10 chiến lược AI Agent Cost Optimization tiết kiệm ngân sách

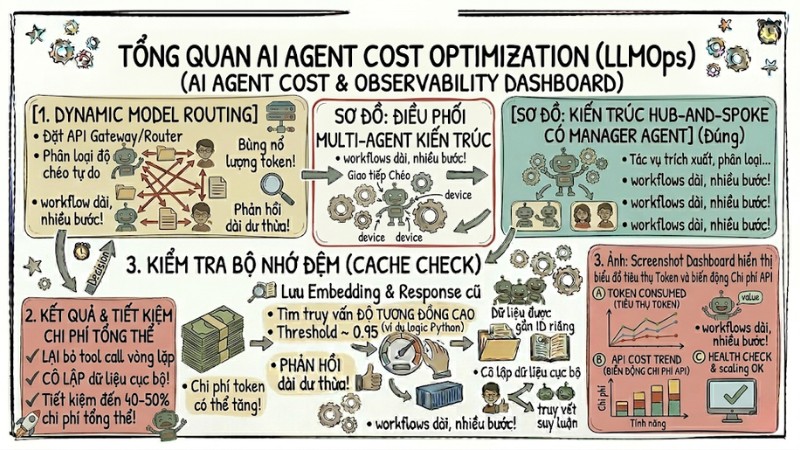
AI Agent Cost Optimization là tập hợp các kỹ thuật giúp giảm chi phí token, API và hạ tầng khi vận hành AI Agent. Bài viết này trình bày các nguyên nhân khiến chi phí tăng nhanh, giới thiệu 10 chiến lược AI Agent Cost Optimization và một framework để cân bằng giữa chi phí và hiệu suất trong các kịch bản thực tế.
Những điểm chính
- Nguyên nhân chi phí tăng: Nhận diện các yếu tố gây tăng ngân sách như chênh lệch phí token, phình to ngữ cảnh và vòng lặp gọi tool để chủ động kiểm soát chi tiêu hiệu quả.
- Các chiến lược tối ưu: Nắm vững 10 kỹ thuật chuyên sâu như Dynamic Model Routing, Semantic Caching giúp giảm đáng kể chi phí API mà vẫn duy trì chất lượng đầu ra ổn định.
- Khung vận hành cân bằng: Tiếp cận framework điều phối chi phí và hiệu suất theo từng nhóm tác vụ, hỗ trợ việc thiết kế hệ thống AI thông minh và tiết kiệm tài nguyên.
- Giải đáp thắc mắc: Làm rõ các khái niệm về tối ưu hóa chi phí và cách xử lý các lãng phí ngân sách LLM thường gặp để tối ưu hóa quy trình vận hành thực tế.
Tại sao chi phí vận hành AI Agent tăng ngoài tầm kiểm soát?
Chi phí khi deploy AI Agent với mô hình tính tiền theo token có thể tăng rất nhanh nếu không quản lý kỹ cách dùng context, độ dài câu trả lời và hành vi gọi tool của hệ thống.
- Chênh lệch giữa input token và output token: Nhà cung cấp thường tính phí output token cao hơn input token khoảng 3-4 lần do quá trình sinh văn bản tốn nhiều tài nguyên hơn. Các câu trả lời quá dài hoặc giải thích dư thừa sẽ làm chi phí và độ trễ tăng mạnh.
- Phình to ngữ cảnh (context window bloat): Việc gửi nguyên lịch sử hội thoại hoặc tài liệu dài vào mọi request khiến số token đầu vào tăng theo thời gian, mỗi lượt gọi lại phải trả tiền cho toàn bộ context cũ cộng phần mới, làm chi phí trên mỗi phiên trò chuyện tăng nhanh.
- Vòng lặp tool call và API overhead: AI Agent có thể liên tục gọi lại API hoặc tool khi gặp lỗi nếu không giới hạn số lần retry, dẫn đến chuỗi gọi tool kéo dài, bùng nổ lượng token và chi phí chỉ để xử lý một tác vụ không thành công.
