Machine Learning là gì? Nguyên lý và các ứng dụng thực tế

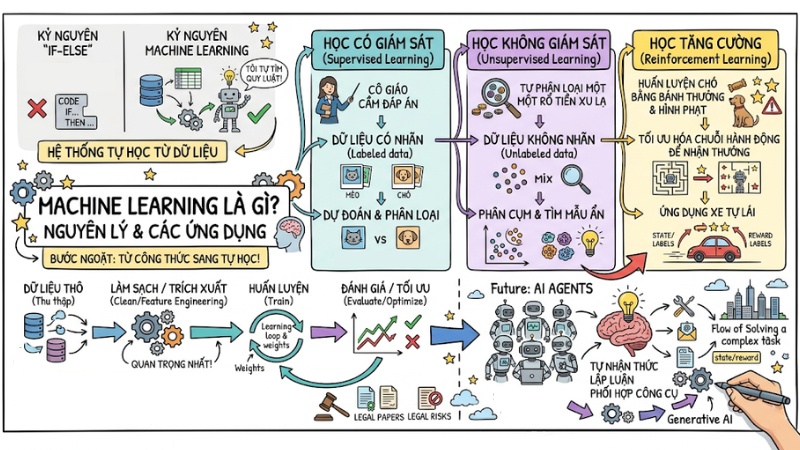
Machine Learning là bước ngoặt giúp phần mềm bước ra khỏi kỷ nguyên lập trình thuần if-else, nơi mọi quy tắc đều phải được con người viết tay. Thay vì cố gắng mã hóa hết sự phức tạp của thế giới thực, Machine Learning cho phép hệ thống tự học và tự nhận diện khuôn mẫu từ dữ liệu. Bài viết này sẽ tập trung giải thích rõ Machine Learning là gì, dữ liệu được “biến” thành sự thông minh ra sao và những thuật toán cốt lõi đứng sau các ứng dụng AI hiện đại.
Những điểm chính
- Bản chất Machine Learning: Hiểu rõ ML là bước chuyển dịch từ kỷ nguyên lập trình dựa trên quy tắc sang kỷ nguyên tự học từ dữ liệu, cho phép hệ thống tự tìm ra quy luật thay vì con người định nghĩa sẵn.
- Phân tầng công nghệ: Phân định chính xác ranh giới giữa AI, Machine Learning và Deep Learning để áp dụng đúng công cụ cho bài toán cụ thể.
- Quy trình Pipeline chuẩn mực: Nắm vững 4 bước từ thu thập, làm sạch/trích xuất (Feature Engineering), huấn luyện, đánh giá/tối ưu.
- Nguyên lý vận hành: Hiểu rõ triết lý "Garbage In, Garbage Out" và tầm quan trọng của việc kiểm soát Data Bias để tránh các quyết định thiên lệch, rủi ro pháp lý và sai sót hệ thống.
- Ba phương pháp học máy chủ đạo:
- Supervised Learning: Học có nhãn (như cô giáo cầm đáp án), dùng để dự đoán/phân loại.
- Unsupervised Learning: Học không nhãn, dùng để phân cụm/tìm mẫu ẩn.
- Reinforcement Learning: Học tăng cường (thưởng/phạt), dùng để tối ưu chuỗi quyết định/tự hành (xe tự lái).
- Tương lai AI Agents: Nắm bắt sự chuyển dịch từ ML phân tích truyền thống sang Generative AI và kiến trúc AI Agents – những hệ thống có khả năng tự nhận thức, lập luận và phối hợp công cụ để giải quyết quy trình nghiệp vụ phức tạp.
- Giải đáp FAQ: Làm rõ vai trò của MLOps trong việc duy trì hiệu suất mô hình, cách lựa chọn thuật toán phù hợp và tại sao kỹ năng tiền xử lý dữ liệu (Feature Engineering) lại quan trọng nhất.
