Shared Memory Multi-Agent: The Most Effective AI Architecture Optimization

Shared Memory Multi-Agent is an architecture that allows multiple AI agents to concurrently read and write to a shared memory space to share context and system state. This article covers the Shared Memory Multi-Agent concept, compares it with Distributed Memory, describes the memory hierarchy architecture, analyzes consistency challenges, and provides a practical implementation example in an Agentic Workflow.
Key Takeaways
- Core Concept: Understand that Shared Memory Multi-Agent is a centralized memory architecture where multiple AI Agents read/write data to a single document, eliminating information fragmentation and maintaining a single source of truth.
- Architecture Comparison: Identify the core differences between Shared Memory and Distributed Memory to help you choose the right architecture for your project's workflow.
- Memory Hierarchy: Explore the standard 3-tier structure consisting of the I/O layer, cache layer, and long-term memory layer, helping the system balance response speed and massive knowledge storage capabilities.
- Practical Application: Discover a real-world example of seamless coordination between an Agent Coder and an Agent Tester via shared memory, significantly saving Context Window space and API costs.
- Conflict Resolution: Master 3 essential tactics to maintain data consistency: strict access control, timestamping, and using a Manager Agent to handle conflicts.
- FAQs: Get answers to questions about storage data formats, the role of MCP in cross-platform integration, and how the system prevents Context Window overflows when sharing memory.
What is Shared Memory Multi-Agent?
Shared Memory Multi-Agent is an architecture where AI agents access a centralized memory space to read and write data, typically implemented on systems like vector databases or graph databases. Instead of each agent keeping its own notes and constantly passing messages back and forth, shared memory acts as a common document, allowing all agents to see the latest state and the system's overall context.
In systems utilizing Large Language Models, shared memory plays a crucial role in reducing pressure on the context window since long-term information, history, and knowledge are stored outside the model. By sharing global state, agents only fetch the necessary data from the centralized context store instead of stuffing the entire history into every prompt, thereby lowering compute costs and improving inference reliability on large datasets.
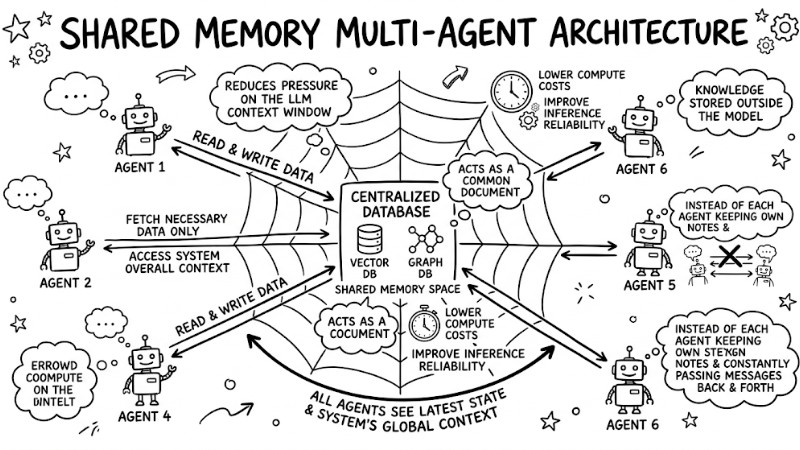
Shared Memory acts as a unified document, allowing all agents to access the latest system state
Comparing the Differences: Shared Memory vs. Distributed Memory
Choosing between a shared or distributed memory architecture directly impacts the performance, deployment complexity, and scalability of a multi-agent system. The table below summarizes some key differences:
| Criteria | Shared Memory | Distributed Memory |
|---|---|---|
| Core Structure | Data is centralized in one or a cluster of repositories acting as the single source of truth for all agents. | Each agent or group of agents maintains its own local repository, typically sharing only aggregated results. |
| Sharing Speed | Agents can read and write to the shared space with low latency, suitable for near real-time coordination. | Information sharing relies on network message passing, adding latency due to transmission and intermediary processing. |
| Conflict Control | Requires strict memory consistency mechanisms and clear read/write rules to prevent overwriting and data inconsistencies. | Higher isolation since each agent writes to its own partition; conflicts mainly arise during synchronization or result merging. |
| Scalability | Risks becoming a bottleneck under heavy concurrent access if clustering and caching aren't properly designed. | Easy to scale horizontally by adding more agents and independent storage nodes, as each component can be distributed. |
| Synchronization Level | Easier to maintain a consistent view of the global state since all agents read from the same central source. | Requires periodic or event-driven synchronization mechanisms to prevent drift between local data replicas. |
Practical Implementer's Perspective:
- Use Shared Memory when: Agents need tight coordination on the same dataset and frequently fetch shared knowledge, such as a team of agents generating code, testing, and analyzing results using a shared knowledge base.
