Token là gì? Phân loại và cách tối ưu chi phí token hiệu quả

Khi nhắc đến khái niệm token trong ngành IT, tùy thuộc vào việc bạn là một kỹ sư bảo mật, nhà lập trình blockchain hay chuyên gia dữ liệu, thuật ngữ này sẽ mang những định nghĩa hoàn toàn khác biệt. Trong khuôn khổ bài viết này, mình sẽ tập trung giải mã khái niệm token duy nhất trong lĩnh vực AI và các hệ thống LLMs. Ở bài viết này, mình sẽ cùng bạn tìm hiểu chi tiết về những lợi ích, hạn chế và cách tối ưu chi phí token hiệu quả nhất!
Những điểm chính
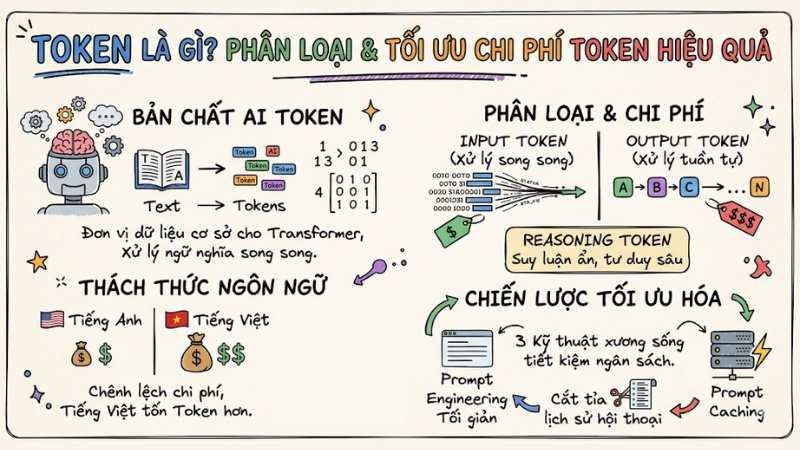
- Bản chất AI Token: Hiểu rõ Token là đơn vị dữ liệu cơ sở mà các mô hình Transformer dùng để xử lý ma trận ngữ nghĩa, thay vì đọc hiểu văn bản như con người.
- Thách thức ngôn ngữ: Nhận diện sự chênh lệch chi phí giữa tiếng Anh và tiếng Việt do đặc thù tokenizer của các mô hình LLM hiện nay.
- Phân loại và chi phí: Phân biệt rõ Input tokens (xử lý song song, rẻ) và Output tokens (xử lý tuần tự, đắt, tốn kém tài nguyên). Nắm vững khái niệm Reasoning tokens (suy luận ẩn) trong các mô hình tư duy sâu.
- Context Window: Hiểu giới hạn ngữ cảnh nhưng cần tránh bẫy "Lost in the middle" – hiện tượng AI quên thông tin quan trọng nằm ở giữa tài liệu dài.
- Chiến lược tối ưu hóa: Áp dụng 3 kỹ thuật xương sống: Tối giản Prompt Engineering, cắt tỉa lịch sử hội thoại tại Backend và tận dụng Prompt Caching.
- Giải đáp FAQ: Nắm vững cách ước lượng chi phí, rủi ro của giới hạn ngữ cảnh và bản chất của quy trình Tokenization trong các hệ thống AI hiện đại.
