What is Agent Engineering? The Process of Bringing AI Agents into Production

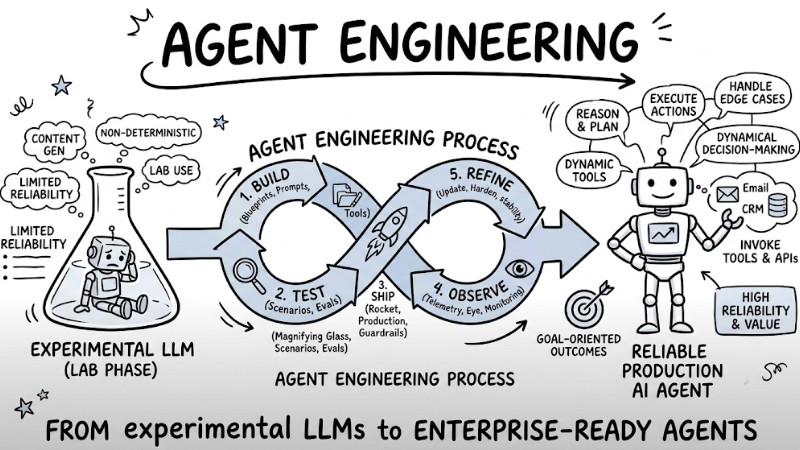
Agent Engineering is an engineering discipline focused on transforming large language models into autonomous, reliable AI Agent systems tailored for real-world enterprise production environments. This article helps you understand the role of Agent Engineering, its core architectural components, the 5-step build pipeline, and the skillset required to ship AI Agents into production.
Key Takeaways
- Agent Engineering Concept: Understand that this is a deep engineering pipeline that transforms raw large language models into autonomous, stable AI Agents ready to run in enterprise environments.
- Core Differences: Clearly distinguish the non-deterministic flexibility of AI Agents from the rigid programming mindset of traditional software, helping you approach system architecture correctly.
- Core Architecture: Identify the 4 essential components that form a complete AI Agent: the planning reasoning core, memory system, APIs, and orchestration layer.
- Battle-tested Pipeline: Master the 5-step loop utilizing the "Ship to learn" principle, helping you continuously iterate and boost AI Agent reliability using real-world data.
- The Agent Engineer Persona: Understand that this role demands a seamless blend of 3 skill sets: Product thinking, Software engineering, and Data science.
- FAQ: Get answers regarding the differences between RAG and AI Agents, how to tame AI unpredictability via Human-in-the-loop mechanisms, and learning roadmaps to become an Agent Engineer.
What is Agent Engineering?
Agent Engineering is an engineering discipline focused on taking Large Language Model (LLM) based systems from the experimental phase to official deployment as AI Agents in production environments. This is a highly iterative process involving build, test, ship, observe, and refine loops aimed at achieving high reliability when the system interacts with real users.
In real-world usage, users can input various types of requests, and an AI Agent must not only generate answers but also plan, invoke tools, and execute actions on interconnected systems. Because AI Agents possess read/write access to data, a well-architected system can drive massive enterprise value, whereas an uncontrolled system can cause data loss or corruption in a matter of seconds.
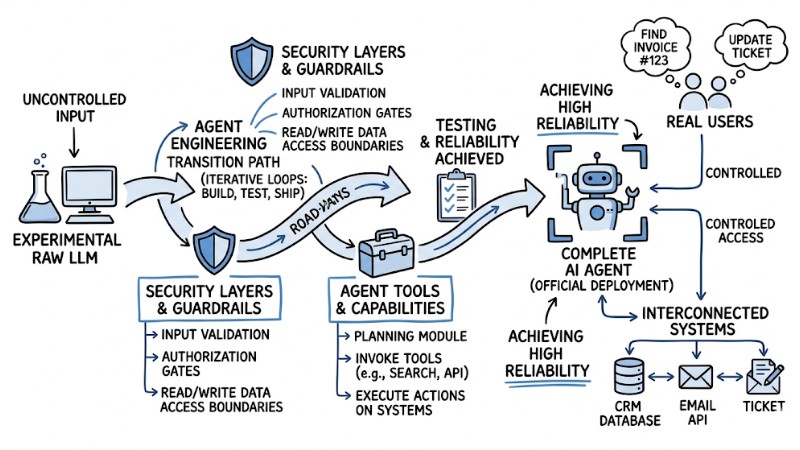
The transition from a raw LLM to a complete AI Agent in a Production environment
The Difference Between Traditional Software and AI Agents
Traditional software adheres to the Software Development Life Cycle (SDLC) with a rigid rule set, where inputs and outputs are pre-designed and rarely mutate during runtime.
