LLM (Large Language Model) là gì? Tìm hiểu về mô hình ngôn ngữ lớn

LLM (Large Language Model) là gì? Tìm hiểu về mô hình ngôn ngữ lớn
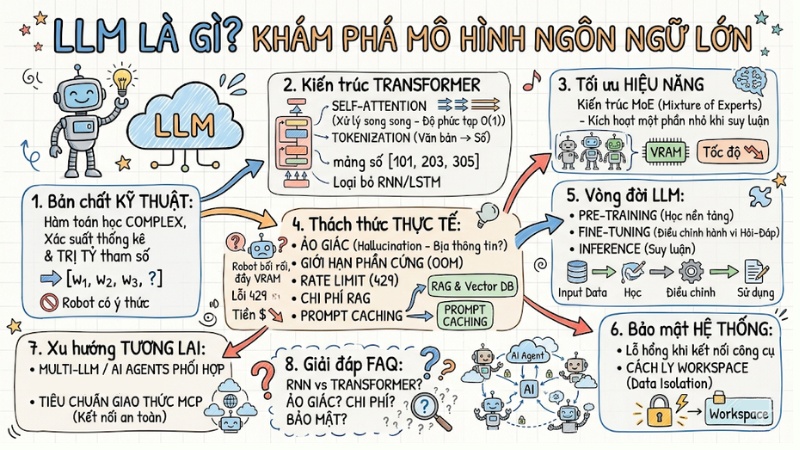
Đằng sau những câu trả lời tưởng như có tư duy, LLM thực chất chỉ là một mô hình xác suất thống kê ở quy mô khổng lồ, hoạt động dựa trên cơ chế dự đoán token tiếp theo thay vì bất kỳ dạng “ý thức” nào. Bài viết này tập trung giải thích LLM dưới góc nhìn Computer Science: Cách chuỗi số nguyên đi qua hàng tỷ tham số trong kiến trúc Transformer, các giới hạn bộ nhớ (VRAM) khi triển khai và lý do xử lý song song giúp Transformer vượt trội hơn các mô hình học máy truyền thống.
Những điểm chính
- Bản chất kỹ thuật của LLM: Hiểu đúng LLM là một hàm toán học phức tạp dựa trên xác suất thống kê và kiến trúc Transformer, thay vì một thực thể có ý thức hay tư duy logic như con người.
- Cơ chế vận hành: Nắm vững vai trò của Tokenization (chuyển đổi văn bản thành số) và kiến trúc Transformer với cơ chế Self-Attention (xử lý song song, độ phức tạp O(1)) đã loại bỏ nút thắt cổ chai của các mô hình RNN/LSTM truyền thống.
- Tối ưu hiệu năng: Hiểu về kiến trúc MoE (Mixture of Experts) – giải pháp cho phép mô hình có hàng chục tỷ tham số nhưng chỉ kích hoạt một phần nhỏ khi suy luận, giúp tối ưu tài nguyên VRAM và tốc độ.
- Vòng đời LLM: Nắm bắt sự khác biệt giữa Pre-training (học nền tảng), Fine-tuning (điều chỉnh hành vi/định dạng) và Inference (suy luận thực tế trong Production).
- Thách thức thực tế: Đối mặt với các bài toán về ảo giác (Hallucination), giới hạn phần cứng (OOM), lỗi Rate Limit (429) và chi phí vận hành thông qua các kỹ thuật phòng thủ như RAG và Prompt Caching.
- Bảo mật hệ thống: Nhận diện các lỗ hổng chí mạng khi kết nối LLM với công cụ nội bộ và yêu cầu bắt buộc về cách ly workspace.
- Xu hướng tương lai: Chuyển dịch từ Chatbot đơn lẻ sang Multi-LLM/AI Agents phối hợp bất đồng bộ, sử dụng tiêu chuẩn giao thức MCP để kết nối an toàn với hạ tầng doanh nghiệp.
- Giải đáp FAQ: Làm rõ các khái niệm về ảo giác, sự khác biệt giữa RNN/Transformer, lộ trình tối ưu chi phí và tầm quan trọng của bảo mật trong triển khai AI chuyên nghiệp.