Phân định nhanh: 3 loại Token trong ngành IT
Để tiết kiệm thời gian cho bạn tra cứu tài liệu, dưới đây là sự khác biệt cơ bản về bản chất của 3 loại token phổ biến nhất hiện nay:
| Loại Token | Bản chất kỹ thuật | Ứng dụng thực tế |
|---|---|---|
| Security token | Mã hóa được sử dụng để xác thực quyền truy cập (Ví dụ: JSON Web Token - JWT, OAuth). | Xác thực người dùng khi gọi API, đăng nhập hệ thống nội bộ. |
| Crypto Token | Tài sản kỹ thuật số được phát hành và vận hành trên một nền tảng Blockchain có sẵn. | Sử dụng trong giao dịch tài chính, hợp đồng thông minh chuẩn ERC-20. |
| AI Token | Đơn vị dữ liệu cơ sở (ví dụ: từ, âm tiết, pixel) dùng làm đầu vào hoặc đầu ra cho mô hình học máy. | Tính toán chi phí gọi API AI, định lượng dữ liệu đầu vào cho các mô hình LLM. |
Phần tiếp theo của bài viết sẽ đi sâu vào việc phân tích kiến trúc vận hành của AI Token.
AI Token là gì? Bản chất của Tokenization
Định nghĩa
Trong lĩnh vực trí tuệ nhân tạo, Token là đơn vị dữ liệu cơ sở được băm nhỏ từ văn bản, hình ảnh hoặc âm thanh đầu vào, giúp các mô hình AI có thể đọc hiểu, dự đoán và xử lý thông tin dưới dạng các chuỗi số học.
Về bản chất kiến trúc, các mô hình Transformer không hiểu văn bản theo cách con người làm. Chúng chỉ là những cỗ máy xử lý ma trận toán học. Do đó, trước khi một đoạn văn bản được đưa vào mô hình, nó phải đi qua một bộ phân tách gọi là Tokenizer. Bộ phận này chịu trách nhiệm băm nhỏ văn bản (Tokenization) và gán cho mỗi phần một mã định danh số học duy nhất.
Ví dụ trong tiếng Anh, từ "darkness" có thể không được AI nhận diện là một từ hoàn chỉnh. Tokenizer có thể cắt nó thành hai token riêng biệt: "dark" (ID: 217) và "ness" (ID: 655). Các ID này sau đó được chuyển đổi thành các vector số học để hệ thống tính toán ngữ nghĩa dựa trên ma trận không gian.
Lưu ý: Các mã số ID cụ thể (217 và 655) phụ thuộc vào bộ từ vựng của từng tokenizer, và không được dùng thống nhất trên mọi hệ thống AI.
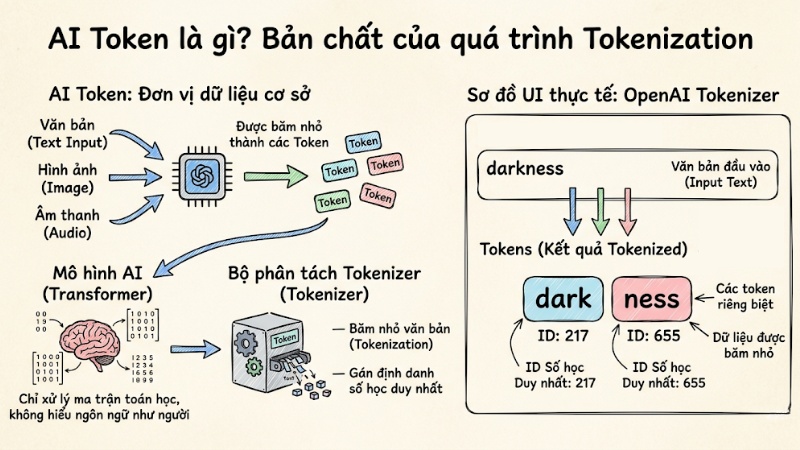
Token là đơn vị dữ liệu cơ sở được băm nhỏ từ văn bản, hình ảnh hoặc âm thanh đầu vào
Xử lý đa phương thức
Ngày nay, token không chỉ giới hạn ở văn bản. Với sự bùng nổ của AI tạo sinh đa phương thức, hệ thống sử dụng các loại token khác nhau:
- Vision token: Cắt nhỏ hình ảnh thành các mảng (patches) pixel hoặc voxel để nhận diện thị giác.