Machine Learning là gì? Chấm dứt kỷ nguyên lập trình "If-Else"
Machine Learning (Học máy) là một tập con của Trí tuệ nhân tạo (AI), cho phép hệ thống tự động học hỏi và cải thiện từ kinh nghiệm mà không cần được lập trình rõ ràng cho từng tác vụ. Cụ thể, hệ thống sẽ tự tìm ra quy luật từ dữ liệu để đưa ra dự đoán.
Trong cấu trúc lập trình cũ, con người cung cấp dữ liệu (Data) và quy tắc (Rule/Logic) để máy tính xử lý và trả về kết quả. Nhưng với Machine Learning, tư duy kiến trúc này bị đảo ngược hoàn toàn: Kỹ sư phần mềm chỉ cần cung cấp dữ liệu và kết quả mong muốn, máy tính sẽ tự động chạy thuật toán để tìm ra các quy tắc. Sự chuyển dịch từ Rule-based sang Data-driven đã giải quyết được những bài toán phi cấu trúc mà code thuần không thể xử lý.
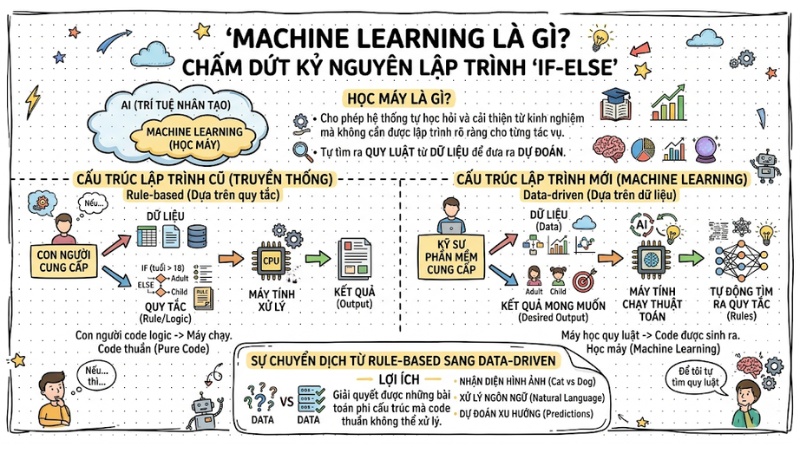
Machine Learning (Học máy) là một tập con của trí tuệ nhân tạo (AI)
Phân biệt AI, Machine Learning và Deep Learning
Để tránh sự nhầm lẫn về thuật ngữ khi làm việc, chúng ta cần phân định rõ ràng các lớp công nghệ:
- Trí tuệ nhân tạo (Artificial Intelligence): Là khái niệm bao trùm rộng nhất, mô tả bất kỳ hệ thống máy tính nào có khả năng bắt chước trí thông minh của con người. Một hệ thống chatbot trả lời theo kịch bản có sẵn cũng được coi là AI.
- Máy học (Machine Learning): Là một phân nhánh cốt lõi của Artificial Intelligence, sử dụng các phương pháp toán học và thống kê để máy móc tự "học" và nâng cao độ chính xác dựa trên dữ liệu thực tế.
- Học sâu (Deep Learning): Là tập con chuyên sâu của học máy. Phương pháp này lấy cảm hứng từ mạng lưới thần kinh sinh học thông qua các mạng nơ-ron nhân tạo, chuyên xử lý các tác vụ siêu phức tạp như nhận diện giọng nói hay thị giác máy tính.
