RAG là gì? Tìm hiểu chi tiết về Retrieval-Augmented Generation

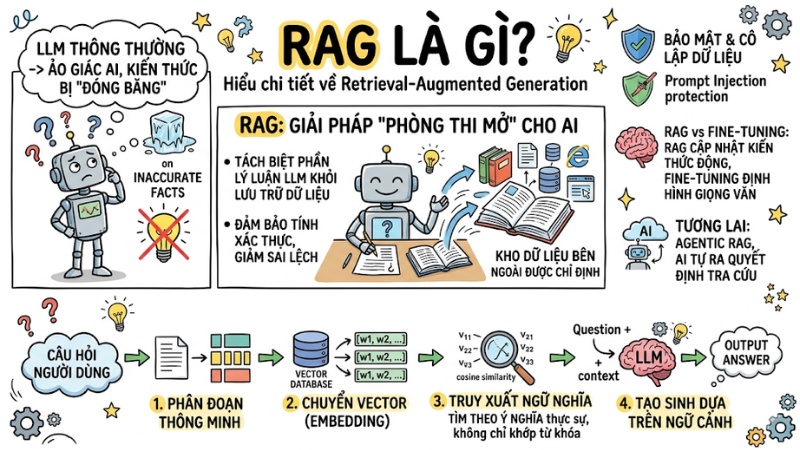
Trong kỷ nguyên bùng nổ của LLM, các nhà phát triển đang phải đối mặt với hai vấn đề nan giải: Ảo giác AI và kiến thức bị “đóng băng” tại thời điểm huấn luyện. Lúc này, RAG xuất hiện như một giải pháp tối ưu: Thay vì tự bịa, mô hình truy xuất và trích xuất thông tin từ kho dữ liệu bên ngoài được chỉ định, từ đó vừa giảm sai lệch thông tin vừa mở ra thế hệ mới cho các hệ thống tự động hóa. Trong bài viết này, mình sẽ cùng bạn mổ xẻ chi tiết cách RAG là gì và vận hành như thế nào dưới góc độ hệ thống.
Những điểm chính
- Bản chất của RAG: Hiểu RAG là giải pháp "phòng thi mở" cho AI, tách biệt phần lý luận của LLM khỏi phần lưu trữ dữ liệu để đảm bảo tính xác thực và giảm ảo giác.
- Quy trình 4 bước chuẩn hóa: Nắm vững pipeline dữ liệu từ khâu Ingestion (phân đoạn), Embedding (chuyển vector), Retrieval (truy xuất ngữ nghĩa) đến Generation (tạo sinh dựa trên ngữ cảnh).
- Chiến lược dữ liệu: Hiểu rõ tầm quan trọng của việc phân đoạn thông minh.
- So sánh Semantic Search với Keyword Search: Tận dụng Cosine Similarity để tìm kiếm theo ý nghĩa thực sự thay vì khớp từ khóa, giúp AI hiểu được ngay cả những câu hỏi mơ hồ, viết tắt hoặc từ lóng.
- Phân biệt RAG với Fine-tuning: Phân định rõ: Dùng RAG để cập nhật kiến thức động, thời gian thực; dùng Fine-tuning để định hình giọng văn, chuyên môn ngành hẹp. Kết hợp cả hai khi cần chuyên gia vừa am hiểu ngôn ngữ vừa cập nhật dữ liệu mới nhất.
- Quản trị rủi ro và bảo mật: Đối mặt với các thách thức thực tế như rò rỉ dữ liệu chéo và tấn công Prompt Injection bằng cách cô lập dữ liệ và thiết lập tầng kiểm duyệt nghiêm ngặt.
- Tương lai AI Agentic RAG: Chuyển dịch từ pipeline tuyến tính sang hệ thống tự chủ, nơi AI Agent tự ra quyết định "khi nào cần gọi RAG" và tự viết lại câu truy vấn để đạt độ chính xác cao nhất.
- Giải đáp FAQ: Nắm bắt cách tối ưu chi phí, bảo mật đa người dùng và vai trò không thể thay thế của Vector Database trong kỷ nguyên RAG.
RAG là gì?
