đến luồng nghiệp vụ.
- Hạ tầng triển khai: Phân biệt giữa Serverless và Container giúp người đọc lựa chọn môi trường phù hợp để tối ưu hóa hiệu suất phản hồi và chi phí tài nguyên theo đặc thù của từng loại tác vụ AI.
- Mô hình trạng thái: Nắm vững các cơ chế Stateless, Stateful và Event-Driven giúp bạn thiết kế cách quản lý ngữ cảnh và lịch sử hội thoại tối ưu cho khả năng mở rộng hệ thống.
- Quy trình thực chiến: Biết rõ 5 bước từ đóng gói Docker đến thiết lập Health Check giúp chuẩn hóa quy trình đưa AI Agent lên production một cách an toàn, nhất quán và chuyên nghiệp.
- Tối ưu vận hành: Nắm bắt các chiến lược Caching và Infrastructure as Code giúp giảm thiểu chi phí token LLM và tự động hóa quản lý hạ tầng một cách bền vững.
- Danh mục checklist: Rà soát các tiêu chuẩn về bảo mật, giám sát và khả năng phục hồi giúp đảm bảo AI Agent đáp ứng đầy đủ các điều kiện kỹ thuật trước khi chính thức phục vụ người dùng.
- Đánh giá chất lượng: Thực hiện kiểm thử đa tầng và A/B testing giúp kiểm soát chặt chẽ logic suy luận và liên tục cải tiến hiệu quả đầu ra của tác nhân AI.
- Giải đáp thắc mắc: Được làm rõ các vấn đề về kiến trúc stateless, cách quan sát luồng suy luận và chống lạm dụng API để bảo vệ tài nguyên hệ thống hiệu quả.
Kiến trúc AI Agent trên môi trường Production
Khi triển khai AI Agent vào môi trường production, hệ thống cần được thiết kế theo kiến trúc nhiều lớp để hỗ trợ bảo trì, mở rộng và kiểm soát rủi ro vận hành.
- Orchestrator (Lớp điều phối): Sử dụng các framework như LangChain hoặc CrewAI để tách logic điều hướng và suy luận của agent khỏi lớp thực thi mô hình LLM, giúp linh hoạt thay đổi nhà cung cấp mô hình mà không ảnh hưởng đến luồng nghiệp vụ cốt lõi.
- Inference Provider (Lớp suy luận): Áp dụng mô hình Cloud‑native inference thông qua một dịch vụ trung gian hoặc gateway thay vì gọi trực tiếp API, nhằm quản lý lưu lượng, giới hạn tốc độ và xử lý lỗi tập trung.
- Memory (Bộ nhớ): Hạn chế lưu toàn bộ lịch sử hội thoại trong RAM vì dữ liệu sẽ mất khi service khởi động lại. Thay vào đó sử dụng bộ nhớ bền vững với vector database như PostgreSQL kết hợp pgvector để lưu embedding và truy vấn semantic memory cho các phiên làm việc dài hạn.
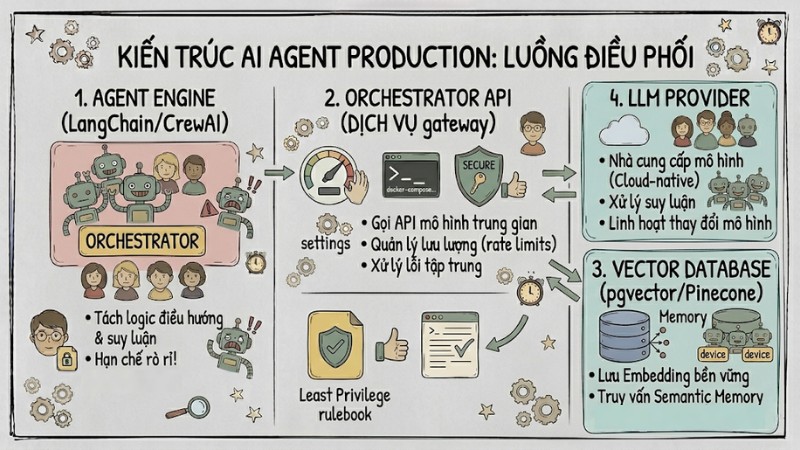
Kiến trúc AI Agent trên môi trường Production
Kiến trúc hạ tầng triển khai AI Agent
Việc lựa chọn giữa serverless và container phụ thuộc vào đặc thù tải công việc và yêu cầu vận hành của AI Agent.