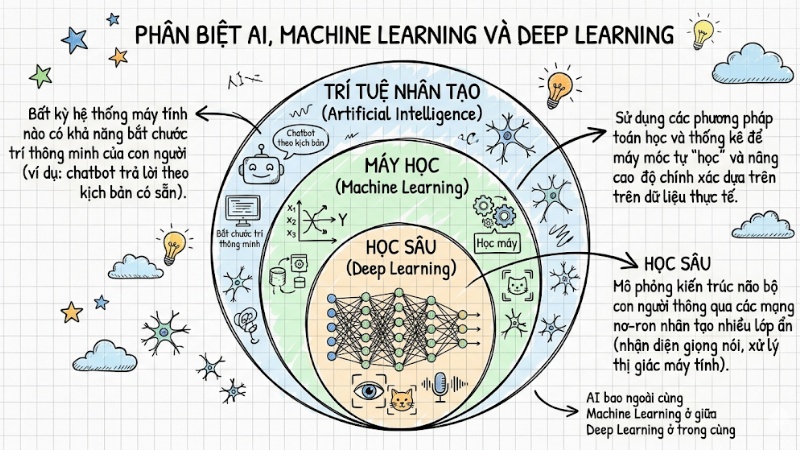
Phân biệt AI, Machine Learning và Deep Learning
Tìm hiểu quy trình Machine Learning Pipeline
4 bước cốt lõi của quy trình Machine Learning Pipeline như sau:
- Thu thập dữ liệu: Gom dữ liệu thô từ nhiều nguồn.
- Tiền xử lý dữ liệu: Làm sạch và trích xuất đặc trưng.
- Huấn luyện mô hình: Chạy thuật toán để máy học quy luật.
- Đánh giá và tối ưu: Đo lường sai số và tự sửa sai.
Quy trình này chính là xương sống vận hành của mọi dự án Data Science. Thực tế triển khai cho thấy, phần lớn nỗ lực và thời gian của các kỹ sư không dành cho việc tinh chỉnh model, mà nằm trọn ở bước kỹ thuật trích xuất đặc trưng. Dữ liệu thô thu thập được từ hệ thống thường rất lộn xộn, thiếu sót hoặc chứa nhiều nhiễu. Nếu không được chuẩn hóa định dạng và làm sạch đúng cách, mô hình toán học sẽ không thể xử lý.
Sau khi chuẩn bị xong tập dữ liệu huấn luyện chất lượng, thuật toán bắt đầu quá trình học. Bản chất của việc "học" chính là việc hệ thống liên tục tính toán Loss function để đo lường khoảng cách giữa kết quả dự đoán và thực tế. Nhờ cơ chế này, mô hình tiến hành tối ưu hóa thuật toán, tự động cập nhật các trọng số lặp đi lặp lại cho đến khi sai số được triệt tiêu xuống mức thấp nhất cho phép.
Nguyên lý "Garbage In, Garbage Out" và vấn đề Data Bias
Nguyên lý "Rác vào, Rác ra" (Garbage In, Garbage Out) trong hệ thống dữ liệu chỉ ra rằng: Một kiến trúc model dù có thiết kế tối ưu đến đâu, nếu được nuôi bằng nguồn dữ liệu rác, kết quả dự đoán trả về hoàn toàn vô giá trị.
Nghiêm trọng hơn, nếu tập Training data của bạn chứa những định kiến ngầm (Data Bias) về giới tính, chủng tộc, hay hành vi khách hàng, hệ thống học máy không những học theo mà còn khuếch đại định kiến đó lên quy mô lớn, tạo ra những quyết định thiên lệch gây rủi ro pháp lý cho doanh nghiệp.