Bản chất của LLM: Khái niệm và mô hình tư duy lập trình
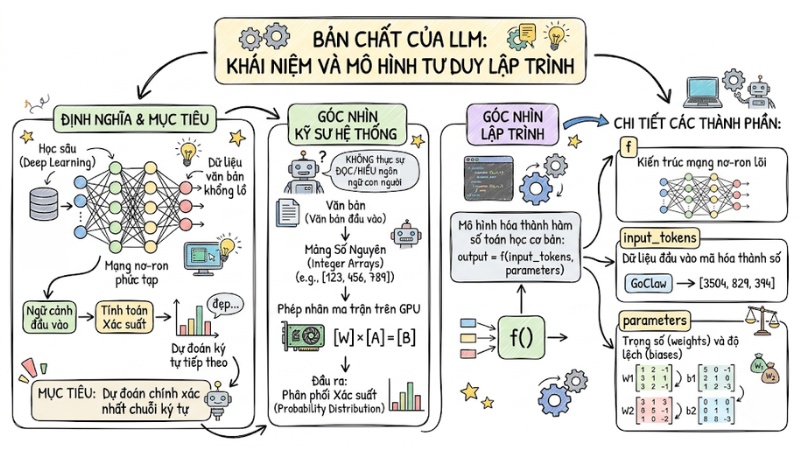
Large Language Models (LLM - Mô hình ngôn ngữ lớn) là các mô hình học sâu (Deep Learning) mang kiến trúc mạng nơ-ron phức tạp, được huấn luyện trên lượng dữ liệu văn bản khổng lồ. Mục tiêu cốt lõi của hệ thống này là tính toán xác suất và dự đoán chuỗi ký tự tiếp theo một cách chính xác nhất dựa trên ngữ cảnh đầu vào.
Dưới góc nhìn của kỹ sư hệ thống, các mô hình ngôn ngữ không thực sự "đọc" hay "hiểu" ngôn ngữ con người. Chúng nhận vào các mảng số nguyên, thực hiện các phép nhân ma trận trên GPU và trả về một phân phối xác suất.
Dưới góc độ lập trình, ta có thể mô hình hóa Large Language Models thành một hàm số toán học cơ bản:
output = f(input_tokens, parameters)
Trong đó:
flà hàm đại diện cho kiến trúc mạng nơ-ron lõi.input_tokenslà dữ liệu đầu vào đã được mã hóa thành số.parameterslà các trọng số (weights) và độ lệch (biases).
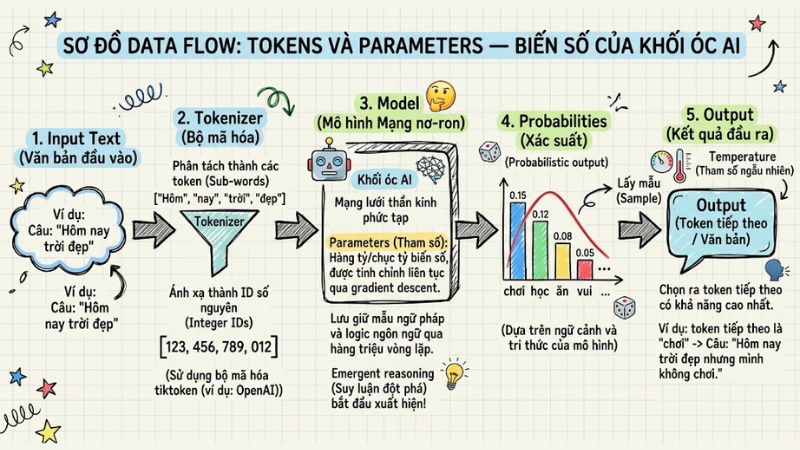
Tokens và Parameters: Biến số của khối óc AI
Các "tham số" (Parameters) chính là biến số cấu thành khối óc của mạng nơ-ron. Chúng được tinh chỉnh liên tục qua hàng triệu vòng lặp gradient descent để lưu giữ các mẫu (patterns) ngữ pháp và logic ngôn ngữ. Hiện tượng suy luận đột phá (Emergent reasoning) bắt đầu xuất hiện khi số lượng tham số vượt ngưỡng hàng tỷ hoặc chục tỷ.
Tuy nhiên, máy tính không thể đẩy trực tiếp chuỗi văn bản (string) vào các tham số này. Đây là lúc thuật toán Byte-pair encoding (BPE) tham gia vào quá trình Tokenization.
