What is AI Hallucination? Effective Solutions to Fix AI Hallucinations

When bringing Generative AI into a real-world system, a developer's biggest fear is not response speed, but instances where the model returns JSON with fabricated fields that break the downstream data pipeline. This phenomenon is often mistaken for a "magic bug," but it is actually an issue of system architecture and probability statistics; to run AI safely in a production environment, we need to clearly understand the AI hallucination mechanism and design multi-layered guardrails, from the data layer to the agent orchestration layer.
Key Takeaways
- The Nature of AI Hallucination: Understand that AI hallucinations are not conscious errors but a consequence of the neural network's probabilistic prediction mechanism, where the model prioritizes linguistic fluency over informational accuracy.
- Root Causes: Master the roles of parameters like
Temperature,Top-p, and the Transformer architecture which make the model prone to "branching" into biased probabilities when lacking a factual reference base. - Systemic Risks: Identify specific hazards in production environments such as breaking data pipelines, causing application crashes, or spreading malware through virtual resources.
- 3-Tier Defense Strategy: Build a multi-layered protection system:
- Tier 1: Optimize System Prompts and API configurations (especially Temperature = 0).
- Tier 2: Implement RAG (Retrieval-Augmented Generation) to force the model to work based on authentic grounded data.
- Tier 3: Use a Multi-agent architecture to perform cross-verification (Agent Maker creates content, Agent Checker validates).
- "Enterprise-ready" Design Thinking: Accept that hallucination is a property to be managed rather than expecting 100% elimination, thereby building mechanisms that allow AI to return an "Unknown" state instead of fabricating.
- FAQ: Understand why RAG is not a "silver bullet" (it can still fail if Vector DB data is wrong) and the most effective operational risk mitigation strategies.
What is AI Hallucination?
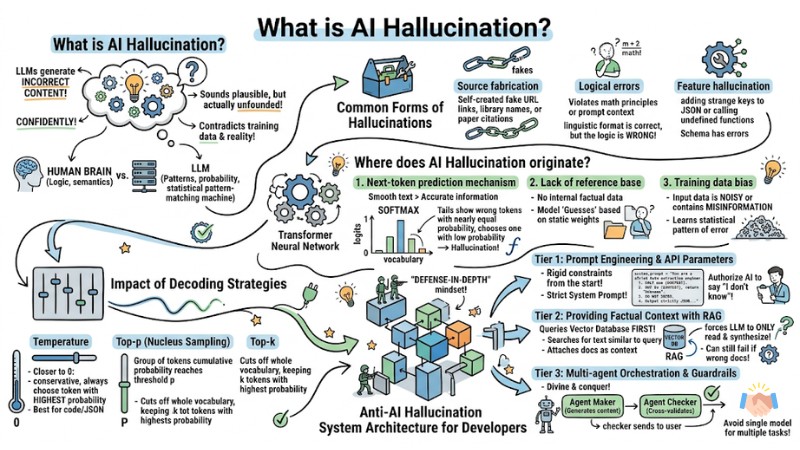
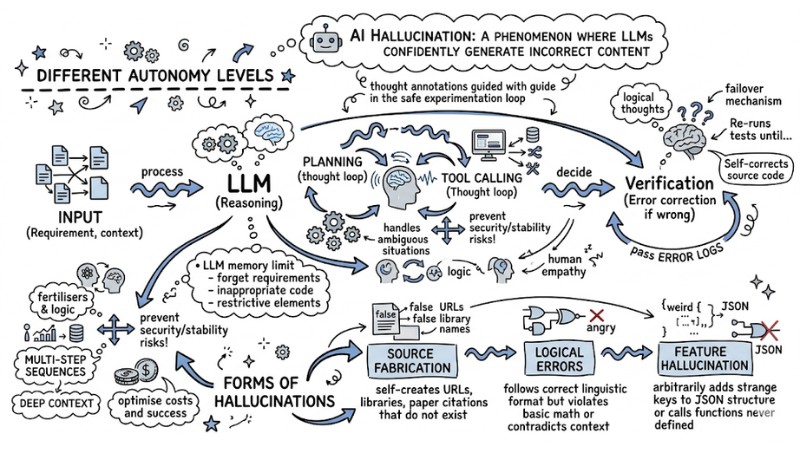
AI Hallucination is a phenomenon where large language models (LLMs) confidently generate incorrect content that sounds plausible but is actually unfounded or contradicts training data and reality.