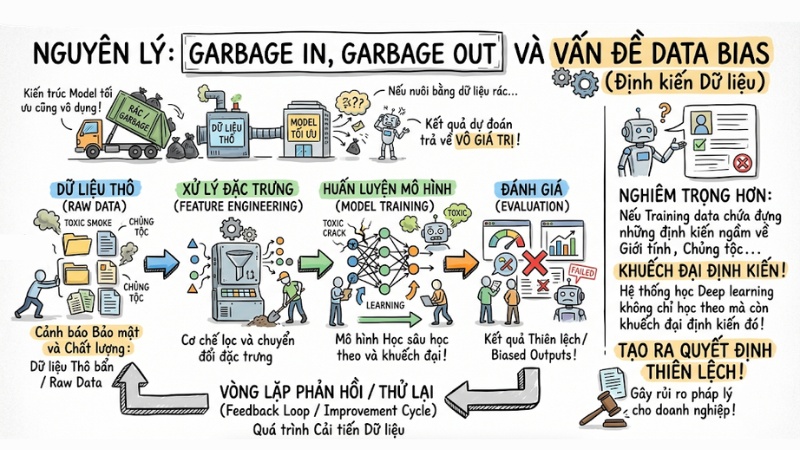
Nguyên lý "Garbage In, Garbage Out" và vấn đề Data Bias
3 phương pháp học máy phổ biến nhất
| Tiêu chí | Supervised Learning (Học có giám sát) | Unsupervised Learning (Học không giám sát) | Reinforcement Learning (Học tăng cường) |
|---|---|---|---|
| Loại dữ liệu | Có gắn nhãn (Labeled data). | Không gắn nhãn (Unlabeled data). | Trạng thái và môi trường (State/Environment). |
| Mục tiêu cốt lõi | Ánh xạ đầu vào/đầu ra, phân loại. | Tìm cấu trúc ẩn, phân cụm. | Tối ưu hóa chuỗi hành động để nhận thưởng. |
| Ví dụ ẩn dụ | Cô giáo cầm sẵn đáp án chấm điểm. | Tự phân loại một rổ tiền xu lạ. | Huấn luyện chó bằng bánh thưởng và hình phạt. |
Supervised Learning (Học có giám sát)
Thuật toán được cấp một tập Training data đã có sẵn nhãn (đáp án đúng) để tìm ra hàm ánh xạ từ đầu vào đến đầu ra. Cơ chế này giống hệt như một "Cô giáo cầm sẵn đáp án chấm điểm".
Bạn đưa cho máy tính 10,000 bức ảnh, mỗi bức đều được kỹ sư dán nhãn rõ ràng là "Spam" hoặc "Bình thường". Máy tính sẽ trích xuất các đặc trưng chung của ảnh Spam. Khi đưa một hình ảnh hoàn toàn mới vào, nó vận dụng kiến thức "cô giáo" đã dạy để đưa ra dự đoán phân loại.
Use Case: Ứng dụng để xây dựng bộ lọc Spam Email doanh nghiệp, hoặc thiết lập mô hình hồi quy (Regression) dự đoán giá bất động sản dựa trên diện tích và vị trí địa lý.
Unsupervised Learning (Học không giám sát)
Ở phương pháp này, thuật toán làm việc với khối lượng dữ liệu thô hoàn toàn không có nhãn, tự động rà soát để tìm ra các cấu trúc, mẫu (pattern) hoặc mối liên hệ ẩn giấu bên trong.
Hãy tưởng tượng bạn ném cho hệ thống bài toán: "Tự phân loại một rổ tiền xu lạ dựa trên kích thước/màu sắc" mà không hề cho biết mệnh giá hay nguồn gốc của chúng. Dựa trên sự tương đồng về đường kính và chất liệu kim loại, thuật toán tự động gom các đồng xu thành từng cụm riêng biệt một cách logic.
Use Case: Chạy các thuật toán K-Means Clustering để phân cụm khách hàng cho phòng Marketing, hoặc phát hiện giao dịch bất thường trong hệ thống thẻ tín dụng mà không cần định nghĩa trước "bất thường" là gì.*
Reinforcement Learning (Học tăng cường)
Đây là kỹ thuật phức tạp nhất, nơi mô hình (được gọi là Agent) tự học cách đưa ra quyết định thông qua việc tương tác trực tiếp với một môi trường mô phỏng.
Quá trình này hoàn toàn tương đồng với việc "Huấn luyện chó bằng bánh thưởng và hình phạt". Nếu Agent thực hiện một hành động đúng hướng (ví dụ: rẽ phải để tránh vật cản), hệ thống trao điểm thưởng (Reward). Nếu làm sai, nó nhận điểm trừ (Penalty). Thông qua hàng triệu lần thử và sai, hệ thống liên tục tối ưu thuật toán để tìm ra chuỗi hành động tối ưu nhất.
Use Case: Triển khai thuật toán điều hướng cho xe tự lái, tối ưu hóa quá trình xếp dỡ hàng hóa trong chuỗi cung ứng, hoặc phát triển bot AI chơi cờ tướng/cờ vây.