- Audio token: Chuyển đổi sóng âm thành các vector ngữ nghĩa để mô hình có thể "nghe" và phản hồi theo thời gian thực.
Sự bất lợi ngôn Ngữ: Tiếng Anh với Tiếng Việt
Khi triển khai các dự án AI tại thị trường Việt Nam, một trong những "nỗi đau" lớn nhất của các kỹ sư là chi phí API. Tại sao gọi API bằng tiếng Việt lại luôn đắt và chậm hơn tiếng Anh?
Câu trả lời nằm ở đặc tính độ dài không cố định của token. Các mô hình phổ biến hiện nay (như GPT-4 hay Claude) được huấn luyện chủ yếu trên tập dữ liệu tiếng Anh. Do đó, bộ từ điển Tokenizer của chúng được tối ưu để nhận diện tiếng Anh: Thường 1 từ ≈ 1.33 token (hay 1 token ≈ 0.75 từ) trong tiếng Anh, do cơ chế token hóa theo tiểu từ
Tuy nhiên, với tiếng Việt, do từ vựng thường là từ ghép và ít phổ biến hơn trong tập huấn luyện, AI sẽ phải băm nhỏ một từ thành nhiều ký tự hoặc âm tiết lẻ. Điều này làm tăng đột biến chi phí điện toán và độ trễ.
| Ngôn ngữ | Câu mẫu | Số từ | Số Token (Ước tính) | Tỷ lệ Token/Từ |
|---|---|---|---|---|
| Tiếng Anh | "I love programming in Golang" | 5 từ | 5 - 7 tokens | ~1.0–1.4 |
| Tiếng Việt | "Tôi thích lập trình bằng Golang" | 6 từ | 8 - 12 tokens | ~1.6–2.0 |
So sánh số lượng token tiêu thụ khi xử lý một câu tiếng Việt với một câu tiếng Anh
Quy tắc ước lược nhanh như sau::
- Tiếng Anh: 1 Token ≈ 0.75 từ (100 tokens ~ 75 từ).
- Tiếng Việt: 1 Từ ≈ 1.5 đến 2.5 tokens (Tùy thuộc vào độ phức tạp của từ vựng chuyên ngành).
Tính kinh tế của Token: Input, Output và Context Window
Phân loại token
Để tối ưu hóa kiến trúc AI, bạn bắt buộc phải hiểu cách các nhà cung cấp định giá và phân bổ tài nguyên tính toán dựa trên luồng dữ liệu (Data flow).
- Input tokens (Token đầu vào): Là lượng dữ liệu bạn gửi cho AI thông qua prompt. Quá trình này được xử lý song song trên GPU, tốc độ cực nhanh và tiêu tốn ít tài nguyên. Do đó, giá của Input token thường rất rẻ.
- Output tokens (Token đầu ra): Là kết quả mà AI trả về. Quá trình sinh chữ này (Inference) bắt buộc phải diễn ra tuần tự - chữ đằng trước quyết định chữ đằng sau. Vì không thể xử lý song song, Output token tốn rất nhiều thời gian tính toán, dẫn đến giá thành đắt hơn Input từ 3 đến 5 lần.
- Reasoning tokens (Token suy luận ẩn): Xuất hiện trong các mô hình đòi hỏi suy luận sâu (ví dụ: o1). Hệ thống sẽ tự động sinh ra hàng ngàn token ẩn trong quá trình "suy nghĩ" để giải quyết logic trước khi xuất ra kết quả cuối cùng. Việc này tăng độ chính xác nhưng đốt rất nhiều chi phí.
