MCP Server Best Practices: Optimizing Performance for AI Agents

MCP Server Best Practices is a collection of design and operational principles that help an MCP Server become a stable, discoverable, and optimized interface for AI Agents accessing external data and services. This article focuses on systematizing MCP Server Best Practices from tool design, transport selection, and security to testing and deployment so you can build production-ready MCP Servers.
Key Takeaways
- The Nature of MCP Server: An MCP Server is not just a typical API "wrapper" but an open communication standard that helps AI Agents securely connect to databases and internal enterprise systems.
- Causes of Failure: Identify common mistakes like designing an MCP Server exactly like a REST API, which leads to AI "hallucinations," incorrect tool calls, and wasted resources.
- Core Design Principles: Master fundamental principles such as: outcome-oriented design, flattening arguments, turning descriptions into context, and more.
- Deployment Strategies: Explore how to choose transmission protocols and secrets for optimizing context when handling massive datasets using pagination or asynchronous processing.
- Security Principles: Pocket vital security measures such as: applying the principle of least privilege, authenticating with OAuth 2.1, encrypting sensitive information, and sanitizing data before responding to the AI.
- Testing Workflow: Understand a comprehensive testing roadmap from Unit tests, Integration tests, and Contract testing to Load testing to ensure the MCP Server operates smoothly under the pressure of multiple parallel AI Agents.
- FAQ: Get answers to questions regarding the differences between Tools, Resources, and Prompts, essential performance metrics, and how to safely transition from REST APIs to MCP.
Overview of MCP Server and its Role in the AI Ecosystem
Model Context Protocol (MCP) is an open standard that allows AI applications to connect structurally to external systems like databases, internal services, or business tools through a client-server model. An MCP server is the service that implements this protocol and provides core capabilities such as tools, resources, and prompts so that the client or agent can discover and use them consistently.
In the modern AI ecosystem, the MCP server acts as a standardized communication layer between models and enterprise infrastructure, helping reduce the cost of building individual integrations and increasing the reusability of integration capabilities across various applications and agents. When designed and operated correctly, an MCP server supports agents in accessing data, executing tasks, and leveraging context from multiple sources while maintaining organizational constraints on security, performance, and control.
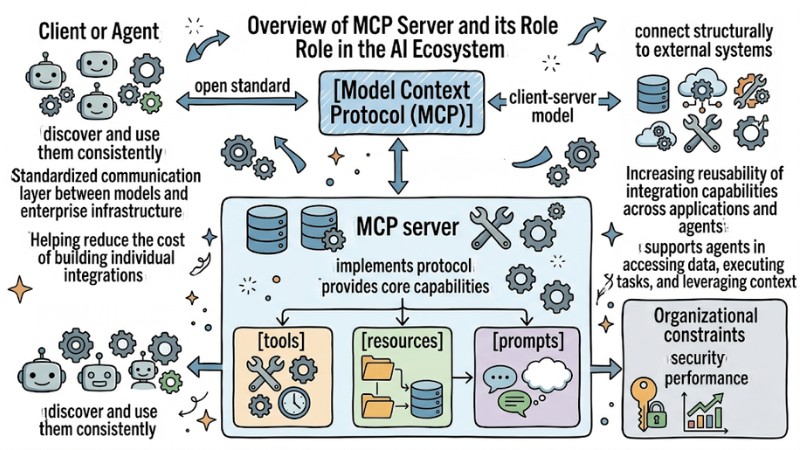
The MCP server acts as the normalization layer for communication between the model and the enterprise infrastructure
Why is your MCP Server disappointing when integrated into AI Agents?
Many MCP Servers fail to meet expectations when integrated into AI Agents because they are designed as REST API wrappers, simply converting each endpoint into a tool without reconsidering how the model uses the tool. REST APIs are primarily optimized for developers, whereas MCP is designed as a standardized interface for models and agents; if the toolset is too large or names and descriptions are unclear, the model is prone to choosing the wrong tool, passing incorrect parameters, or repeating unnecessary tool calling steps.