Ví dụ: Khi sử dụng bộ mã hóa tiktoken (bộ mã hóa phổ biến của OpenAI), từ "GoClaw" có thể không được xử lý nguyên khối, mà bị chia tách thành các sub-words (token) như ["Go", "Cl", "aw"]. Sau đó, chúng được ánh xạ thành mảng ID số nguyên như [3504, 829, 394].
Hệ thống xử lý mảng này và trả về Probabilistic output (phân phối xác suất) cho toàn bộ bộ từ vựng. Thuật toán cuối cùng sẽ lấy mẫu (sample) để chọn ra token tiếp theo có khả năng cao nhất, bị ảnh hưởng bởi tham số ngẫu nhiên (temperature).
Tokens và Parameters: Biến số của khối óc AI
Mổ xẻ kiến trúc LLM: Sự thống trị của Transformer
Bước ngoặt của AI hiện đại, định hình gần như toàn bộ các hệ thống LLM ngày nay, bắt đầu từ paper “Attention Is All You Need” (2017) của Google, với Transformer ở vị trí trung tâm của cuộc cách mạng này.
Trung tâm của hệ thống: Cơ chế Self-Attention
Trước kỷ nguyên Transformer, các kiến trúc Recurrent Neural Network (RNN) hay LSTM xử lý dữ liệu một cách tuần tự (từng từ một). Điều này tạo ra độ phức tạp thời gian O(N) đối với khâu xử lý ngữ cảnh, khiến quá trình huấn luyện diễn ra cực kỳ chậm, không thể khai thác tối đa sức mạnh tính toán song song, đồng thời sinh ra lỗi quên ngữ cảnh dài.
Transformer giải quyết bài toán này bằng Self-attention mechanism. Nó cho phép xử lý toàn bộ chuỗi token song song trên GPU với độ phức tạp O(1) cho thao tác truyền tải tuần tự (mặc dù phép nhân ma trận attention có chi phí O(N²)).
Self-attention hoạt động bằng cách ánh xạ từng token vào không gian vector thông qua 3 ma trận trọng số: Query (Q), Key (K) và Value (V). Dưới đây là pseudo-code mô phỏng toán học của cơ chế này:
import numpy as np
def scaled_dot_product_attention(Q, K, V, d_k): # Tính dot product giữa Query và Key để tìm độ tương quan (Scores) matmul_qk = np.dot(Q, K.T)
# Scale kết quả để tránh gradient quá lớn ảnh hưởng đến softmax
scaled_attention_logits = matmul_qk / np.sqrt(d_k)
# Áp dụng Softmax để chuyển đổi thành phân phối xác suất (0 đến 1)
attention_weights = softmax(scaled_attention_logits)
# Nhân trọng số attention với Value để lấy thông tin ngữ cảnh cuối cùng
output = np.dot(attention_weights, V)
return output
Bảng so sánh RNN vs Transformer trong xử lý ngôn ngữ:
| Tiêu chí | Recurrent Neural Network (RNN) | Transformer Architecture |
|---|---|---|
| Cách xử lý dữ liệu | Tuần tự (Sequential) - Từng token một | Song song (Parallel) - Toàn bộ chuỗi cùng lúc |
| Bảo lưu ngữ cảnh dài | Kém (Hay bị Vanishing Gradient) | Rất tốt (Nhờ Self-Attention trực tiếp) |
| Tối ưu hóa GPU | Thấp (Bị nghẽn cổ chai vòng lặp) | Cực cao (Tính toán ma trận đồng thời) |
| Tốc độ huấn luyện | Rất chậm | Cực nhanh ở quy mô lớn |
Sự tiến hóa: Mixture of Experts (MoE)
Mặc dù mạnh mẽ, hạn chế lớn nhất của kiến trúc Transformer dày đặc là (chi phí tính toán khi suy luận khổng lồ, bởi mọi tham số đều phải kích hoạt cho mỗi một request đi qua.
Để giải quyết vấn đề VRAM và tốc độ, kiến trúc MoE (Mixture of Experts) được ứng dụng trên các model hiện đại như Mixtral hay DeepSeek. Thay vì dùng một mạng lưới khổng lồ, MoE chia nhỏ mô hình thành nhiều nhánh "chuyên gia".
Một cổng định tuyến (Router) sẽ phân tích token đầu vào và chỉ đẩy luồng dữ liệu tới 1-2 chuyên gia phù hợp nhất. Nhờ đó, một mô hình cấu trúc 56 tỷ tham số có thể chỉ cần kích hoạt 14 tỷ tham số trong quá trình chạy (inference), tối ưu đáng kể phần cứng.