| Tiêu chí | Serverless (AWS Lambda) | Containerized (Render/ECS) |
|---|---|---|
| Phù hợp | Chatbot hoặc tác vụ ngắn, lưu lượng biến động theo thời điểm. | Xử lý nền, tác vụ dài hoặc dịch vụ cần chạy liên tục ổn định. |
| Chi phí | Trả theo số lần gọi và thời gian thực thi. | Thường gắn với chi phí tài nguyên cố định hàng tháng hoặc theo cụm container. |
| Độ trễ | Có cold start khi không có instance đang chạy, cần tối ưu nếu yêu cầu phản hồi nhanh. | Độ trễ ổn định hơn vì service luôn sẵn sàng nếu cấu hình đủ tài nguyên. |
| Quy mô | Tự động mở rộng theo lưu lượng yêu cầu mà không cần quản lý cụm máy chủ. | Cần cấu hình auto‑scaling cho cụm container để đáp ứng các giai đoạn tải cao. |
Lời khuyên: Bạn nên ưu tiên serverless cho ứng dụng có lưu lượng không ổn định hoặc khởi chạy theo sự kiện, và sử dụng container cho các tác vụ dài, khối lượng lớn hoặc yêu cầu thời gian phản hồi ổn định.
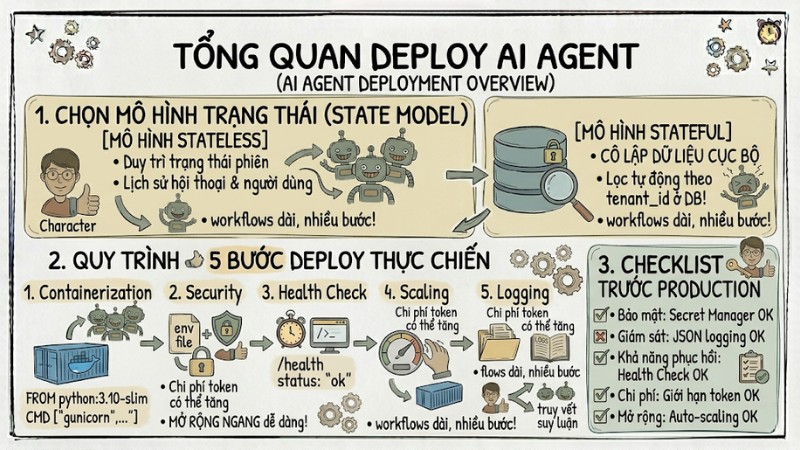
Mô hình trạng thái của AI Agent trong môi trường Production
Mô hình trạng thái xác định cách AI Agent quản lý ngữ cảnh và lưu trữ thông tin trong quá trình xử lý. Việc lựa chọn mô hình phù hợp ảnh hưởng đến kiến trúc hệ thống, cách mở rộng và độ phức tạp vận hành.
Stateless Request-Response Agent
Trong mô hình stateless, mỗi yêu cầu được xử lý độc lập và không dựa trên trạng thái đã lưu trước đó. Toàn bộ ngữ cảnh cần thiết phải được gửi kèm trong payload của từng request.
Mô hình này phù hợp với tác vụ ngắn, một lần như phân loại, trích xuất dữ liệu hoặc phân tích tài liệu. Hệ thống dễ mở rộng ngang vì không cần đồng bộ trạng thái giữa các instance, nhưng chi phí token có thể tăng do phải truyền lặp lại cùng một ngữ cảnh.
Stateful Session-Based Agent
Trong mô hình stateful, agent duy trì trạng thái phiên qua nhiều lượt tương tác, bao gồm lịch sử hội thoại và thông tin người dùng. Trạng thái có thể lưu trong bộ nhớ tạm, Redis hoặc cơ sở dữ liệu tùy thời gian cần giữ.
Kiến trúc cần xác định rõ nơi lưu trạng thái, thời gian lưu, chiến lược dọn dẹp và cách xử lý khi instance gặp lỗi trong lúc phiên đang hoạt động. Nếu trạng thái gắn với từng instance, load balancer cần cấu hình session affinity. Nếu dùng kho trạng thái dùng chung, mọi instance phải truy cập được một cách an toàn.