RAG (Retrieval-Augmented Generation) là một kiến trúc AI kết hợp sức mạnh ngôn ngữ của LLM với kho dữ liệu bên ngoài. Mô hình này hoạt động như một “phòng thi mở” cho phép mô hình tra cứu tài liệu thực tế trước khi trả lời để tăng độ chính xác và giảm ảo giác.
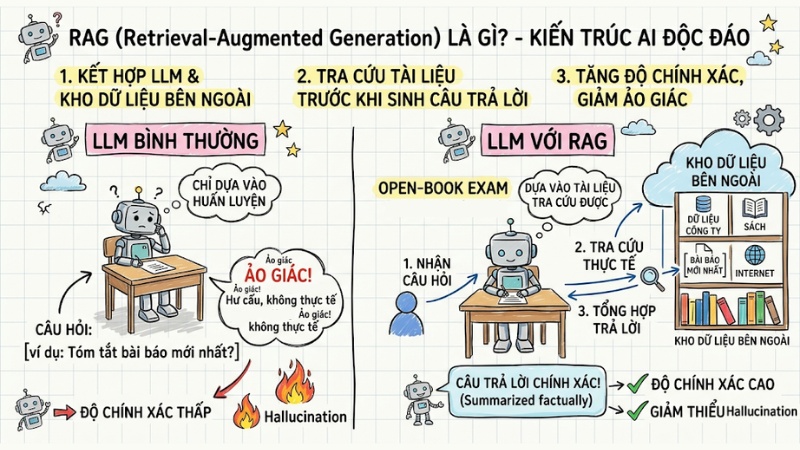
RAG là một kiến trúc AI kết hợp sức mạnh ngôn ngữ của LLM với kho dữ liệu bên ngoài
Bản chất của RAG và tầm quan trọng đối với hệ thống LLM
Bản chất của các mô hình Generative AI
Để hiểu tại sao kiến trúc RAG lại trở thành tiêu chuẩn công nghiệp, chúng ta cần nhìn vào bản chất toán học của các mô hình Generative AI. Ở cấp độ nền tảng, một LLM hoạt động dựa trên cơ chế Token prediction (dự đoán token tiếp theo) bằng cách tính toán xác suất phân phối của các chuỗi văn bản đã học.
Điều này có nghĩa là khi tạo câu trả lời, AI thực chất ghép các từ có xác suất xuất hiện liền kề cao nhất, chứ không thực sự “hiểu” tính đúng sai của sự kiện.
Tầm quan trọng của RAG
Năm 2020, nhóm nghiên cứu dẫn đầu bởi Patrick Lewis đã định hình ra khái niệm RAG để giải quyết lỗ hổng toán học này. Thay vì cố gắng nhồi nhét mọi kiến thức vào tham số mô hình (parameters) vốn tốn kém để huấn luyện, RAG tách bạch phần lý luận (reasoning) của AI khỏi phần lưu trữ dữ liệu.
Hệ thống cho phép LLM truy cập vào một cơ sở tri thức đáng tin cậy trước khi phản hồi. Quá trình này mang lại 3 lợi thế cốt lõi:
- Neo dữ liệu: Buộc mô hình ngôn ngữ giới hạn câu trả lời dựa trên dữ kiện thực tế trong tài liệu, giảm thiểu tối đa hiện tượng ảo giác.
- Trích dẫn nguồn: Vì câu trả lời được tổng hợp từ các đoạn văn bản cụ thể được truy xuất, hệ thống có thể chỉ rõ file gốc, trang tài liệu để người dùng hoặc kiểm toán viên tự kiểm chứng tính chính xác.
- Kiểm soát luồng dữ liệu: Dữ liệu riêng tư không cần đưa vào quá trình huấn luyện LLM công khai, đảm bảo tính bảo mật.
Lưu ý: Kiến trúc RAG không làm cho AI "thông minh" hơn hay thay đổi được khả năng suy luận logic gốc của mô hình. RAG chỉ đơn thuần đóng vai trò cung cấp đúng thông tin đầu vào cho một cỗ máy xử lý ngôn ngữ xuất sắc.