Vòng đời của một LLM: Từ dữ liệu thô đến Production
Để tạo ra một công cụ AI có khả năng lập trình, làm toán và tóm tắt văn bản một cách logic, hệ thống không chỉ được "code" ra, mà phải trải qua một pipeline MLOps với 3 giai đoạn cốt lõi:
- Pre-training (Huấn luyện tiền đề): Giai đoạn "nhồi" khối lượng dữ liệu khổng lồ (hàng nghìn tỷ tokens) từ Internet để mô hình học cấu trúc ngôn ngữ và kiến thức nền thông qua cơ chế tự học giám sát (dự đoán token tiếp theo).
- Fine-tuning (Tinh chỉnh): Giai đoạn ép mô hình tuân thủ định dạng hỏi-đáp. Sử dụng kỹ thuật SFT (Supervised Fine-Tuning) và RLHF (Reinforcement Learning from Human Feedback) để điều chỉnh hành vi AI cho phù hợp với đạo đức và tác vụ cụ thể.
- Inference (Suy luận): Giai đoạn đưa mô hình đã đóng gói vào môi trường Production để phục vụ request thực tế qua API hoặc hệ thống local.
Vòng đời của một LLM: Từ dữ liệu thô đến Production
Pre-training (Huấn luyện tiền đề)
Tại giai đoạn Pre-training, chi phí phần cứng là một bài toán vật lý khắc nghiệt. Việc tối ưu hóa hàm mục tiêu (thường là Cross-Entropy Loss) trên hàng trăm tỷ tham số tiêu tốn sức mạnh của hàng nghìn GPU H100 chạy liên tục trong nhiều tháng. Đây là nguyên nhân vì sao phần lớn doanh nghiệp sẽ chỉ tiêu thụ API hoặc tự host các mô hình mã nguồn mở thay vì train model từ số 0.
Fine-tuning (Tinh chỉnh)
Giai đoạn Fine-tuning là nơi các kỹ sư thực sự can thiệp để mô hình có thể phục vụ business logic. Một base model sau Pre-training có thể chỉ biết nối tiếp câu theo thói quen web, nhưng sau quá trình tinh chỉnh, nó trở thành một trợ lý ảo biết tuân theo định dạng đầu ra (ví dụ: JSON, Markdown).
Inference (Suy luận)
Cuối cùng, môi trường Inference là chiến trường thực sự của Developer. Bài toán ở đây không còn là việc model thông minh đến đâu, mà là tối ưu hóa Latency (độ trễ), Throughput (thông lượng) và quản lý Context window một cách khắt khe để phục vụ hàng vạn user đồng thời mà không sập hệ thống.
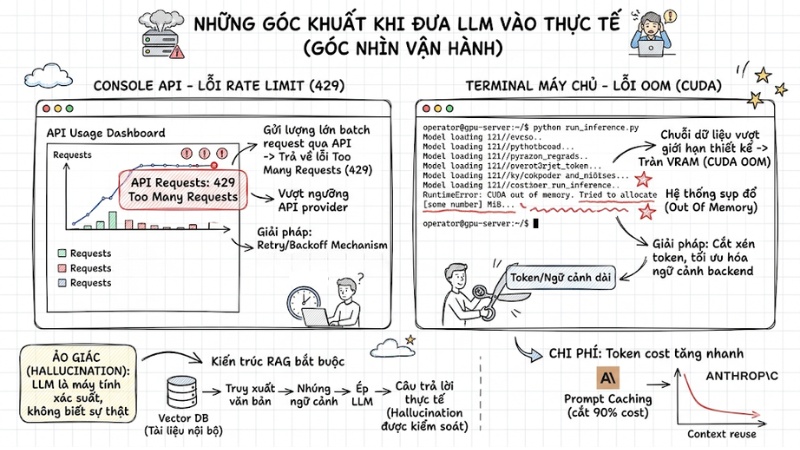
Những góc khuất khi đưa LLM vào thực tế (Góc nhìn vận hành)
Một mô hình chạy xuất sắc trong môi trường Lab chưa chắc đã sống sót khi đưa lên Production. Kỹ sư hệ thống thường xuyên phải đối mặt với các giới hạn về hạ tầng và bảo mật. Cụ thể như:
- Ảo giác (AI Hallucination): Bản chất LLM là máy tính xác suất, nó không có khái niệm về "sự thật", dẫn đến tình trạng AI tự tin bịa đặt thông tin. Để triển khai thực tế, kiến trúc RAG là yêu cầu bắt buộc. Hệ thống RAG sử dụng Vector DB để truy xuất trực tiếp các tài liệu nội bộ chính xác nhất, sau đó nhúng vào ngữ cảnh để "ép" LLM chỉ được tổng hợp câu trả lời từ nguồn này.