- Use Distributed Memory when: Each agent or cluster of agents handles isolated tasks in different environments and only needs to exchange final results, similar to independent services running in bounded data domains.
Memory Hierarchy Architecture in AI Systems
Modern AI systems don't use a flat memory space; instead, they are organized into multiple tiers to optimize bandwidth and reduce data access latency. Similar to computer hardware architecture, Shared Memory Multi-Agent is typically divided into 3 main layers: the I/O layer, the cache layer, and the long-term memory layer.
Agent I/O Layer
This layer handles the ingestion and output of information between the system and the external environment, such as audio, text, tool results, and network signals. This layer ensures support for heterogeneous data and transforms it into formats that the AI model can process.
Warning: Raw data should not be stored at this layer; instead, it must be filtered, normalized, and only the necessary parts forwarded to the underlying layers to avoid wasting context and causing token overflows.
Agent Cache Layer
This layer stores short-term context that directly serves immediate inference tasks, including compressed context, recent action history, relevant embeddings, and KV cache. By designing a proper cache consistency mechanism across agents, the system can significantly reduce latency when agents need to reuse each other's results or evidence.
Agent Memory Layer
This is a large-capacity, persistent storage layer used to retain full conversation histories, documents, knowledge bases, and other forms of long-term memory. This layer typically utilizes vector databases like Pinecone, Milvus, or Weaviate for efficient indexing and querying based on semantic similarity between embeddings.
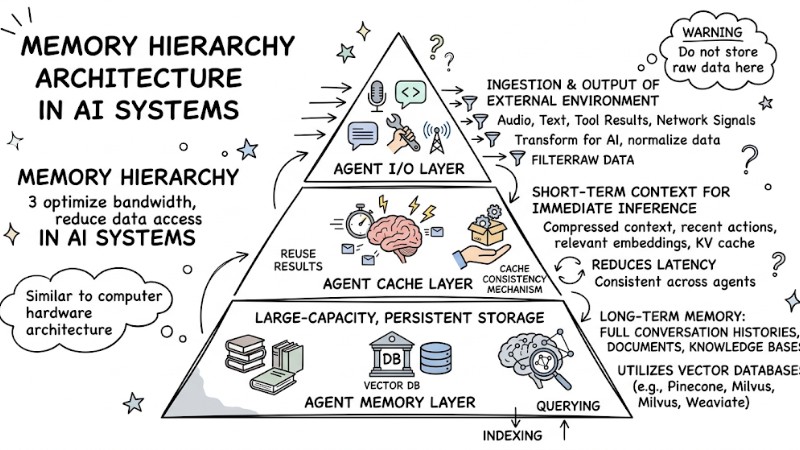
Memory Hierarchy Architecture in AI Systems
Practical Example: Shared Memory in an Agentic Workflow
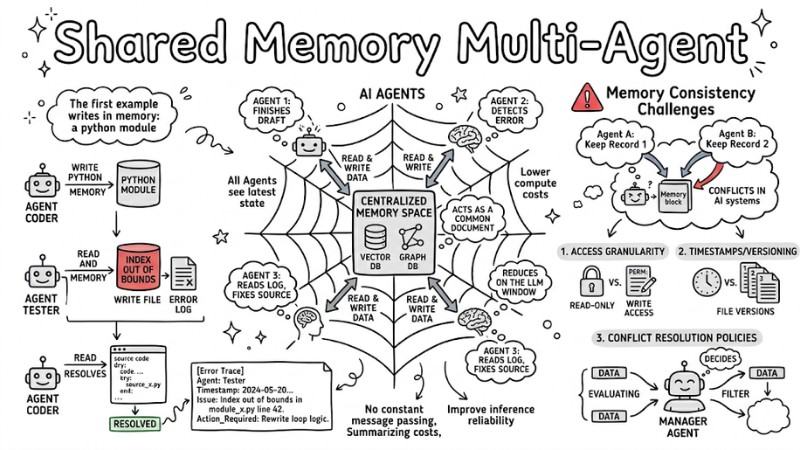
Suppose you are building an Agentic Workflow consisting of an Agent Coder and an Agent Tester. Instead of passing source code back and forth via APIs, Shared Memory allows setting up a shared memory space for the agent group through the following steps:
- Agent Coder finishes writing a Python module and writes the draft into Shared Memory.
- Agent Tester receives an activation signal and directly fetches the newly saved module from the shared memory.