Event-Driven Asynchronous Agent
Trong mô hình bất đồng bộ điều khiển bằng sự kiện, Agent xử lý tác vụ dựa trên các event thay vì chỉ nhận request đồng bộ từ client. Người dùng gửi tác vụ phức tạp, nhận xác nhận nhanh, và nhận kết quả sau khi hệ thống hoàn tất xử lý thông qua cơ chế thông báo hoặc API truy vấn.
Các tác vụ được đưa vào hàng đợi, worker lấy việc ra xử lý, lưu kết quả và cập nhật trạng thái phù hợp. Mô hình này phù hợp với workflow dài, nhiều bước và không yêu cầu phản hồi tức thì, nhưng đòi hỏi kiến trúc thêm hàng đợi, worker pool, lưu kết quả và cơ chế retry.
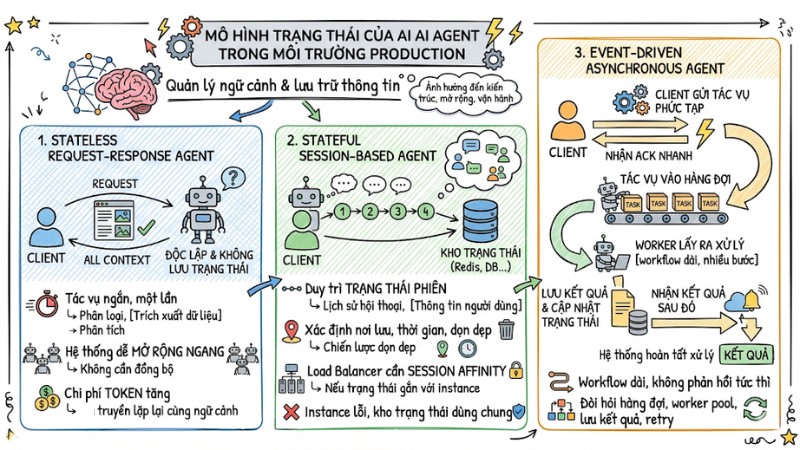
Các mô hình trạng thái của AI Agent trong môi trường Production
Quy trình triển khai Deploy AI Agent
Dưới đây là năm bước cơ bản để đóng gói, bảo mật và vận hành AI Agent một cách ổn định trong môi trường thực tế:
- Containerization: Đóng gói Agent vào Docker để chuẩn hóa môi trường thực thi giữa development, staging và production.
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["gunicorn", "-w", "4", "-k", "uvicorn.workers.UvicornWorker", "main:app"]
- Security: Không hard‑code API key trong code, lưu trữ secret trong dịch vụ như AWS Secrets Manager hoặc inject qua biến môi trường được quản lý an toàn.
- Health Check: Tạo endpoint
/healthđể hệ thống giám sát có thể kiểm tra trạng thái hoạt động của Agent.
@app.get("/health")
def health(): return {"status": "ok"}
- Scaling: Thiết lập ngưỡng CPU hoặc memory, ví dụ khoảng 70%, để kích hoạt cơ chế auto‑scaling khi tải tăng cao.
- Logging: Ghi log dưới dạng JSON có cấu trúc để các hệ thống như Datadog hoặc ELK dễ dàng phân tích và truy vết luồng suy luận của Agent khi cần debug.