Conversely, an AI Agent is a non-deterministic system, operating on dynamic logic flows and continuously adapting to natural language. Therefore, if you try to force hard-coded if-else logic onto the Agent's entire behavior, the system will generally fail to achieve the desired stability and scalability.
Comparison Table Traditional Software vs AI Agents:
| Criteria | Traditional Software | AI Agent |
|---|---|---|
| Input | Pre-defined in format and scope, typically static forms, data fields, or UI components. | Primarily natural language, capable of covering diverse contexts and user request types. |
| Execution Flow | Linear, based on pre-programmed logic branches, making it easy to predict data routing through each step. | Capable of dynamic branching based on model reasoning, autonomously selecting tools or subsequent steps to reach the assigned goal. |
| Debugging | Focuses on isolating and patching the faulty line of code or module within a static execution flow. | Requires tracing the LLM's entire reasoning and decision-making chain, including prompts, context, invoked tools, and intermediate payloads. |
| Evaluation | Typically uses clear true/false criteria or pass/fail states for individual functions. | Measured by probability, contextual relevance, safety guardrails, and UX quality, rather than just binary true/false. |
Why is Agent Engineering Becoming Urgent?
Enterprises are entering the development phase of autonomous systems engineering, where AI models possess the capability to reason, plan, and execute actions to pursue defined goals. In this context, Agent Engineering helps architect and operate AI Agents in a controlled manner, aligning with the system architecture and the enterprise's real-world operational constraints.
Modern models like GPT-4 or Claude 3.5 demonstrate that their reasoning and multi-step task processing capabilities are sufficient to handle highly complex workflows, moving far beyond mere content generation. Meanwhile, traditional software relying on rule-based and static logic struggles to meet the demands of agentic workflows, which require continuous exception handling and adaptation to shifting contexts.
Properly adopting Agent Engineering yields three standout advantages for enterprises:
- Scales autonomous decision-making within governed boundaries, drastically reducing the need for manual intervention at intermediate steps and slashing processing times.
- Boosts the ability to handle edge cases that traditional if-else logic fails to cover, via reasoning mechanisms, learning from payloads, and dynamically updating execution strategies over time.
- Drives end-to-end automation for complex business pipelines with a strict monitoring layer and clear risk boundaries, rendering the system both flexible and compliant with safety guardrails.
Core Tech Stack of an AI Agent
A battle-tested tip for the initial phase is to build it as a Minimum Viable Product (MVP) rather than bloating it with overly complex frameworks right out of the gate. A baseline AI Agent can run stably on four core components: goals and planning, memory, tools, and the orchestration layer.
Goals and Planning Capabilities
The LLM acts as the reasoning core, ingesting requests, parsing goals, and decomposing them into actionable steps geared toward goal-oriented execution; meaning every single action is designed to step closer to the defined objective. Within this architecture, the planning block dictates the execution sequence, selects the required tools, and sets the termination conditions for each task.
Memory
Short-term memory helps the Agent maintain context within a single session, while long-term memory persists knowledge, documents, and historical interaction payloads so they can be reused across multiple sessions. Vector databases coupled with Retrieval-Augmented Generation (RAG) techniques are typically deployed to implement the long-term memory layer, allowing the Agent to accurately fetch relevant data chunks on demand.
Tool Use
The tool layer is the interface that empowers the Agent to interact with external systems like APIs, email protocols, databases, or internal microservices. Each tool must be strictly defined with a name, description, and parameters so the LLM can correctly route and invoke the function, for example:
{ "name": "cancel_order", "description": "Cancel user orders based on order code", "parameters": { "type": "object", "properties": { "order_id": { "type": "string" } }, "required": ["order_id"] } }
Orchestration
The orchestration layer is responsible for wiring the LLM, memory, and tools into a unified execution pipeline, ensuring payloads are passed in the exact correct sequence between steps and tools. Dedicated orchestration frameworks and several Agent OS platforms help execute this mission, handling state management, telemetry, logging, and spinning up multiple Agents within a single architecture.