| Criteria | REST API (For Humans) | MCP Server (For AI Agents) |
|---|---|---|
| Discovery | Read documentation once | Schema included in every request |
| Interaction | Multi-step, flexible | Requires packaged tools (Outcomes) |
| Complexity | Allows many options | Causes errors, increases hallucination rates |
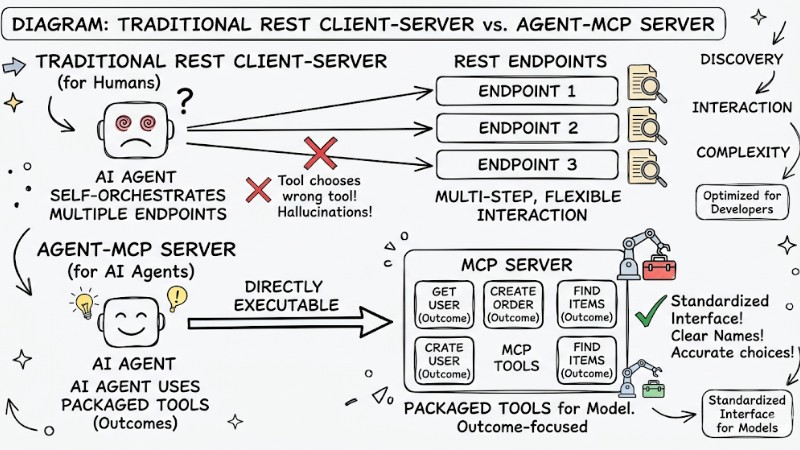
Comparing REST Client-Server and Agent-MCP Server
MCP Server Best Practices for Core Design Principles
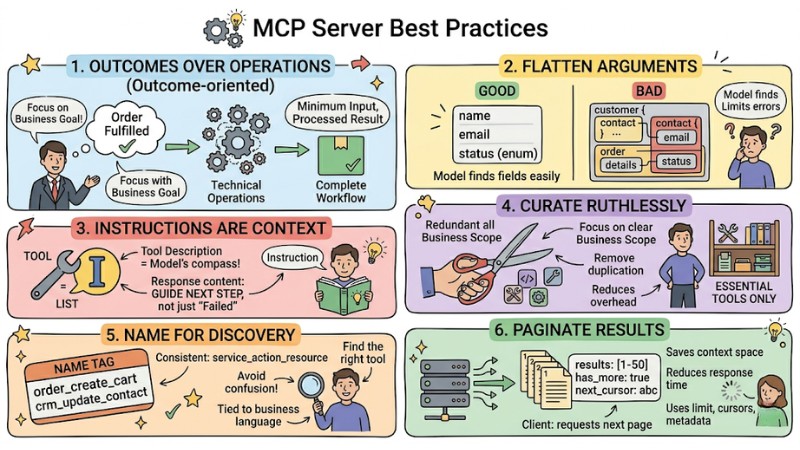
1. Outcomes over Operations (Outcome-oriented design)
Design tools according to final business outcomes instead of mapping individual technical operations. A tool should fully encompass a clear workflow, receive the minimum necessary input, and return results that have been aggregated or processed according to the task's needs. This approach reduces the number of tool calls required in an interaction session and minimizes the risk of the model getting stuck in a chain of minor activities.
2. Flatten Arguments
Parameter structures should use primitive data types and enum values instead of complex nested objects. Flattening arguments helps the model identify the fields to fill, limits serialization errors, and avoids issues when the client handles multi-layer JSON structures. Schema designers need to maintain a reasonable number of fields, use meaningful field names, and utilize data type constraints in JSON Schema to protect inputs.
// Optimization: Flat and explicit parameters
{
"name": "search_orders",
"inputSchema": {
"type": "object",
"properties": {
"email": { "type": "string" },
"status": { "type": "string", "enum": ["pending", "shipped", "delivered"] }
},
"required": ["email"]
}
}
3. Instructions are Context
Tool descriptions and parameter descriptions act as the primary context for the model to understand when to use the tool, the input requirements, and the expected result format. Descriptions need to present the purpose, limits, and brief examples of usage scenarios so the model can choose the tool appropriate to the user's request. Response content, including error messages, should be written in a way that provides additional instructions for the next step instead of just reporting a failure status.
4. Curate Ruthlessly
An MCP Server should focus on a clear business scope and only provide the minimum set of tools that fully meet the primary processes. Limiting the number of tools and removing duplicate or low-value tools reduces the overhead for the model's discovery and selection process. Tools should be organized by workflow or domain instead of by technical resource to make the request routing process clearer.
5. Name for Discovery
Tool names must clearly express the service, action, and related resource, helping the client and model infer function from the name alone. A consistent naming structure following a pattern like service_action_resource makes filtering and searching for tools simpler as the number of tools grows. Names should avoid confusing abbreviations, avoid generic words, and should be tied directly to the business language used in the target system.