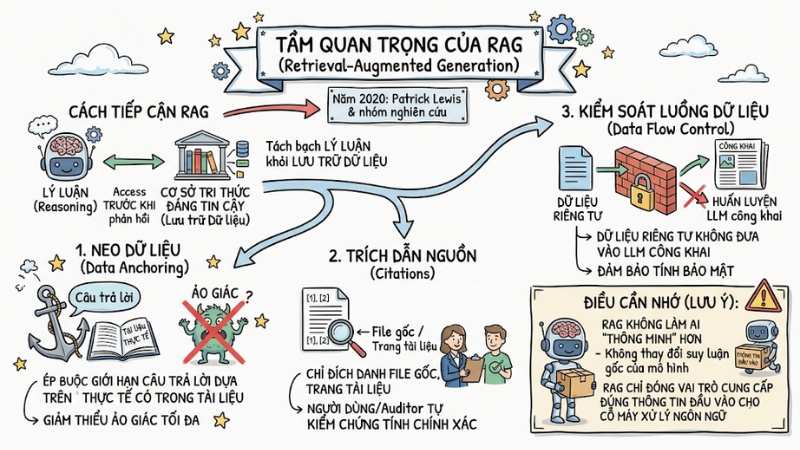
Tầm quan trọng của RAG đối với hệ thống LLM
Tìm hiểu kiến trúc của RAG: Quy trình 4 bước hoạt động
Dưới góc độ Data Engineering, một luồng xử lý dữ liệu của RAG hoạt động theo 4 bước tuần tự sau:
- Nạp và phân đoạn: Phân chia dữ liệu thô thành các đoạn văn bản có kích thước phù hợp.
- Tạo nhúng: Chuyển đổi các đoạn văn bản thành vector số học đại diện cho ý nghĩa và lưu trữ chúng.
- Truy xuất: Truy vấn các đoạn thông tin có ý nghĩa liên quan nhất dựa trên truy vấn người dùng.
- Tăng cường và tạo sinh: Kết hợp ngữ cảnh tìm được vào Prompt và yêu cầu LLM tạo câu trả lời cuối cùng.
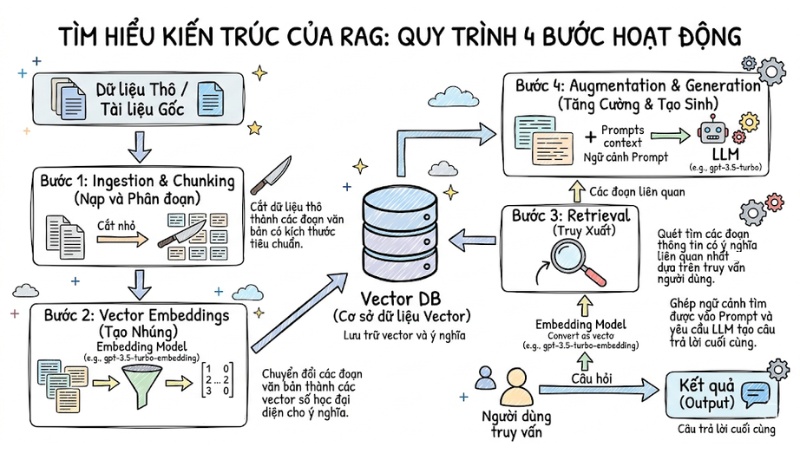
Tìm hiểu kiến trúc của RAG: Quy trình 4 bước hoạt động
Hãy cùng đi sâu vào cơ chế kỹ thuật của từng giai đoạn trong pipeline này.
Bước 1: Nạp và xử lý dữ liệu
Dữ liệu đầu vào của doanh nghiệp thường dài và phi cấu trúc, trong khi LLM có giới hạn cứng về số lượng token tối đa có thể xử lý trong một lần gọi API. Nếu nạp toàn bộ tài liệu hàng trăm trang, hệ thống sẽ báo lỗi tràn bộ nhớ hoặc từ chối phản hồi.
Do đó, kỹ sư dữ liệu phải áp dụng các chiến lược phân đoạn. Việc phân chia văn bản cần đảm bảo giữ nguyên ý nghĩa của câu hoặc đoạn.
Kinh nghiệm: Nếu đặt kích thước phân đoạn quá lớn (ví dụ >2000 tokens), việc truy xuất nhiều phân đoạn có thể làm tràn Context Window. Ngược lại, nếu phân đoạn quá nhỏ (dưới 50 tokens), đoạn văn bản bị cắt xén rời rạc, khiến AI mất hoàn toàn ngữ cảnh để hiểu thông điệp cốt lõi.