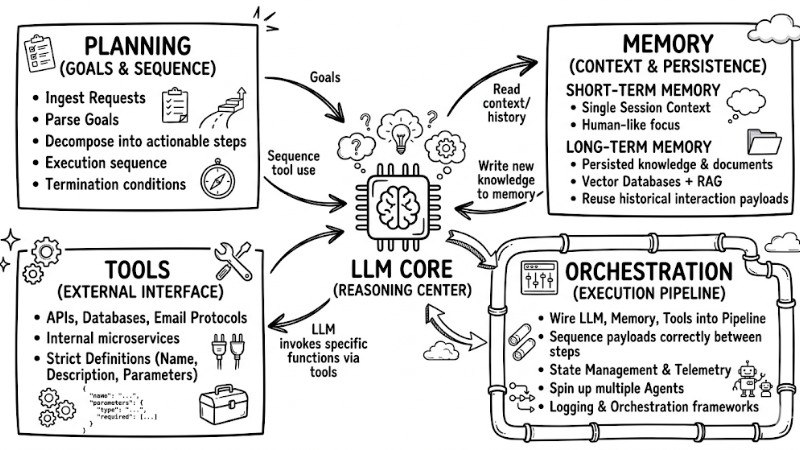
Core Technological Components of an AI Agent
The Standard 5-Step Pipeline for Building Reliable AI Agents
Unlike traditional app development, building AI Agents requires a "ship to learn" mindset, as these are non-deterministic systems where predicting every edge case upfront is virtually impossible. The core value lies in the continuous refinement loop, where every cycle of build, test, ship, observe, and refine makes the Agent vastly more stable and reliable over time.
Step 1: Build
This phase focuses on architecting the Agentic workflow, including strictly defining the inputs, outputs, scope of responsibility, and permission boundaries of the AI Agent within the pipeline. Enterprises utilize prompt engineering to define the desired behaviors, while simultaneously coding and hooking up the required tools and APIs the Agent is authorized to invoke.
Step 2: Test Base Scenarios
In this step, the deployment team builds and runs scenarios mocking the most common user flows, focusing on the happy paths instead of attempting to blanket every edge case. Setting up an automated evaluation pipeline (evals) helps score outputs, catching hallucination bugs and severe logic drifts early before opening the floodgates to real traffic.
Step 3: Ship to Production
The AI Agent is shipped to the production environment under properly scoped guardrails to scrape data on how users actually interact and to log edge cases outside the test suites. In the initial rollout, bugs or unoptimized executions will surface, but the telemetry data from these instances serves as the critical input payload for the next refinement loop.
Step 4: Observe and Monitor
Enterprises configure continuous telemetry systems, logging conversation histories, invoked tools, input parameters, and returned payloads to trace and debug the Agent's decision nodes. For highly sensitive actions like wiring refunds or blasting customer emails, a human-in-the-loop model must be enforced, demanding human approval before execution to cap the risk radius.
Step 5: Continuously Refine
Based on the scraped production data, the engineering team updates prompts, tweaks tool scopes and permissions, and injects fresh data or execution conditions to squash bugs and harden stability. Additionally, you can hook in an output self-validation mechanism before the final response, allowing the Agent to self-audit and patch obvious anomalies during runtime.
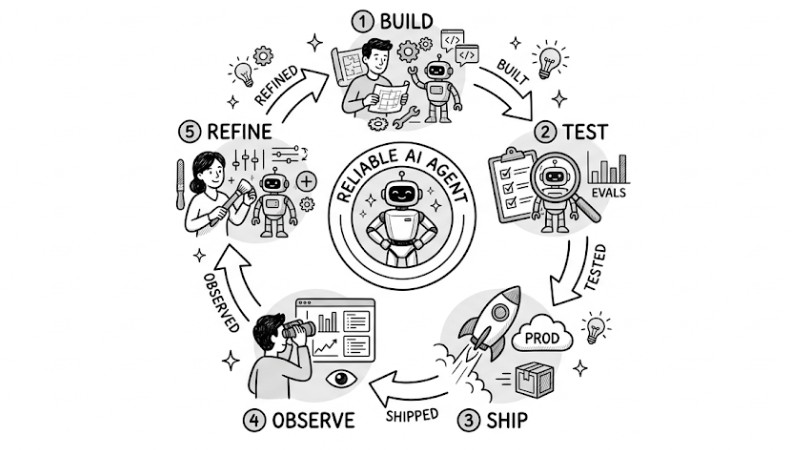
An Effective Workflow for Building AI Agents
The Agent Engineer Persona: 3 Mandatory Skill Sets
An Agent Engineer is not just a code monkey; they deeply understand how AI systems operate, how the product is utilized, and how to bridge both in a live production environment. This role sits at the exact intersection of product thinking, software engineering, and data science, demanding the ability to synergize all three skill sets simultaneously.