Các phương pháp học máy phổ biến nhất
Từ Machine Learning dự đoán đến kỷ nguyên AI Agents
Trong suốt nhiều thập kỷ, Machine Learning truyền thống tập trung giải quyết xuất sắc các bài toán phân tích, dự đoán rủi ro và phân loại nội dung. Tuy nhiên, kiến trúc hệ thống đang chứng kiến một cuộc cách mạng lớn. Sự trỗi dậy của các mô hình ngôn ngữ lớn (LLMs) dựa trên cơ chế Transformer đã mở ra kỷ nguyên Generative AI - nơi máy móc không chỉ dự đoán mà còn có khả năng tự sáng tạo văn bản, code và hình ảnh.
Khi số lượng tham số của mô hình ngày càng lớn, việc duy trì cơ sở hạ tầng trở thành một bài toán đau đầu về MLOps. Hơn thế nữa, xu thế của các doanh nghiệp Tech hiện tại không dừng lại ở việc gọi API từ một mô hình đơn lẻ. Thay vào đó, họ tập trung xây dựng kiến trúc AI Agents - những thực thể phần mềm có khả năng tự nhận thức ngữ cảnh, tự đưa ra suy luận logic, tự động gọi công cụ bên ngoài (Tool calling) và phối hợp làm việc nhóm để giải quyết các quy trình nghiệp vụ dài hơi.
Câu hỏi thường gặp về Machine Learning
Machine Learning khác gì với AI truyền thống?
AI là lĩnh vực rộng bao gồm mọi kỹ thuật giúp máy tính mô phỏng trí tuệ con người. Machine Learning (Học máy) là tập con của AI, tập trung vào các thuật toán tự học từ dữ liệu thay vì tuân theo các quy tắc "nếu-thì" (if-else) được lập trình cứng.
Tại sao 80% công việc của Data Scientist là Feature Engineering?
Chất lượng mô hình ML phụ thuộc hoàn toàn vào dữ liệu đầu vào. Bước xử lý giúp chọn lọc, làm sạch và định dạng dữ liệu sao cho thuật toán dễ dàng nhận diện mẫu. Nếu dữ liệu đầu vào là "rác", kết quả đầu ra sẽ vô giá trị.
Khi nào nên chọn Supervised Learning thay vì Unsupervised Learning?
Chọn Supervised Learning khi bạn có bộ dữ liệu đã được dán nhãn (có kết quả mục tiêu) để dự đoán giá trị hoặc phân loại chính xác. Chọn Unsupervised Learning khi dữ liệu chưa được dán nhãn và bạn cần máy tự tìm ra cấu trúc ẩn hoặc phân nhóm.
Reinforcement Learning thường được ứng dụng trong lĩnh vực nào?
Reinforcement Learning cực kỳ hiệu quả trong các môi trường đòi hỏi sự tự chủ và chuỗi quyết định liên tục như xe tự lái, tối ưu hóa chuỗi cung ứng, hệ thống giao dịch tài chính tự động hoặc điều khiển robot dựa trên cơ chế thử và sai.
Tại sao cần quan tâm đến MLOps khi triển khai hệ thống AI?
MLOps giúp chuẩn hóa quy trình từ thu thập, huấn luyện đến triển khai và giám sát mô hình. Việc này đảm bảo mô hình không bị suy giảm hiệu suất sau khi ra môi trường thực tế, đồng thời giúp quản lý tài nguyên hệ thống một cách hiệu quả.
Xem thêm:
- MCP Transport là gì? Tìm hiểu cơ chế truyền tải của Model Context Protocol
- Orchestration Layer là gì? Tìm hiểu tầm quan trọng trong hệ thống
- No-code là gì? Cơ hội, rủi ro và trường hợp nên ứng dụng
Machine Learning vẫn là bộ máy tính toán cốt lõi đứng sau mọi ứng dụng thông minh hiện nay. Việc nắm vững cách thiết lập Data Pipeline, phân biệt rõ các loại thuật toán học có giám sát hay học tăng cường chính là nền tảng kỹ thuật bắt buộc để các Developer xây dựng được các giải pháp tối ưu.