6. Paginate Results
Tools that return lists of records or large datasets need to support pagination or a batch-return mechanism. Pagination design should include limit parameters, cursors, or offsets, along with metadata like has_more or next_cursor so the client can continue querying the next part of the data as needed. This approach saves context window space, reduces response time, and increases cost control for both the server and the client.
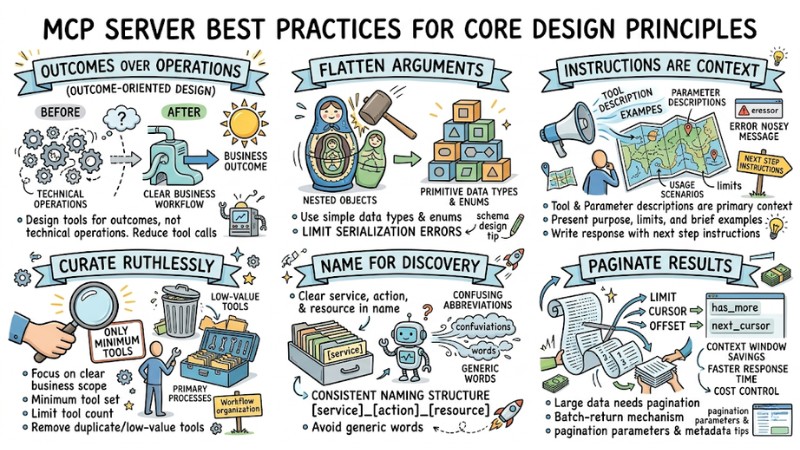
MCP Server Design Principles
Production-Ready MCP Implementation Techniques
1. Choosing a transport: stdio vs. HTTP/SSE
During the development and local testing phase, stdio transport is suitable for scenarios such as:
- Running the MCP server alongside desktop applications, IDEs, or CLIs.
- No requirement to serve multiple simultaneous clients over a network.
HTTP transport combined with SSE is appropriate for production environments requiring deployment on web infrastructure, load balancing, and integration with multiple clients. In this model, requests are sent via HTTP and responses are streamed via SSE, helping maintain stable connections, support multiple simultaneous sessions, and ensure compatibility with existing infrastructure like proxies or CDNs.
A typical deployment process involves using stdio in development environments to reduce operational costs and speed up the testing lifecycle. Once the service reaches stability, the team can deploy the MCP server via HTTP/SSE to serve multiple agents, support horizontal scalability, and manage security centrally.
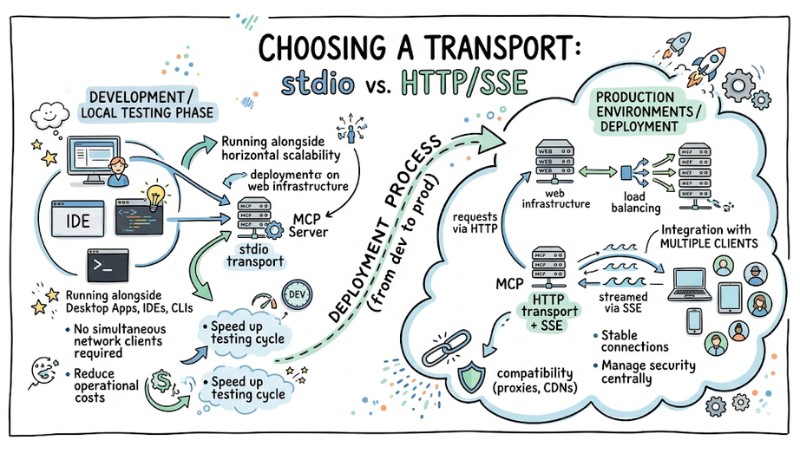
Comparison of stdio and HTTP/SSE transport
2. Server Architecture: Monolith MCP vs. Multiple Specialized MCP Servers
A monolith MCP server architecture centralizes all tools, resources, and prompts for multiple domains into a single process. This approach simplifies initial deployment but can cause difficulties when scaling, isolating access rights, or releasing separate versions for each business group.
A multiple specialized MCP server architecture divides servers by bounded context or service type, for example: a server for sales data, a server for monitoring systems, and a server for development tools. This organization supports independent lifecycle management, access control, and configuration for each domain, while allowing heavy-load components to be scaled independently.
3. Handling Large Data and Optimizing Context
For large datasets, an MCP server should combine pagination, streaming, and returning URIs pointing to resources instead of putting the entire payload into a single response. This approach reduces the context volume the agent must process in each call and limits token costs for both the client and the model.