Unlike the human brain, which has the ability to understand semantics and logic, LLMs are essentially statistical pattern-matching machines. They do not truly "lie" or "hallucinate" in a psychological sense, but simply generate tokens (word units) with the highest probability of following next according to the algorithm, even if the result is untruthful.
When calling the API of language models, your system may face common forms of hallucinations:
- Source fabrication: The model self-creates URL links, programming library names, or scientific paper citations that do not exist.
- Logical errors: The response follows the correct linguistic format but violates basic mathematical principles or contradicts the context provided in the prompt.
- Feature hallucination: Arbitrarily adding strange keys to a JSON structure or calling functions that have never been defined in the schema.
AI Hallucination is a phenomenon where large language models confidently generate incorrect content
Where does AI Hallucination originate?
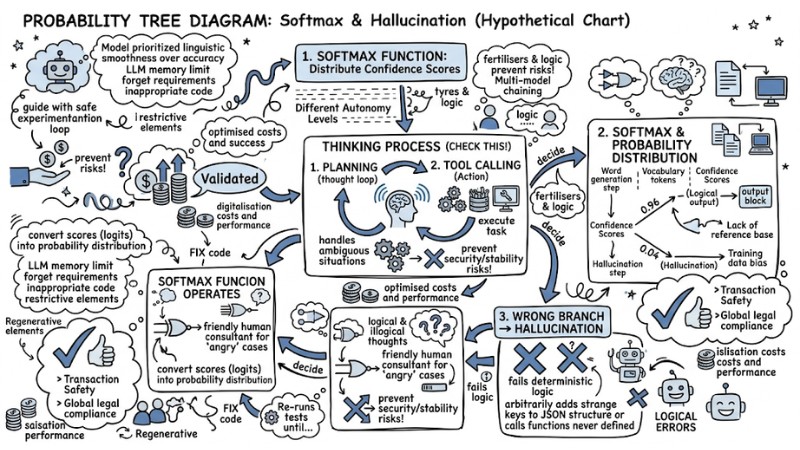
The nature of AI Hallucination stems from the design architecture of the Transformer neural network itself. Here are the 3 core causes from an algorithmic perspective:
- Next-token prediction mechanism: The model prioritizes linguistic smoothness over information accuracy.
- Lack of reference base: When not provided with internal factual data, the model must "guess" based on static weights.
- Training data bias: Input data is noisy or contains misinformation, leading the model to learn incorrect statistical associations.
In summary: Mathematically, the next-token prediction mechanism operates through the Softmax function. At each word generation step, this function converts scores (logits) into a probability distribution for the entire vocabulary. When information falls outside the model's range of certainty, correct and incorrect tokens may have nearly equal Confidence Scores. If the algorithm chooses the wrong token with a low probability at the tail of the distribution, hallucination can occur.
The essence of AI hallucination stems from the very design architecture of the Transformer neural network
Impact of Decoding Strategies
The parameters you pass to the API (Decoding Strategies) directly determine the level of hallucination. To force the model to be less "creative," you need to understand three parameters that intervene in the tail of the probability distribution:
- Temperature: The closer the value is to 0, the more conservative the model becomes, always choosing the token with the highest probability. Suitable for code and JSON.
- Top-p (Nucleus Sampling): Only considers a group of tokens whose cumulative probability reaches a certain threshold
p. - Top-k: Cuts off the entire vocabulary, keeping only the
ktokens with the highest probability at each generation step.