Bước 2: Tạo nhúng (Embedding) và lưu trữ
Sau khi chia nhỏ, các đoạn text được đưa qua một mô hình Embedding chuyên dụng (như text-embedding-3-large của OpenAI hoặc mô hình open-source) để chuyển đổi thành Vector Embeddings. Đây là các mảng chứa hàng ngàn con số, biểu diễn ý nghĩa không gian của đoạn văn đó.
Các vector này sau đó được lập chỉ mục (Index) và lưu vào cơ sở dữ liệu Vector như Pinecone, Milvus. Tốc độ truy vấn hàng triệu vector của loại cơ sở dữ liệu này chỉ mất vài mili-giây, tạo nền tảng vững chắc cho hệ thống thời gian thực.
Bước 3: Truy xuất thông tin
Khi người dùng đặt câu hỏi, câu hỏi đó cũng được chạy qua mô hình Embedding ở Bước 2 để biến thành một Vector. Lúc này, hệ thống sẽ thực hiện Semantic Search (Tìm kiếm theo ngữ nghĩa) bên trong Vector Database.
Khác với tìm kiếm theo từ khóa truyền thống, yêu cầu khớp chính xác từng ký tự, Semantic Search sử dụng các thuật toán toán học như Cosine Similarity để đo lường góc lệch giữa các vector trong không gian đa chiều. Hai vector có góc càng hẹp (chỉ số Cosine tiến sát mức 1) thì ý nghĩa càng tương đồng. Nhờ đó, dù người dùng nhập từ đồng nghĩa, từ lóng hay viết tắt, hệ thống vẫn truy xuất đúng đoạn tài liệu chứa câu trả lời.
Bước 4: Tăng cường ngữ cảnh và tạo sinh
Đây là chặng cuối nơi RAG "đóng gói" thông tin đưa cho LLM. Các đoạn văn bản được truy xuất ở Bước 3 sẽ được nhúng thẳng vào một “System Prompt” định sẵn cùng với câu hỏi gốc của người dùng.
System: Bạn là trợ lý AI nội bộ đáng tin cậy. Chỉ trả lời câu hỏi dựa trên CONTEXT được cung cấp dưới đây. Nếu CONTEXT không chứa thông tin liên quan, hãy nói "Tôi không tìm thấy dữ liệu", tuyệt đối không tự suy diễn.
CONTEXT:
- [Đoạn truy xuất 1: Quy định nghỉ phép năm 2024 chỉ áp dụng cho...]
- [Đoạn truy xuất 2: Phụ lục BHXH về thai sản...]
User Query: Nhân sự làm việc 2 năm được nghỉ chế độ mấy ngày?
Với cấu trúc Prompt được khóa chặt này, LLM sẽ vận dụng khả năng đọc hiểu để tổng hợp, định dạng ngôn ngữ và đưa ra câu trả lời chuẩn xác nhất. Tuy nhiên, rủi ro lớn nhất ở bước này là Prompt Injection, khi tài liệu tải lên có chứa mã độc ẩn nhằm ghi đè các lệnh System (hệ thống).
Nên sử dụng Fine-Tuning hay RAG?
Khi thiết kế hệ thống AI, việc nhầm lẫn giữa Fine-tuning (tinh chỉnh mô hình) và RAG thường dẫn đến lãng phí hàng ngàn USD chi phí tính toán mà kết quả vẫn không giải quyết được ảo giác.
Fine-tuning là quá trình cập nhật lại trọng số của AI bằng cách huấn luyện nó trên một tập dữ liệu ví dụ. Nó cực kỳ xuất sắc trong việc thay đổi giọng văn, sắc thái biểu đạt, hoặc giúp AI học cách xuất định dạng dữ liệu phức tạp. Tuy nhiên, Fine-tuning thường rất hạn chế trong việc nhồi các sự kiện mới vào mô hình, và tốn chi phí huấn luyện lại mỗi khi dữ liệu thay đổi.