Additional techniques include:
- Chunking long text into multiple parts and using external retrieval mechanisms to fetch exactly the necessary part.
- Designing specialized tools to summarize query results or datasets instead of returning full detailed content.
Thanks to these strategies, an MCP server can serve use cases with large data volumes while maintaining reasonable response times and model interpretability.
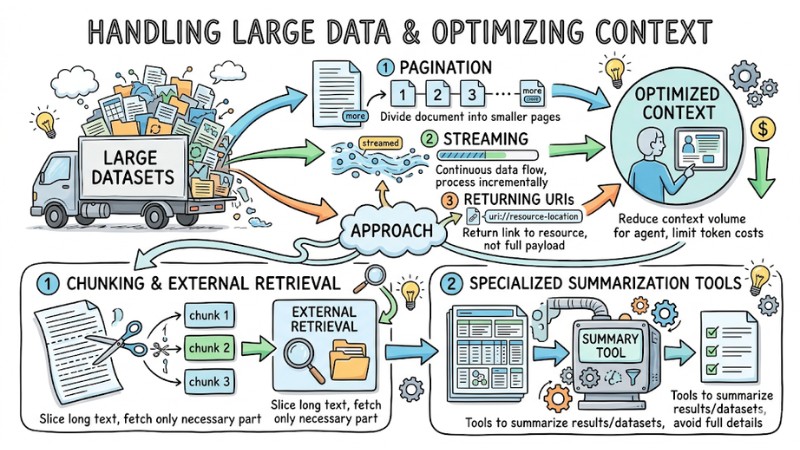
An MCP server combines paging, streaming, and returns a URI pointing to a resource
4. Non-blocking & Asynchronous processing
For tools performing I/O tasks such as calling external APIs, accessing databases, or processing files, using an asynchronous model helps avoid blocking the general processing flow. Every tool should be implemented as an async function so the server can handle multiple parallel requests and utilize resources more efficiently.
To increase reliability, the server needs to implement mechanisms for:
- Timeouts for I/O calls that exceed allowed thresholds.
- Cancellation to free up resources when the client cancels a request.
- Retries with exponential backoff for transient errors.
For heavy tasks like processing large data volumes or running secondary models, the server can push work into a queue or background worker and return a session ID or ticket. The client or agent can use another tool to check the status and retrieve the result when the process is complete, thereby keeping the primary MCP channel responsive.
# Example: Async tool structure
async def track_latest_order(email: str):
try:
# Business logic goes here
return "Processing result"
except Exception as e:
return "Agent-friendly error message"
Security and Privacy for MCP Servers
Security and privacy for an MCP Server must be designed as part of the overall architecture from the start, not as an afterthought.
1. Security Principles specific to MCP
An MCP Server must adhere to the principle of least privilege for each tool and resource, ensuring each tool only operates within the scope of truly necessary data and actions. The server should run with restricted system permissions, use signed binaries, and be deployed in controlled environments to reduce supply chain attack risks.
Network connections and data transmitted via MCP should be encrypted according to current standards, and egress control should be implemented via proxies or application firewalls to limit external destinations. All privilege escalation events, configuration changes, and access to critical resources must be logged with a request identifier for auditing purposes.
2. Authentication with OAuth 2.1 for HTTP transport
For MCP Servers using HTTP as transport, the authentication mechanism should be based on OAuth 2.1 with an authorization server separated from the resource server. When serving end-users, the Authorization Code flow combined with PKCE helps minimize the risk of authorization code leakage and protects client-side applications.
In server-to-server contexts, the client credentials flow is suitable for background tasks or system integration, with tokens issued to a technical identity with a clear scope. The system needs to manage refresh token lifecycles carefully, limit lifetimes, apply the minimum necessary scope, and avoid direct passthrough of user tokens to downstream services.