- Lỗi Rate Limit và Out of Memory (OOM): Khi gửi chuỗi dữ liệu vượt quá giới hạn thiết kế, hệ thống sẽ trả về lỗi Out of Memory (tràn VRAM). Ngược lại, nếu gửi lượng lớn batch request qua API của nhà cung cấp, lỗi 429 Too Many Requests sẽ xảy ra. Kỹ sư bắt buộc phải thiết lập cơ chế retry/backoff (thử lại với thời gian trễ tăng dần) và cắt xén token ở backend.
- Chi phí: Giá mỗi 1 triệu tokens (Input/Output cost) có thể vượt ngân sách rất nhanh trong các hệ thống RAG xử lý văn bản dài. Tích hợp cơ chế Prompt Caching của các nhà cung cấp như Anthropic có thể cắt giảm chi phí đến 90% nhờ tái sử dụng các chunk ngữ cảnh tĩnh.
Những góc khuất khi đưa LLM vào thực tế
#Lỗi Rate Limit (API Provider)
HTTP/1.1 429 Too Many Requests
Content-Type: application/json
{
"error": {
"message": "Rate limit reached for requests per minute (RPM).",
"type": "requests",
"code": "rate_limit_exceeded"
}
}
#Lỗi VRAM nội bộ (Local Deployment)
RuntimeError: CUDA out of memory. Tried to allocate 2.50 GiB.
GPU 0 has a total capacity of 24.00 GiB of which 1.12 GiB is free.
Process requires 25.30 GiB. Limit context window or apply quantization.
Lưu ý bảo mật:
Khi thiết lập LLM có khả năng gọi API bên ngoài hoặc tương tác với cơ sở dữ liệu, tin tặc có thể khai thác lỗ hổng Prompt Injection bằng cách chèn lệnh ẩn vào input để đánh cắp System Prompt nội bộ.
Nguy hiểm hơn, nếu model được kết nối không cách ly, nó có thể bị thao túng để thực hiện các cuộc tấn công SSRF (Server-Side Request Forgery), quét và truy xuất dữ liệu từ mạng nội bộ của doanh nghiệp. Việc áp dụng các lớp phân quyền chặt chẽ là điều kiện tiên quyết.
Tương lai của LLM: Kỷ nguyên AI Agents và Multi-LLM
Kỷ nguyên AI Agents
Chúng ta đang chứng kiến sự dịch chuyển mạnh mẽ từ các hệ thống chatbot tĩnh sang kỷ nguyên Agentic Workflow. Các thế hệ Reasoning models (mô hình suy luận) mới nhất đã cho phép AI sở hữu năng lực tư duy chuỗi trực tiếp trong kiến trúc.
Thay vì trả lời ngay lập tức, chúng sinh ra các token ẩn để lên kế hoạch, phân tích lỗi và tự sửa chữa trước khi trả về kết quả cuối cùng, giải quyết triệt để các bài toán code và logic cấp cao.
Kỷ nguyên Multi-LLM
Bên cạnh đó, việc tích hợp công cụ không còn mang tính thủ công nhờ sự ra đời của giao thức MCP. MCP cung cấp một tiêu chuẩn thống nhất giúp các mô hình kết nối an toàn với máy chủ local, IDE, hoặc cơ sở dữ liệu mà không cần phải viết lại mã tích hợp cho từng nhà cung cấp.
Điều này định hình tương lai của Orchestration (điều phối): Một nhóm các AI Agents chuyên biệt làm việc bất đồng bộ (Multi-LLM). Trong quy trình đó, Agent A có trách nhiệm query dữ liệu, Agent B viết code xử lý, và Agent C kiểm tra bảo mật độc lập.