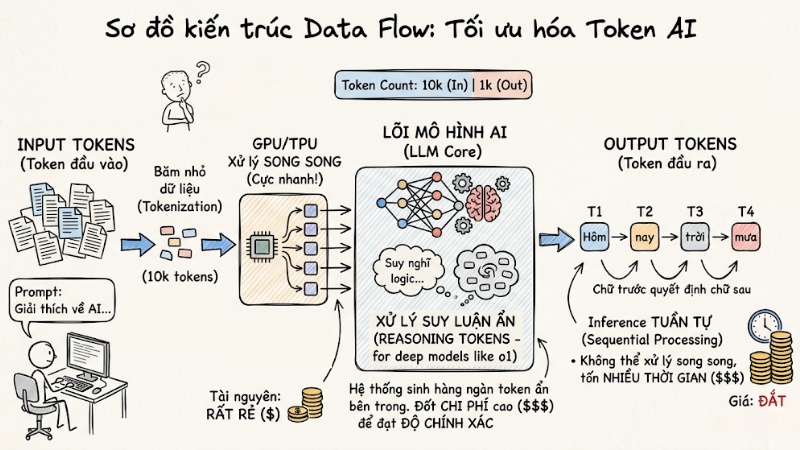
đồ kiến trúc Data Flow mô tả Input xử lý song song đi qua LLM và xuất Output tuần tự
Context Window (Giới hạn ngữ cảnh)
Context window là giới hạn tổng số lượng token (bao gồm cả Input và Output) mà AI có thể ghi nhớ trong một phiên làm việc. Hiện tại, các model như Claude 3.5 Sonnet hỗ trợ lên tới 200k tokens.
Lưu ý kỹ thuật: Không nên tận dụng tối đa Context window nếu không cần thiết. Khi bạn nhồi nhét quá nhiều tài liệu vào một prompt, các mô hình LLM thường gặp hiện tượng "Lost in the middle" (Ảo giác bỏ sót thông tin) - AI có xu hướng ghi nhớ tốt phần đầu và phần cuối tài liệu, nhưng quên mất thông tin quan trọng nằm ở giữa.
Cách tối ưu hóa chi phí token khi triển khai thực tế
Để tránh việc ngân sách API "bốc hơi" ngoài tầm kiểm soát khi scale up ứng dụng, đội ngũ phát triển cần áp dụng các kỹ thuật sau:
- Prompt engineering tối giản: Viết câu lệnh súc tích, đi thẳng vào vấn đề. Loại bỏ các từ nối và câu chào hỏi thừa thãi (ví dụ: "Làm ơn hãy...", "Chào AI") để tiết kiệm token đầu vào.
- Cắt tỉa lịch sử hội thoại: Thay vì gửi lại toàn bộ cuộc hội thoại dài 50 tin nhắn cho mỗi lần gọi API, hãy thiết lập logic ở backend chỉ giữ lại 5-10 tin nhắn gần nhất chứa context cốt lõi.
- Tích hợp Prompt Caching: Đây là kỹ thuật "vũ khí hạng nặng" hiện nay. Bằng cách lưu vào bộ nhớ đệm các context lặp lại (ví dụ: system prompt phức tạp hoặc file tài liệu RAG), bạn có thể giảm đến 90% chi phí Input token và đưa độ trễ Time-to-first-token về gần bằng 0.
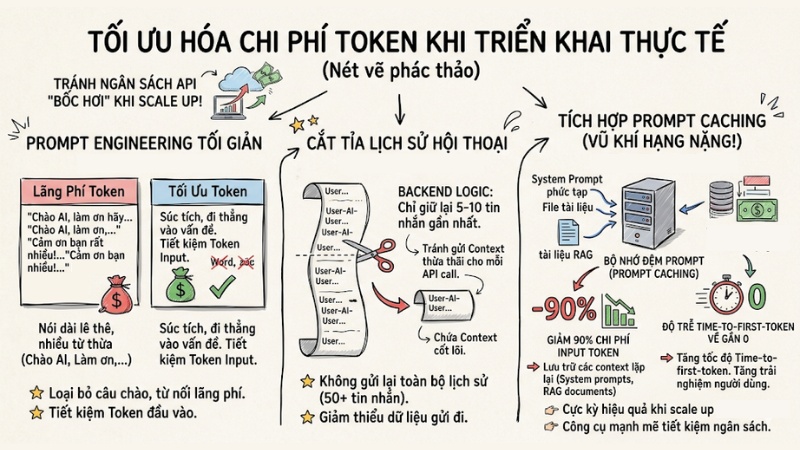
Cách tối ưu hóa chi phí token khi triển khai thực tế
Câu hỏi thường gặp về token trong AI
Token trong AI là gì?