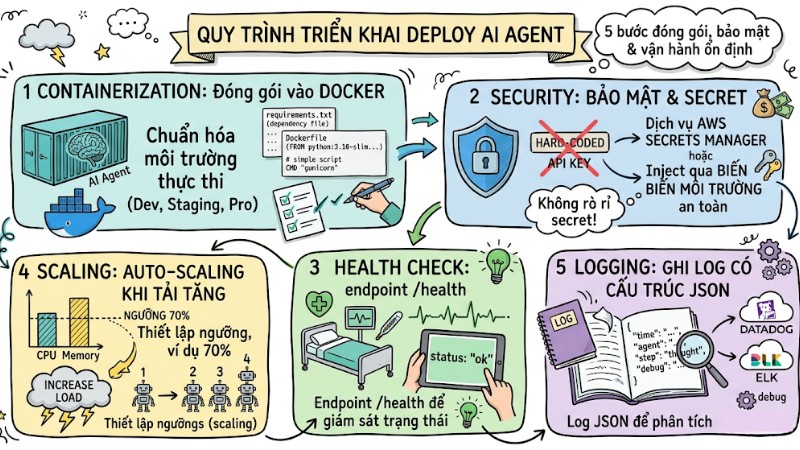
Quy trình triển khai Deploy AI Agent
Chiến lược vận hành và tối ưu chi phí cho AI Agent
Để vận hành AI Agent bền vững trong môi trường production, bạn cần tối ưu đồng thời chi phí token, hạ tầng và hiệu năng hệ thống:
- Token Optimization: Thiết lập
max_tokensở mức phù hợp từng loại tác vụ, áp dụng mô hình phân tầng như dùng model chi phí thấp cho phân loại hoặc routing và chỉ gọi model cao cấp cho các yêu cầu suy luận phức tạp. - Caching: Tích hợp Redis hoặc cache tương đương để lưu kết quả các prompt lặp lại hoặc tương tự, từ đó giảm đáng kể số lần gọi API LLM cho câu hỏi thường gặp và cải thiện độ trễ.
- IaC (Infrastructure as Code): Sử dụng Terraform để mô tả và tự động hóa hạ tầng bằng mã, giúp việc tạo mới, thay đổi và tái tạo môi trường production diễn ra nhất quán, nhanh và ít lỗi hơn.
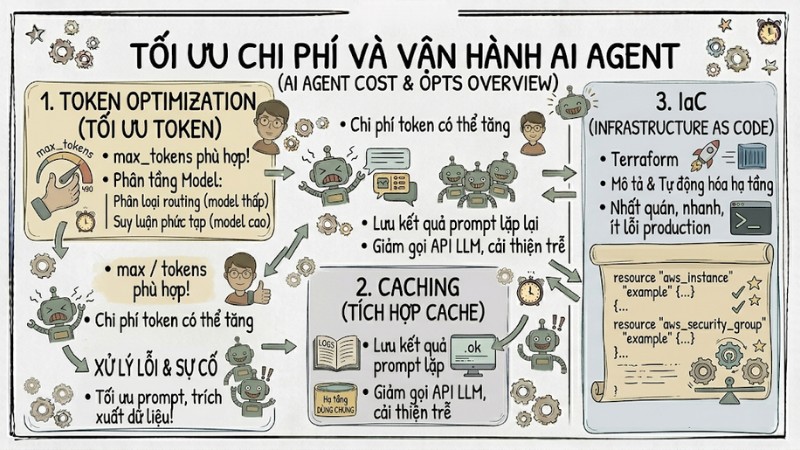
Chiến lược vận hành và tối ưu chi phí cho AI Agent
Checklist trước khi đưa lên Production
Trước khi đưa AI Agent vào môi trường production, bạn có thể sử dụng bảng kiểm tra sau để bảo đảm hệ thống đã đáp ứng đầy đủ các yêu cầu cần thiết:
| Hạng mục | Trạng thái |
|---|---|
| Bảo mật | API key đã được bảo vệ thông qua Secret Manager hoặc cơ chế quản lý secret tương đương. |
| Giám sát | Hệ thống đã cấu hình logging dưới dạng JSON có cấu trúc để phục vụ phân tích và truy vết. |
| Khả năng phục hồi | Đã thiết lập health check và cơ chế tự khởi động lại dịch vụ khi gặp lỗi hoặc mất kết nối. |
| Chi phí | Đã cấu hình giới hạn token và triển khai cơ chế caching để kiểm soát chi phí gọi LLM. |
| Mở rộng | Đã bật auto‑scaling dựa trên ngưỡng sử dụng CPU hoặc tài nguyên tương đương để đáp ứng tải tăng. |
Kiểm thử và đánh giá chất lượng AI Agent
Kiểm thử và đánh giá chất lượng giúp AI Agent vận hành ổn định, giảm lỗi và duy trì hiệu quả trong môi trường production. Bên cạnh health check và scaling, hệ thống cần các lớp kiểm thử logic và cơ chế đánh giá liên tục để kiểm soát chất lượng đầu ra.