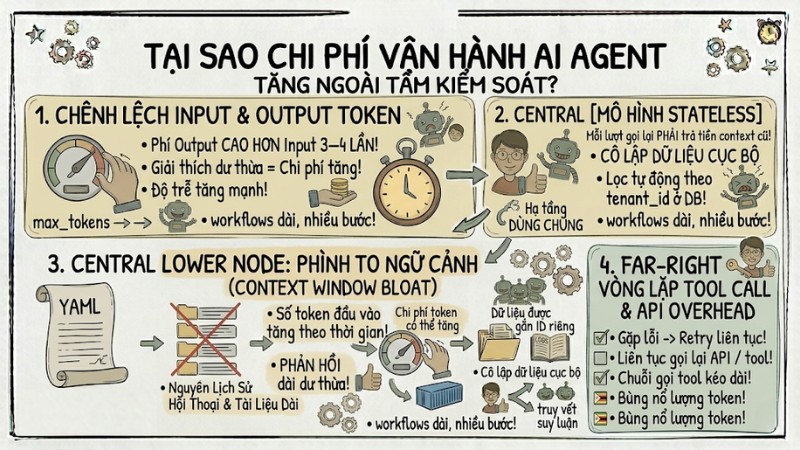
Chi phí khi vận hành AI Agent có thể tăng rất nhanh nếu không quản lý cách dùng context
10 chiến lược AI Agent Cost Optimization hiệu quả nhất
Dưới đây là các kỹ thuật phổ biến trong LLMOps giúp giảm chi phí inference cho AI Agent mà vẫn giữ được chất lượng kết quả ở mức phù hợp với từng loại tác vụ.
1. Áp dụng Dynamic Model Routing theo độ phức tạp tác vụ
Thay vì dùng luôn các mô hình cao cấp, bạn hãy đặt một lớp API Gateway hoặc router để phân loại độ phức tạp và điều hướng truy vấn đến mô hình phù hợp. Các tác vụ đơn giản như trích xuất, phân loại hoặc dịch ngắn có thể dùng model nhỏ chi phí thấp, còn yêu cầu suy luận nhiều bước mới dùng model lớn hơn. Cách này thường giúp tiết kiệm được khoảng 40-50% chi phí tổng thể.
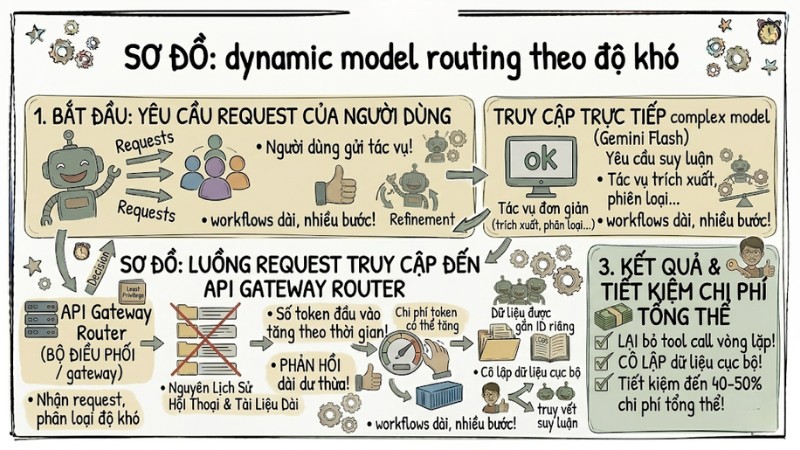
Luồng Request đi qua API Gateway Router, phân nhánh sang Simple Model và Complex Model
2. Rút ngắn độ dài đầu ra bằng Prompt Engineering
Do output token có đơn giá cao hơn input token, cần giới hạn độ dài phản hồi bằng cách chỉ định rõ trong system prompt về phong cách trả lời ngắn gọn, không chào hỏi và ưu tiên trả về cấu trúc dữ liệu như JSON.
Ví dụ cấu trúc Prompt tối ưu: “Bạn là công cụ trích xuất dữ liệu. Chỉ trả về một đối tượng JSON duy nhất chứa key tên và địa_chỉ. Tuyệt đối không thêm từ ngữ giải thích hay đoạn mở đầu nào. Chiều dài đầu ra tối đa: 50 từ.”