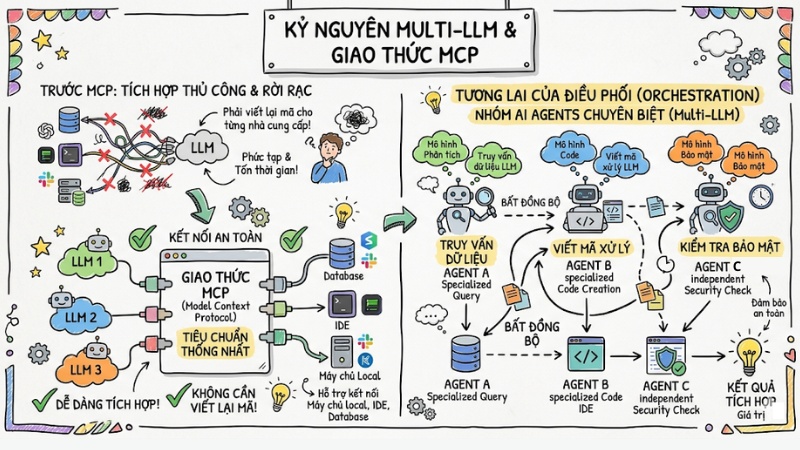
Tương lai của LLM: Kỷ nguyên AI Agents và Multi-LLM
Câu hỏi thường gặp về LLM
LLM là gì?
Large Language Model (LLM) là mô hình học sâu (deep learning) được huấn luyện trên tập dữ liệu khổng lồ để dự đoán token tiếp theo trong chuỗi. Bản chất của LLM không phải là trí tuệ nhân tạo có ý thức, mà là một hệ thống toán học xác suất thống kê phức tạp.
Sự khác biệt giữa RNN và Transformer là gì?
RNN xử lý dữ liệu tuần tự, gây nghẽn cổ chai và khó ghi nhớ ngữ cảnh dài. Ngược lại, Transformer sử dụng cơ chế self-attention để xử lý toàn bộ chuỗi dữ liệu song song trên GPU, giúp tối ưu hiệu năng đào tạo và nắm bắt ngữ cảnh vượt trội.
Tại sao LLM lại gặp tình trạng "ảo giác" (hallucinations)?
Vì LLM hoạt động dựa trên xác suất dự đoán từ ngữ tiếp theo, nó ưu tiên sự trôi chảy của văn bản hơn là tính xác thực. Nếu dữ liệu huấn luyện thiếu sót hoặc đầu vào gây nhiễu, mô hình có thể tự tin tạo ra các thông tin sai lệch.
Làm thế nào để giảm chi phí sử dụng API của các LLM?
Bạn có thể tối ưu chi phí bằng cách sử dụng kỹ thuật Prompt Caching của các nhà cung cấp, hoặc triển khai kiến trúc RAG để tận dụng dữ liệu nội bộ thay vì yêu cầu mô hình nhớ mọi thông tin trong prompt.
Sự khác biệt giữa Pre-training và Fine-tuning là gì?
Pre-training là giai đoạn dạy mô hình hiểu cấu trúc ngôn ngữ cơ bản từ dữ liệu thô khổng lồ. Fine-tuning là bước tinh chỉnh mô hình đã được huấn luyện trên một tập dữ liệu chuyên biệt để nó thực hiện chính xác các tác vụ nghiệp vụ cụ thể.
Tại sao bảo mật lại quan trọng khi triển khai AI Agent?
AI Agent thường truy cập vào hệ thống nội bộ qua API hoặc công cụ (tools). Nếu không có các lớp bảo mật như chống prompt injection, SSRF, hay cách ly workspace (multi-tenant), kẻ tấn công có thể lợi dụng agent để chiếm quyền điều khiển hệ thống hoặc rò rỉ dữ liệu nhạy cảm.
Xem thêm:
- Multi-agent vs Single-agent: Cách lựa chọn kiến trúc AI tối ưu
- AI Agent vs Chatbot: Phân biệt và lựa chọn công cụ phù hợp
- Cách chọn nền tảng AI Agent tối ưu cho doanh nghiệp 2026
Tóm lại, LLM hoàn toàn không phải là một "thực thể có tư duy", mà là đỉnh cao của sự kết hợp giữa kiến trúc Transformer mạnh mẽ và kỹ thuật xử lý xác suất quy mô lớn. Việc thấu hiểu bản chất kỹ thuật từ Tokenization, giới hạn Context Window đến cơ chế Self-attention giúp các kỹ sư làm chủ việc tích hợp hệ thống, tối ưu chi phí và tránh rủi ro bảo mật đáng tiếc.