Trong AI, token là đơn vị dữ liệu nhỏ nhất mà mô hình ngôn ngữ lớn (LLM) sử dụng để xử lý văn bản. Thay vì đọc từ ngữ, mô hình băm nhỏ dữ liệu thành các đoạn mã số học để tính toán xác suất và dự đoán nội dung.
Tại sao tiếng Việt lại tốn nhiều token hơn tiếng Anh?
Do hầu hết các mô hình AI được huấn luyện chủ yếu trên bộ dữ liệu tiếng Anh, tokenizer gặp khó khăn khi xử lý cấu trúc ngôn ngữ tiếng Việt. Kết quả là một từ tiếng Việt thường bị băm thành 2-3 tokens, khiến chi phí API tăng lên đáng kể.
Sự khác biệt giữa Input token và Output token là gì?
Input token là dữ liệu bạn gửi vào để AI xử lý (xử lý song song, chi phí thấp). Output token là kết quả AI sinh ra, từng từ một theo trình tự (xử lý tuần tự, chi phí cao hơn và yêu cầu tài nguyên tính toán lớn hơn).
Làm thế nào để ước lượng chi phí token cho ứng dụng?
Quy tắc ước lượng chi phí token là: 1 từ tiếng Anh tương đương khoảng 1 token, trong khi 1 từ tiếng Việt trung bình chiếm 1.5 đến 2 tokens. Bạn nên cộng thêm 20% dung lượng dư để dự phòng cho các yêu cầu hệ thống và lịch sử hội thoại.
Context Window là gì và tại sao cần chú ý?
Context Window là giới hạn tối đa số lượng token mà một mô hình có thể ghi nhớ trong một phiên làm việc. Khi vượt quá giới hạn này, AI sẽ quên các thông tin ở giữa hoặc đầu đoạn hội thoại, hiện tượng này gọi là "Lost in the middle".
Prompt Caching là gì và có giúp giảm chi phí không?
Prompt Caching là kỹ thuật lưu trữ các phần prompt cố định (như system prompt hoặc tài liệu dài) vào bộ nhớ đệm. Thay vì xử lý lại từ đầu, AI tái sử dụng dữ liệu này, giúp giảm tới 90% chi phí và tăng tốc độ phản hồi.
Làm sao để tối ưu hóa số lượng token sử dụng?
- Viết prompt súc tích và lược bỏ các từ ngữ thừa.
- Chỉ gửi lại những đoạn lịch sử hội thoại quan trọng nhất.
- Sử dụng Prompt Caching cho các dữ liệu đầu vào lặp lại.
- Chọn mô hình có tokenizer hiệu quả với ngôn ngữ mục tiêu.
Xem thêm:
- Machine Learning là gì? Nguyên lý và các ứng dụng thực tế
- MCP Transport là gì? Tìm hiểu cơ chế truyền tải của Model Context Protocol
- Orchestration Layer là gì? Tìm hiểu tầm quan trọng trong hệ thống
Về bản chất, token là "nhiên liệu" vận hành của mọi mô hình học máy. Việc thấu hiểu cơ chế Tokenization, sự chênh lệch chi phí ngôn ngữ và tối ưu hóa luồng Input/Output không chỉ là kiến thức lý thuyết, mà còn là kỹ năng sống còn của các Data Scientist và Backend Developer hiện đại để đảm bảo hiệu năng hệ thống (ROI).