- Agent Tester runs tests, detects an error, and writes the test log to the same memory block.
[Error Trace]
Agent: Tester
Timestamp: 2024-05-20T10:00:00Z
Issue: Index out of bounds in module_x.py line 42.
Action_Required: Rewrite loop logic.
- Agent Coder reads the error log in the shared memory, fixes the source code, and updates the status to "RESOLVED".
This model creates Dynamic Reasoning Alignment, meaning both agents consistently share the same source code context and don't need to burn tokens summarizing or re-explaining the steps the other agent just took.
The Biggest Challenge: Memory Consistency and How to Handle It
Managing Memory Consistency is a critical technical hurdle in multi-agent systems. Unlike traditional databases, conflicts in AI systems aren't just about technical data overwrites, but also contradictions in content and semantics. If two agents generate conflicting conclusions and write them both to memory, the entire system's state can become skewed and hard to control.
To manage state conflicts within the Shared Memory of a Multi-Agent system, you can immediately apply the following three solution groups:
Access granularity
Enforce clear permissions for each type of agent, determining which agents are read-only and which have write access. Establish a Core Memory zone that only allows highly privileged agents to write directly, blocking low-level sub-agents from modifying content in this area.
Timestamps/Versioning
Every new record must be tagged with a timestamp and version to track how information mutates over time. Semantic versioning strategies can be applied so that downstream agents querying the data always recognize the latest reasoning flow and avoid reusing stale context.
Conflict resolution policies
Designate a Manager Agent to act as an evaluation and filtering layer when contradictions occur. When two opposing data streams emerge, the Manager Agent evaluates the reliability, recording time, and source priority to decide which record to keep and which outdated record to discard.
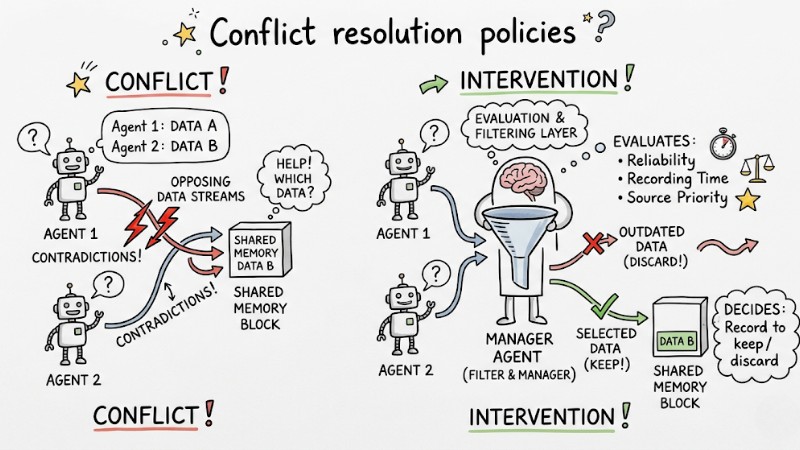
When two agents attempt to write to the same memory cell, a filter intervenes to orchestrate the flow
FAQs on Shared Memory Multi-Agent
What data formats does Shared Memory use in AI systems?
Shared Memory typically stores data as text, structured logs like JSON or XML, SQL queries, and notably vector embeddings in a shared vector database accessible by multiple agents.
When is my project required to use Shared Memory?
Your project should leverage Shared Memory when the system requires a shared knowledge base for multiple agents, and when several agents must concurrently manipulate complex datasets like code repositories or financial reports.
How does the Model Context Protocol (MCP) relate to Shared Memory?
The Model Context Protocol is an open-source connection standard that helps agents share context and data uniformly, thereby shaping how Shared Memory is accessed and utilized within a multi-agent system.
How does MCP support shared memory across different providers?
MCP enables agents from different model providers, such as OpenAI or Anthropic, to connect to the same shared context layer and access shared memory via a standardized protocol.
How does the system prevent Context Window overflows when sharing memory?
The system uses a local knowledge access mechanism via vector retrieval to load only the most relevant vectors into the current context, combined with summarization algorithms to compress and truncate old context.
Read more:
- AI Agent Orchestration: 6 Optimal System Design Patterns
- Multi-Agent Architecture: 4 Core Models and Practical Applications
- AI Agent Architecture: A Comprehensive Developer's Guide
Shared Memory Multi-Agent provides a centralized memory foundation that helps agents coordinate on the same knowledge base, optimize the Context Window, and reduce inference costs on large datasets. When combining a memory hierarchy architecture, efficient vector retrieval mechanisms, and clear conflict management policies, multi-agent systems can scale reliably and maintain inference quality across complex production scenarios.