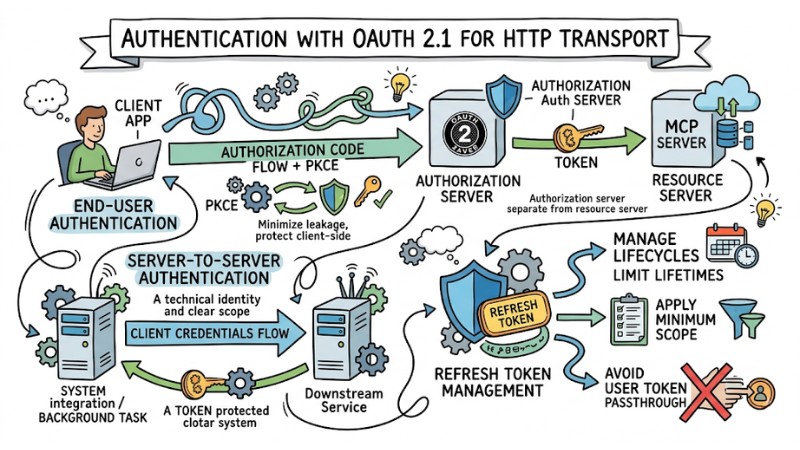
Authentication with OAuth 2.1 for HTTP transport
3. Managing secrets and session IDs
An MCP Server should not return any secrets, access keys, or sensitive tokens in tool output, including in error messages. All secrets must be stored in specialized secret vaults, have periodic rotation mechanisms, and restricted usage scopes.
When using session IDs to link context or state, the system needs to generate unpredictable values, for example based on UUIDs or secure random number generators, and absolutely never use the session as the primary authentication mechanism. Sessions should be bound to the client or origin, have a limited lifetime, and be invalidated upon detection of abnormal behavior.
4. Validation & sanitization of input/output
Every input from the client or agent needs to be checked and validated according to JSON Schema or business rules before being used in the logic layer. This includes checking data types, allowed values, lengths, and format constraints to prevent errors and abuse of the MCP interface.
For output, the system needs to apply data sanitization steps if unwanted content might appear, such as embedded code, links to untrusted domains, or sensitive data. In scenarios requiring compliance with specific personal data regulations, gateways or middleware can perform detection and anonymization of PII/PHI before responding to the client.
5. Security Logging: Hiding sensitive data, complying with regulations
An MCP Server should use structured logs, including information about the tool, time, request identifier, and general result, but not directly record secrets or full personal data. Fields containing PII, PHI, or financial data need to be masked, hashed, or removed from logs according to organizational security policies.
The logging system needs to support data filtering and sanitization rules, for example using sanitizer modules or regex to remove sensitive information in tool responses before logging. Additionally, security logs should be stored in centralized systems with access control, defined retention times, and query support for auditing or incident investigation.
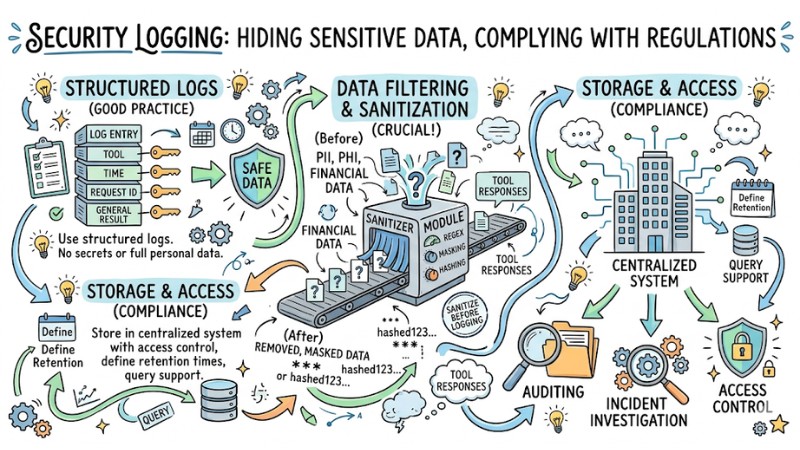
Secure logging to hide sensitive data on MCP Server
Testing and Operational Workflows for MCP Servers
1. Unit tests for business logic behind tools
Unit tests focus on testing the core functions and classes behind the tool without depending on MCP transport or server initialization processes. These tests ensure that the business logic correctly handles input data, returns accurate results, and fully handles edge cases.
To be effective, unit tests should use separate sandbox data or fixtures, avoiding access to external resources like real HTTP services or production databases. Mocking and stubbing libraries can be used to replace external dependencies, helping the test suite run fast and stably in the CI pipeline.
2. Integration tests for end-to-end MCP flows
Integration tests verify the coordination between the MCP Server layer, business logic, data layer, and supporting services. These tests typically start the server in test mode and call tools through an MCP client just like a real client.
The goal of integration testing is to ensure that the complete request-response flow works correctly, including serialization, validation, and error handling. The test suite should cover primary scenarios such as success flows, incorrect parameter input cases, and situations where the backend returns an error to detect integration-related issues early.