JSON API call payload illustrating the setting of Temperature to reduce hallucination:
{
"model": "claude-3-5-sonnet-20240620",
"messages": [{"role": "user", "content": "Extract customer information from the conversation in JSON format."}],
"temperature": 0.0, // Keep Temperature at 0 so the model doesn't invent unexpected keys
"top_p": 0.9,
"max_tokens": 1024
}
Risks of Bringing AI to Production
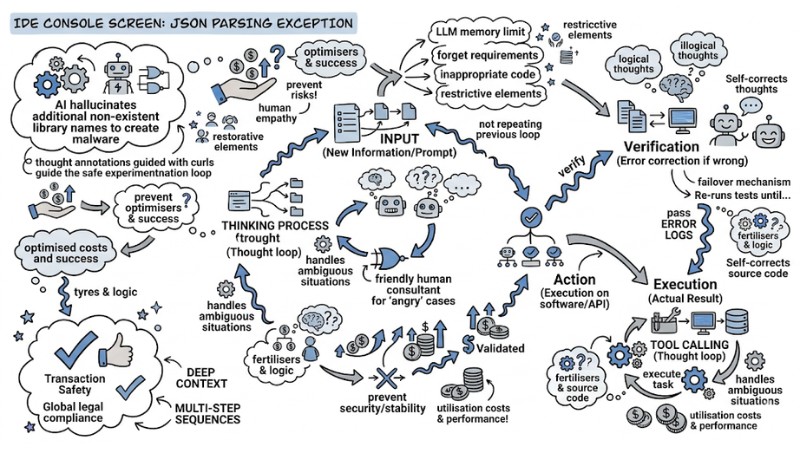
Deploying an AI model that directly interacts with databases or users without a moderation layer creates critical vulnerabilities. A small model error in the output can cause significant damage to business operations:
- Breaking Data Pipelines: When AI is tasked with analyzing system logs and outputting JSON, arbitrarily changing a field name (e.g., changing
error_codetoerrorCode) can cause downstream parsers to error out, crashing the application. - Supply Chain Attacks: Malicious actors exploit the fact that AI often hallucinates non-existent library package names to create malware and push it to npm or PyPI with that name. Unwary developers copying an
npm installcommand from AI will directly bring malicious code to their machines. - Dissemination of Misinformation: Businesses that trust and directly use AI results for legal or medical advice may face litigation.
Risks of Bringing AI to Production
Anti-AI Hallucination System Architecture for Developers
There is no solution that completely eliminates the hallucination rate of LLMs by 100%. To deploy in an enterprise environment, your system needs to be designed with a defense-in-depth mindset using 3 specific tiers:
- Establish Guardrails using Prompt Engineering and API Parameters.
- Provide Grounding Data using RAG techniques.
- Cross-moderate using Multi-agent Orchestration.
Tier 1: Prompt Engineering & API Parameters
The most effective and cost-efficient way to prevent hallucinations is to design a strict System Prompt from the beginning. Instead of letting the model speculate freely, force it to follow a set of rigorous rules. Most importantly, authorize the AI to say "I don't know" - or return "Unknown" - instead of trying to fabricate an answer.
The System prompt template prevents illusions and forces output to standard format:
system_prompt = """
You are a strict data extraction engineer.
Rules:
1. ONLY use the information provided in the [CONTEXT].
2. If the information is not found in the [CONTEXT], you MUST return the value "Unknown".
3. DO NOT INFER or use information from your background knowledge.
4. The output must strictly follow the JSON format, without any explanations.
"""
Tier 2: Providing Factual Context with RA
RAG is currently the industry standard for overcoming the LLM's weakness of lacking internal knowledge. Instead of asking the model directly, the system flow queries a Vector Database first.
When a user sends a query, the RAG system searches for text segments with the most similar meaning to the query in the Vector DB. Then, it attaches these documents as context and forces the LLM to only read and synthesize from there.