Product Thinking
The Agent Engineer must clearly define the user's "job to be done" and translate business specs into a concrete, goal-oriented execution pipeline for the system. Success is benchmarked by the AI Agent fully resolving a specific problem with crystal-clear telemetry metrics, rather than attempting to blanket too many features while lacking execution depth.
Software Engineering Skills
This skill set focuses on architecting AI infrastructure robust enough for long-running tasks, handling exceptions, and ensuring zero downtime when the Agent executes multi-step pipelines over extended periods. The Agent Engineer also needs to grasp integration standards like the Model Context Protocol (MCP) to securely, uniformly, and scalably wire the model to external data and microservices.
Data Science and Analytics Skills
Instead of just viewing bugs as binary true or false, the Agent Engineer must apply probabilistic thinking when evaluating output quality, measuring drift, error frequencies, and the blast radius of specific failures. The ability to engineer evaluation metrics, build Evals pipelines, and crunch user behavioral data forms the foundation for hardening the reliability and performance of AI Agents over time.
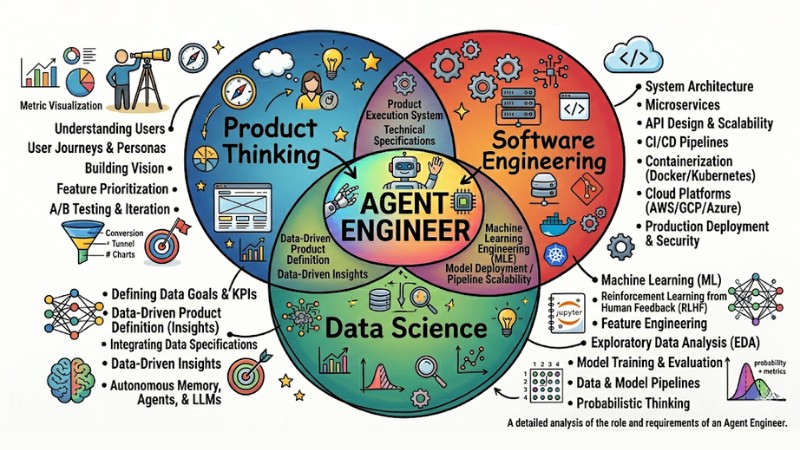
3 Core Skill Groups for Agent Engineering
Frequently Asked Questions
How do RAG and AI Agents differ?
RAG (Retrieval-Augmented Generation) is a technique that helps the model fetch and inject data payloads from a source before generating a response, aiming to boost accuracy and ground it in real-world knowledge. An AI Agent goes much further by using that data to reason, map out multi-step plans, and proactively invoke tools or APIs to execute tasks tied to a defined goal.
How do you control the unpredictability of an AI Agent?
Non-determinism cannot be entirely eliminated, but it can be governed by engineering strict prompts, setting rigid guardrails, and sandboxing the tool scopes the Agent is permitted to use. For high-risk tasks like wiring refunds or blasting critical emails, a human-in-the-loop mechanism should be enforced so the final action must pass a human approval gate before execution.
Will the Agent Engineer role replace Software Engineers?
Agent Engineering is considered a highly specialized branch built on top of the Software Engineering foundation, focusing on architecting and operating probabilistic AI systems capable of planning and tool invocation. In reality, massive-scale multi-agent architectures still critically require software engineers deeply versed in infrastructure, system architecture, and security to build the base layer that dictates the stability of the entire stack.
Where should I start learning to build Agents?
The standard roadmap starts with Prompt Engineering to learn how to explicitly articulate requirements to the model, then utilizing Python to hook into and call APIs from vendors like OpenAI or Anthropic. Next, get your hands dirty with frameworks like LangChain or LlamaIndex to build workflows, pipe in RAG and tools, and incrementally scale up to shipping fully-fledged AI Agents.
Read more:
- Misconceptions about AI Agents: What Enterprises Must Avoid to Maximize Performance
- AI Agents for Enterprise: An A-Z Practical Deployment Roadmap
- When to Use an AI Agent? 7 Signs You Need Automation
Agent Engineering bridges the gap between lab-tested AI models and stable, governed AI Agent systems tightly coupled with concrete business pipelines and goals. Once an enterprise masters Agent architecture, strictly enforces the Build–Test–Ship–Observe–Refine loop, and heavily invests in highly capable Agent Engineers, AI Agents will rapidly morph into a rock-solid automation foundation rather than just a fleeting prototype phase.
Tags