3. Triển khai Semantic Caching (bộ nhớ đệm ngữ nghĩa)
Thay vì chỉ cache theo chuỗi chính xác, có thể lưu embedding câu hỏi trong vector database và tìm các truy vấn mới có độ tương đồng cao để tái sử dụng câu trả lời cũ mà không cần gọi lại LLM. Cách này đặc biệt hiệu quả với hệ thống có nhiều câu hỏi tương tự nhau, giúp giảm đáng kể số lần gọi API và cải thiện độ trễ cho người dùng.
# Ví dụ logic Semantic Caching cơ bản với Python
user_query = "Làm sao để đổi mật khẩu?"
query_embedding = get_embedding(user_query)
# Kiểm tra độ tương đồng trong Vector Database (như Redis, Pinecone)
cached_response = vector_db.search_similar(query_embedding, threshold=0.95)
if cached_response:
return cached_response # Trả về ngay, không tốn phí LLM
else:
response = call_llm(user_query)
vector_db.save(query_embedding, response) # Lưu cache cho lần sau
return response
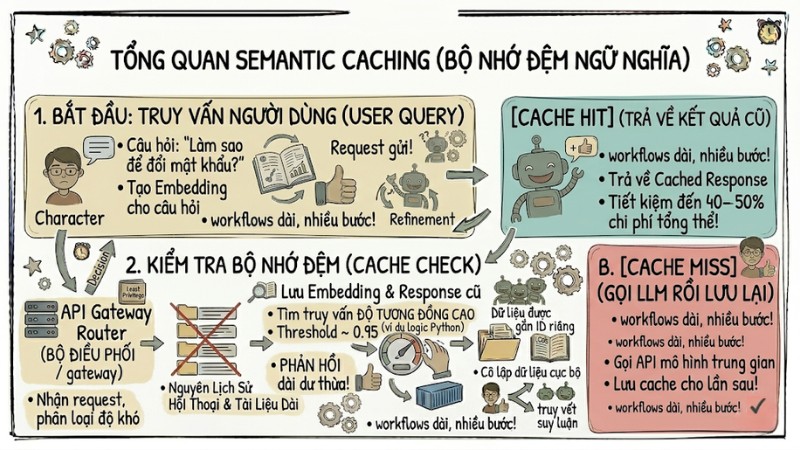
Luồng hoạt động của Semantic Caching
4. Tối ưu hóa Context Management và cắt giảm lịch sử trò chuyện
Quản lý ngữ cảnh nên dựa trên cửa sổ trượt chỉ giữ vài lượt hội thoại gần nhất. Kết hợp tóm tắt định kỳ phần lịch sử dài bằng model rẻ để giảm số token phải gửi mỗi lần. Đồng thời có thể lọc bỏ các câu xã giao hoặc nội dung không liên quan trước khi đưa vào context nhằm hạn chế context window bloat.
5. Sử dụng kỹ thuật Prompt Compression trong RAG
Khi sử dụng RAG, thay vì đưa nguyên văn tài liệu dài vào prompt, có thể áp dụng prompt compression để trích thành các đoạn ngắn giàu thông tin và loại bỏ phần ít liên quan. Điều này vừa cải thiện chất lượng truy hồi vừa cắt giảm đáng kể số token đầu vào cho mỗi yêu cầu.
6. Gom nhóm dữ liệu xử lý (Batch Processing)
Đối với các tác vụ không cần yêu cầu phản hồi theo thời gian thực, nên sử dụng Batch API của nhà cung cấp LLM để gửi nhiều yêu cầu trong một lô với mức giá thường thấp hơn khoảng 50% so với gọi trực tiếp từng request. Cách này phù hợp cho xử lý nền như phân tích log, dịch tài liệu số lượng lớn hoặc chấm điểm dữ liệu.