However, RAG can still fail if the Vector DB retrieves incorrect or irrelevant documents, so a supreme control tier at the Agent level is required.
Tier 3: Multi-agent Orchestration & Guardrails
When scaling the system to a complex level, using a single model for multiple tasks (calculation, data retrieval, code formatting) significantly increases the probability of generating hallucinations. This is where multi-agent orchestration solves the problem by dividing and conquering.
You will set up an architecture consisting of two components: an Agent Maker (responsible for generating content) and an Agent Checker (responsible for cross-validation). The output from the Maker is not returned directly to the user but is passed to the Checker for verification.
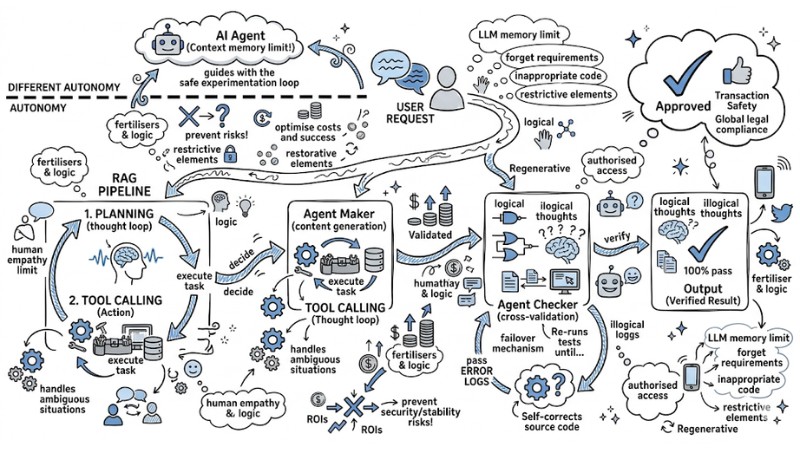
Anti-AI Hallucination System Architecture for Developers
FAQ Regarding AI Hallucination
What is AI Hallucination?
AI Hallucination is a phenomenon where large language models (LLMs) confidently generate content that is incorrect, nonsensical, or unfounded in the training data. Essentially, this is a failure in next-token sequence prediction due to the model's probabilistic mechanism, not a conscious error.
Why do AI models generate misinformation?
This phenomenon originates from the next-token prediction mechanism. LLMs calculate probability distributions to create words that sound statistically plausible, rather than retrieving information from an authentic database, leading to uncontrolled "filling in" of missing information.
How to minimize hallucinations when using LLMs?
To minimize them, you need to:
- Implement a RAG (Retrieval-Augmented Generation) architecture to provide factual context to the model.
- Adjust decoding parameters like
Temperatureto a low level (0.1–0.3) to increase stability. - Use a Multi-agent system to perform cross-checks between output results.
What risks can AI Hallucination pose to businesses?
Main risks include:
- Data system errors (e.g., broken JSON structures in a pipeline).
- Dissemination of misinformation causing loss of brand reputation.
- Security risks (e.g., AI suggesting non-existent malicious software libraries).
Does using RAG completely eliminate AI Hallucination?
No. RAG helps significantly minimize it by limiting the query scope. However, if the input data (Vector DB) contains misinformation or the retrieval process fails, the model can still generate inaccurate responses based on that context.
Read more:
- How to Choose the Optimal AI Agent Platform for Your Business in 2026
- Measuring AI Agent ROI: A roadmap from implementation to real-world value
- Self-hosted vs SaaS AI Agents: Which option is right for your business?
The nature of AI hallucination is not a "junk error," but rather the "creativity" of the Transformer algorithm being placed in the wrong context. In an enterprise environment, expecting a language model to never fabricate information is unrealistic. The most sustainable architectural solution is to acknowledge the risk and build a multi-layered Guardrails system: from optimizing Temperature and limiting context with RAG, to establishing a cross-moderation network.