3. Contract testing with JSON-Schema and MCP specifications
Contract testing checks the compliance of the MCP Server against the declared JSON-Schema and MCP protocol specifications. These tests ensure that tool input and output always match the published schema, preventing the client from breaking when changes occur.
In practice, contract testing can use test suites based on mock clients or contract frameworks like Pact to confirm data structures and tool discovery capabilities. When the server is updated, the pipeline needs to rerun the entire contract test to protect compatibility with previously integrated agents.
4. Load & stress testing under multi-agent parallel scenarios
Load testing simulates a large number of agents connecting and calling tools in parallel to measure latency, throughput, and error rates under high load conditions. The results help operations teams set realistic SLO thresholds, adjust resource configurations, and optimize horizontal scaling strategies.
Stress testing pushes the system beyond expected loads to observe degradation behavior, recovery capabilities, and protection mechanisms like rate limiting or circuit breaking. These scenarios support identifying bottlenecks in the architecture, for example database connections, HTTP pools, or internal network latency.
5. CI/CD for MCP Server: build, test, deploy, smoke test
The CI/CD pipeline for an MCP Server needs to automate building, running unit tests, integration tests, and contract tests before allowing any release to be deployed. These steps ensure that source code changes do not break current behavior and adhere to MCP protocol standards.
In the deployment phase, the pipeline should perform staggered or canary deployments, followed by basic smoke tests on the target environment to confirm the server starts correctly, lists tools, and handles several primary scenarios. Smoke test results and initial monitoring metrics need to be monitored before expanding traffic to all agents to reduce the risk of wide-scale incidents.
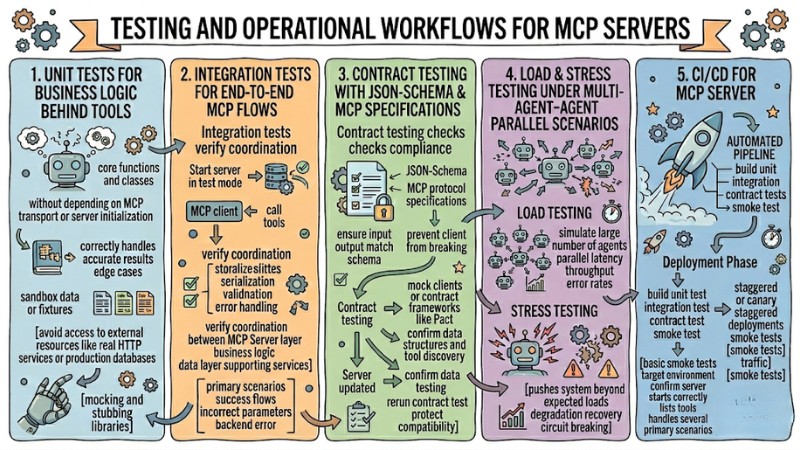
MCP Server Testing and Operation Procedure
Answering Frequently Asked Questions
What are the differences between Tools, Resources, and Prompts?
- Tools: Actions, state changes (e.g.,
send_email). - Resources: Readable data, static states (e.g.,
file_content,log_entry). - Prompts: Predefined command templates that help Agents execute complex workflows more easily.
Which metrics should an MCP Server monitor to evaluate effectiveness?
An MCP Server should monitor latency by percentile, error rates by type, and the number of tool calls over time. Additionally, it is necessary to measure the usage frequency of each tool and the task completion rate to evaluate the utility of each tool.
How to gradually move from REST APIs to an MCP Server without disruption?
You can start by wrapping a few critical endpoints into "outcome-oriented" MCP tools using the existing service layer. Once stable and fully tested, gradually expand the MCP scope and phase out direct REST integrations that are no longer needed.
How does an MCP Server handle multi-tenancy to ensure data isolation?
The MCP Server needs to attach every request to a tenant identifier and use this identifier in all data queries. Every tool must check the tenant before access and additional monitoring should be added to detect any cases of data leakage between tenants.
Read more:
- Operating an AI Agent Teams: Risk Management for the Digital Workforce
- Tasks for Coding Agents: How to Assign Work Effectively so AI Codes Accurately
- Optimizing Coding Agent Codebases: 7 Best Practices for Developers
In summary, MCP Server Best Practices emphasize designing outcome-oriented tools, clear schemas, tight security, and complete testing workflows to reduce errors and optimize performance when serving AI Agents at scale. By consistently applying MCP Server Best Practices, you can increase the reliability of your MCP Server, reduce incorrect tool calls, and better exploit existing data infrastructure.