7. Kiểm soát tần suất giao tiếp trong Multi-Agent Orchestrators
Trong hệ nhiều Agent, nên thiết kế kiến trúc hub‑and‑spoke với một Agent quản lý trung tâm phân công công việc cho các sub‑agent, thay vì cho các agent trao đổi tự do với nhau. Mô hình này giảm đáng kể số lượt tin nhắn nội bộ và token tiêu thụ cho các cuộc trao đổi không cần thiết.
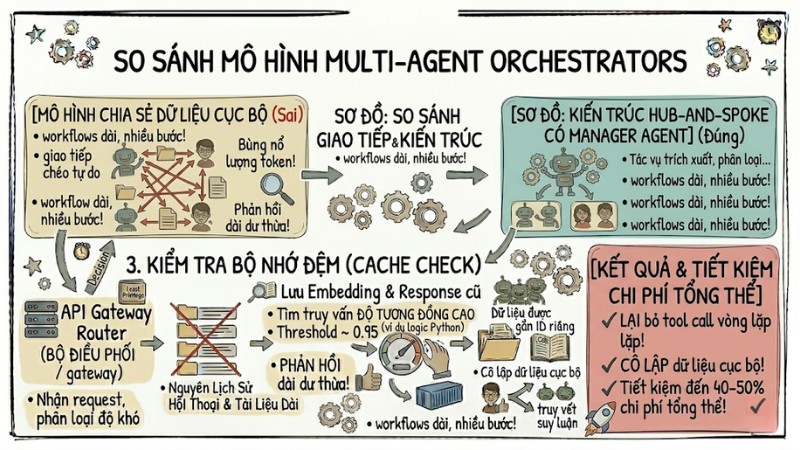
Mạng lưới Agent giao tiếp chéo và kiến trúc Hub-and-Spoke có điều phối trung tâm
8. Giới hạn tool calls và vòng lặp suy luận (Reasoning Loops)
Cần đặt ngưỡng cố định cho số lần retry tool hoặc bước suy luận liên tiếp, ví dụ giới hạn max_retries hoặc tổng số step của một phiên agent, để tránh tình trạng gọi API lặp lại khi gặp lỗi. Khi vượt ngưỡng, hệ thống nên dừng tác vụ, chuyển sang fallback hoặc yêu cầu người vận hành can thiệp.
9. Thiết lập Observability và cảnh báo ngân sách tự động
Sử dụng các nền tảng giám sát chi phí như LangSmith, Helicone hoặc dashboard tùy chỉnh để gắn thẻ chi phí theo tính năng, người dùng hoặc dịch vụ và theo dõi biến động theo thời gian thực. Khi phát hiện cost spike vượt ngưỡng định sẵn, hệ thống có thể tự động gửi cảnh báo và tạm dừng các workflow không ưu tiên.
10. Tách biệt môi trường development và production
Trong môi trường phát triển và kiểm thử, nên ưu tiên dùng mô hình mã nguồn mở chạy local hoặc cấu hình mock thay vì gọi trực tiếp model thương mại đắt tiền. Chỉ môi trường production mới được phép truy cập model trả phí, nhằm tránh việc CI/CD hoặc thử nghiệm tính năng mới làm phát sinh chi phí lớn ngoài ý muốn.
Framework cân bằng giữa chi phí và hiệu suất AI Agent
Mục tiêu không phải là cắt giảm chi phí bằng mọi giá mà là thiết kế một khung vận hành nơi hiệu suất, chất lượng và chi phí của AI Agent được tối ưu đồng thời theo từng nhóm tác vụ.
Ưu tiên chất lượng cho tác vụ cốt lõi (high‑stakes)
Với các tác vụ liên quan trực tiếp đến doanh thu, rủi ro pháp lý hoặc an toàn như tư vấn tài chính, hỗ trợ y khoa hoặc sinh mã nguồn trọng yếu, nên chọn mô hình chất lượng cao, cho phép context rộng và số bước suy luận nhiều hơn để đạt độ chính xác và độ tin cậy ở mức cao nhất có thể chấp nhận được.