Unit và Integration tests cho workflow Agent
Unit test kiểm tra từng thành phần nhỏ trong workflow Agent như hàm xử lý dữ liệu, logic chọn tool hoặc lớp chuẩn hóa đầu ra. Mục tiêu là đảm bảo mỗi khối logic hoạt động đúng với các trường hợp bình thường và biên, không phụ thuộc vào LLM.
Integration test kiểm tra toàn bộ luồng từ request vào đến phản hồi, bao gồm gọi LLM (có thể dùng mock), truy cập kho nhớ, gọi tool và xử lý lỗi. Các bài test này giúp phát hiện lỗi do tích hợp sai, cấu hình thiếu hoặc thay đổi hạ tầng gây ra hành vi ngoài ý muốn.
Offline evals với bộ test scenario
Offline evals sử dụng bộ kịch bản được chuẩn bị sẵn, mỗi kịch bản gồm prompt đầu vào và tiêu chí đánh giá hoặc kết quả mong đợi. Hệ thống chạy Agent trên bộ test này, đo lường các chỉ số như tỉ lệ hoàn thành nhiệm vụ, độ chính xác hoặc điểm số do người gán nhãn.
Các đánh giá này thường được thực hiện trước khi triển khai phiên bản mới lên production hoặc khi thay đổi model, prompt, workflow. Kết quả giúp so sánh các cấu hình khác nhau và chọn biến thể đạt chất lượng tốt nhất trước khi cho phép phục vụ lưu lượng thật.
Online evals và A/B test trong production
Online evals sử dụng lưu lượng thật trong production để đo chất lượng Agent dựa trên hành vi người dùng và kết quả thực tế. Hệ thống có thể triển khai song song hai phiên bản Agent (hoặc model/prompt) và phân chia một phần traffic cho mỗi phiên bản theo tỉ lệ định sẵn.
Các chỉ số thu thập bao gồm tỉ lệ nhiệm vụ được người dùng chấp nhận, tỉ lệ phải sửa tay, thời gian hoàn thành và số bước tool call. Dựa trên kết quả A/B test, nhóm vận hành có thể chọn phiên bản hoạt động tốt hơn và loại bỏ cấu hình kém hiệu quả, đồng thời tiếp tục lặp lại chu trình cải tiến chất lượng.
Giải đáp thắc mắc thường gặp
Stateless hay Stateful tốt hơn cho AI Agent
Trong môi trường production nên ưu tiên kiến trúc stateless, lưu toàn bộ trạng thái phiên làm việc và lịch sử hội thoại ra Redis, Postgres hoặc bộ nhớ ngoài để dễ scale ngang nhiều instance mà không phụ thuộc máy cụ thể.
Làm thế nào để quan sát quá trình suy luận của Agent?
Bạn có thể dùng các nền tảng quan sát chuyên biệt như LangSmith hoặc Pydantic Logfire để bật tracing, theo dõi từng lần gọi LLM, tool và bước suy luận trong một phiên Agent. Điều này giúp xem lại đường đi của request và hiểu vì sao Agent chọn hành động cụ thể.
Làm sao để chống lạm dụng API?
Nên cấu hình rate limiting ở tầng API Gateway hoặc reverse proxy, giới hạn số request theo người dùng, IP hoặc API key trong từng khoảng thời gian. Hãy để mọi request đi qua lớp gateway này thay vì cho người dùng gọi trực tiếp vào Agent runtime.
Xem thêm:
- Hướng dẫn quản lý AI agent permission để đảm bảo an toàn hệ thống
- Hướng dẫn triển khai hệ thống OpenClaw Multi-Agent chi tiết
- Vận hành AI Agent Team: Quản trị rủi ro cho lực lượng lao động số
Deploy AI Agent hiệu quả đòi hỏi kết hợp đúng kiến trúc nhiều lớp, lựa chọn hạ tầng phù hợp, mô hình hóa trạng thái rõ ràng và áp dụng các bước triển khai chuẩn hóa kèm chiến lược tối ưu chi phí. Khi hoàn thiện checklist production, bổ sung lớp quan sát và kiểm thử liên tục, bạn có thể vận hành AI Agent ở môi trường thực tế với độ tin cậy cao và khả năng mở rộng phù hợp nhu cầu hệ thống.
Thẻ