Ngược lại, RAG đại diện cho xu hướng mở rộng kiến thức tiết kiệm chi phí. Bạn có thể cung cấp tài liệu mới cho AI ngay lập tức mà không cần chạm vào lõi mô hình. Hạn chế của RAG là nó không thay đổi được hành vi bẩm sinh của mô hình.
| Tiêu chí | Kiến trúc RAG | Fine-Tuning | Trường hợp nên kết hợp cả hai |
|---|---|---|---|
| Mục đích chính | Bổ sung thông tin động, tài liệu mới, dữ kiện thực tế thời gian thực. | Dạy AI cách giao tiếp, định dạng đầu ra, học thuật ngữ chuyên ngành hẹp. | Khi cần một AI am hiểu ngôn ngữ pháp lý phức tạp và đồng thời truy xuất luật mới nhất. |
| Xử lý ảo giác | Rất hiệu quả nhờ cơ chế bắt buộc tham chiếu nguồn. | Kém hiệu quả, mô hình vẫn dễ bịa đặt thông tin. | - |
| Cập nhật dữ liệu | Tức thì. Chỉ cần thêm/xóa file trong Vector Database. | Chậm và tốn kém. Cần làm sạch dữ liệu và huấn luyện lại. | - |
| Bảo mật và phân quyền | Dễ dàng gán quyền truy cập (RBAC) trên từng đoạn tài liệu. | Không thể phân quyền. Bất kỳ ai cũng có thể truy vấn dữ liệu đã huấn luyện. | - |
| Chi phí hạ tầng | Thấp đến trung bình (Chủ yếu là phí API và lưu trữ Vector). | Rất cao (Cần thuê GPU mạnh như A100/H100 và kỹ sư ML). | - |
Nguyên tắc thiết kế hệ thống vững chắc: Luôn dùng RAG làm nền tảng xử lý tri thức trước, và chỉ cân nhắc Fine-tuning khi mô hình LLM gốc không thể hiểu được định dạng hoặc ngôn ngữ chuyên biệt của ngành bạn.
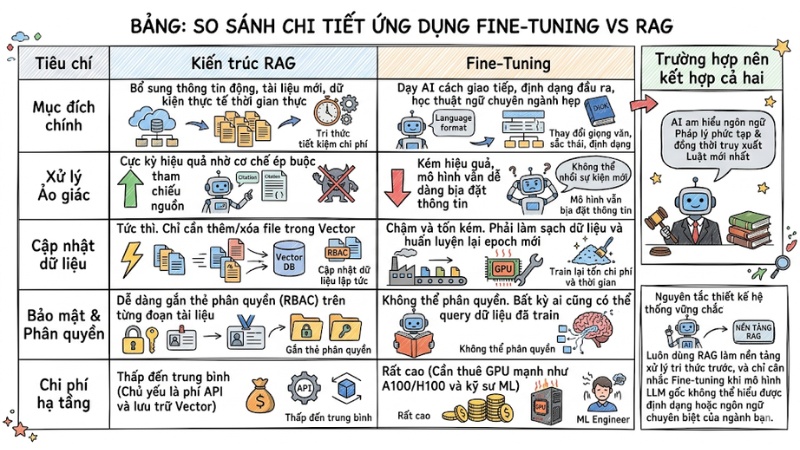
So sánh ngắn gọn Fine-Tuning và RAG
Thách thức khi triển khai RAG
Mặc dù có luồng xử lý khá rõ ràng, việc dịch chuyển RAG từ môi trường thử nghiệm (POC) lên quy mô thực tế (Production) của tổ chức đối mặt với các vấn đề kỹ thuật không nhỏ.
Trong kiến trúc Multi-tenant, việc dùng chung một Vector Database chứa rủi ro rò rỉ dữ liệu chéo nghiêm trọng. Nếu quá trình phân chia namespace hoặc metadata lọc quyền không được cô lập chuẩn xác, một nhân viên cấp thấp có thể khéo léo dùng Prompt để tìm kiếm và trích xuất báo cáo lương từ kho dữ liệu chung. Bên cạnh đó, RAG rất dễ bị tấn công qua các tài liệu đầu vào độc hại chứa lệnh ẩn để thao túng kết quả của LLM.
Tương lai với AI Agentic Workflow
Vượt qua các rào cản về cách ly dữ liệu, kiến trúc RAG đang tiến hóa mạnh mẽ lên mô hình hệ thống Agentic RAG. Thay vì chỉ là một pipeline chạy tuyến tính (hỏi -> tìm kiếm -> trả lời), RAG lúc này trở thành một "công cụ" chuyên biệt được giao cho các luồng AI Agent Orchestration quản lý.