Ép chi phí cho truy vấn khối lượng lớn (high‑volume)
Với các tác vụ lặp lại khối lượng lớn như tóm tắt hàng loạt nội dung, phân loại bình luận hoặc trích xuất dữ liệu tĩnh, ưu tiên dùng mô hình chi phí thấp, batch processing và semantic caching để giảm giá thành mỗi tác vụ mà vẫn đáp ứng được yêu cầu tối thiểu về chất lượng.
Giám sát chỉ số “tỷ lệ hoàn thành” (Success Rate)
Mọi thay đổi nhằm tối ưu chi phí như đổi sang mô hình rẻ hơn hoặc cắt ngắn prompt cần được đo bằng chỉ số success rate trước và sau khi thay đổi, cùng với chi phí trên mỗi tác vụ thành công. Nếu chi phí giảm mạnh trong khi success rate chỉ giảm ở mức chấp nhận được, cấu hình đó có thể duy trì, còn khi tỷ lệ lỗi tăng rõ rệt cần khôi phục hoặc điều chỉnh lại chiến lược.
Giải đáp thắc mắc thường gặp
AI Agent Cost Optimization là gì?
AI Agent Cost Optimization là quá trình đo lường và áp dụng các kỹ thuật như chọn mô hình phù hợp, tối ưu prompt, caching và giới hạn sử dụng để giảm chi phí vận hành AI Agent, đặc biệt là chi phí token và API, trong khi vẫn giữ được chất lượng ở mức chấp nhận được cho từng loại tác vụ.
Yếu tố nào tiêu tốn nhiều tiền nhất khi vận hành AI Agent?
Chi phí lớn nhất thường đến từ token generation cho phần đầu ra do output token có đơn giá cao hơn input, kết hợp với context overhead khi gửi kèm lịch sử hội thoại dài trong mỗi lần gọi. Ngoài ra, chi phí hạ tầng phục vụ vector database và các API bên thứ ba mà agent gọi như tìm kiếm hoặc scraping cũng đóng góp đáng kể vào tổng ngân sách.
Agentic workflows có thực sự đắt hơn mô hình Single-prompt thông thường không?
Có, vì agentic workflows thường chia một yêu cầu thành nhiều bước suy luận liên tiếp, mỗi bước là một lần gọi LLM kèm context nên tổng số token tiêu thụ cho một tác vụ có thể gấp nhiều lần so với single‑prompt chỉ gửi một yêu cầu và nhận một kết quả. Nếu không giới hạn số bước hoặc tối ưu context, chi phí cho một tác vụ trong agentic workflow có thể tăng theo bội số rất lớn.
Làm sao để biết tôi đang lãng phí LLM budget cho sai mô hình?
Dấu hiệu thường thấy là bạn sử dụng mô hình cao cấp để xử lý các tác vụ mang tính quy tắc cố định như trích xuất dữ liệu có cấu trúc, phân loại đơn giản hoặc mapping sang JSON trong khi chi phí trên mỗi tác vụ cao hơn rõ rệt so với giá trị mang lại. Trong các trường hợp này, cần thử nghiệm mô hình nhỏ hơn hoặc chuyên biệt cho structured extraction và so sánh tỷ lệ chính xác, nếu chênh lệch nhỏ nhưng chi phí giảm mạnh thì nên chuẩn hóa pipeline sang mô hình nhẹ.
Xem thêm:
- Khi nào nên dùng AI Agent? 7 dấu hiệu cần tự động hóa
- Coding Agent là gì? Giải pháp AI lập trình tự động tốt nhất
- 7 Coding Agent Use Cases thực tế giúp tối ưu quy trình
AI Agent Cost Optimization không chỉ là cắt giảm hóa đơn API mà là quá trình thiết kế lại kiến trúc, routing mô hình, quản lý ngữ cảnh và chi phí theo thời gian thực để dùng đúng tài nguyên cho đúng loại công việc. Khi áp dụng đồng bộ các chiến lược như dynamic routing, semantic caching, batch processing và guardrails cho tool calls, bạn có thể giảm đáng kể chi phí inference trong khi vẫn duy trì hiệu suất và độ chính xác của AI Agent ở những điểm chạm quan trọng với người dùng.
Thẻ