Trong quy trình AI Agent Orchestration, tác tử AI sẽ tự động lập luận và đưa ra quyết định: "Với truy vấn này, tôi có nên gọi RAG để lấy tài liệu nội bộ không, hay gọi API tìm kiếm web?". Thậm chí, nếu đoạn văn bản trả về từ cơ sở dữ liệu bị thiếu thông tin, AI Agent sẽ tự động viết lại câu truy vấn và gọi RAG thêm một lần nữa cho đến khi đủ dữ kiện, biến hệ thống thành một cỗ máy tự chủ thực sự.
Câu hỏi thường gặp về RAG
RAG (Retrieval-Augmented Generation) là gì?
RAG là kiến trúc AI kết hợp giữa khả năng ngôn ngữ của LLM và kho dữ liệu bên ngoài. Nó hoạt động như một “phòng thi mở”, cho phép AI tra cứu tài liệu thực tế trước khi trả lời, giúp thông tin chính xác và giảm thiểu tình trạng ảo giác AI (AI Hallucination).
Tại sao cần sử dụng RAG thay vì chỉ tinh chỉnh (Fine-tuning) mô hình?
RAG vượt trội hơn Fine-tuning trong việc cập nhật dữ liệu thời gian thực và quản lý chi phí. Trong khi Fine-tuning giúp AI học sắc thái ngôn ngữ, RAG cấp quyền truy cập vào kho tri thức động, có thể thay đổi liên tục mà không cần huấn luyện lại toàn bộ mô hình.
Các thành phần chính trong một quy trình RAG là gì?
Một hệ thống RAG tiêu chuẩn gồm 4 thành phần:
- Nạp dữ liệu (Ingestion): Phân chia và chuyển đổi văn bản thành vector.
- Cơ sở dữ liệu Vector (Vector DB): Lưu trữ và đánh chỉ mục dữ liệu.
- Truy xuất (Retrieval): Tìm kiếm thông tin liên quan.
- Tạo sinh (Generation): Tổng hợp câu trả lời dựa trên ngữ cảnh.
RAG có giải quyết được hoàn toàn vấn đề AI "ảo tưởng" (hallucination) không?
Không hoàn toàn. RAG giảm đáng kể ảo giác bằng cách neo câu trả lời vào dữ liệu thực tế (AI Grounding), nhưng chất lượng đầu ra vẫn phụ thuộc vào độ chính xác của tài liệu nguồn và chiến lược truy xuất dữ liệu của hệ thống.
Làm thế nào để bảo mật dữ liệu khi triển khai RAG cho nhiều người dùng?
Bạn cần áp dụng kiến trúc Multi-tenant với cơ chế cách ly workspace. Mỗi người dùng nên có bộ chỉ mục (index) riêng biệt và các lớp bảo mật như mã hóa API key, kiểm soát quyền truy cập công cụ (RBAC) để ngăn chặn rò rỉ dữ liệu chéo hoặc tấn công SSRF.
Kiến trúc RAG có cần dùng đến Vector Database không?
Vector Database là công cụ phổ biến nhất, nhưng hiện nay RAG có thể tích hợp trên Database truyền thống (SQL/NoSQL có hỗ trợ Vector) hoặc nâng cấp lên GraphRAG (Đồ thị tri thức) để hiểu ngữ cảnh sâu hơn.
Xem thêm:
- 10 chiến lược AI Agent Cost Optimization tiết kiệm ngân sách
- Cách chọn nền tảng AI Agent tối ưu cho doanh nghiệp 2026
- Self-hosted vs SaaS AI Agent: Lựa chọn nào cho doanh nghiệp?
RAG đang trở thành “xương sống” cho các hệ thống LLM hiện đại: thay vì nhồi mọi thứ vào mô hình và chấp nhận ảo giác, bạn tách phần tri thức ra ngoài, truy xuất đúng dữ liệu rồi mới cho AI suy luận và trả lời. Khi kết hợp pipeline 4 bước, chiến lược phân đoạn thông minh, Vector Database, bảo mật multi-tenant và (khi cần) fine-tuning, bạn có thể xây dựng những AI Agent tự chủ vừa hiểu ngôn ngữ chuyên sâu, vừa luôn cập nhật kiến thức thời gian thực mà vẫn kiểm soát được chi phí và rủi ro vận hành.