What is an LLM (Large Language Model)? Understanding Large Language Models

Behind answers that seem to possess thought, an LLM is actually just a statistical probability model at a massive scale, operating based on the mechanism of predicting the next token rather than any form of "consciousness." This article focuses on explaining LLMs from a Computer Science perspective: How integer sequences pass through billions of parameters in the Transformer architecture, the memory limits (VRAM) during deployment, and why parallel processing makes Transformers superior to traditional machine learning models.
Key Takeaways
- Technical Nature of LLMs: Properly understand that an LLM is a complex mathematical function based on statistical probability and the Transformer architecture, rather than an entity with human-like consciousness or logical reasoning.
- Operating Mechanism: Master the role of Tokenization (converting text to numbers) and the Transformer architecture with the Self-Attention mechanism (parallel processing, O(1) complexity) which removed the bottleneck of traditional RNN/LSTM models.
- Performance Optimization: Understand the MoE (Mixture of Experts) architecture – a solution that allows a model to have tens of billions of parameters but only activate a small portion during inference, helping optimize VRAM resources and speed.
- LLM Lifecycle: Grasp the differences between Pre-training (foundation learning), Fine-tuning (behavior/format adjustment), and Inference (actual reasoning in Production).
- Real-world Challenges: Confront problems regarding Hallucination, hardware limitations (OOM), Rate Limit errors (429), and operational costs through defensive techniques like RAG and Prompt Caching.
- System Security: Identify critical vulnerabilities when connecting LLMs to internal tools and the mandatory requirement for workspace isolation.
- Future Trends: Shifting from standalone Chatbots to asynchronous coordinated Multi-LLM/AI Agents, using the MCP protocol standard to securely connect with enterprise infrastructure.
- FAQ Resolution: Clarify concepts about hallucinations, the difference between RNN/Transformer, the cost optimization roadmap, and the importance of security in professional AI deployment.
The Essence of LLMs: Concepts and Programming Mental Models
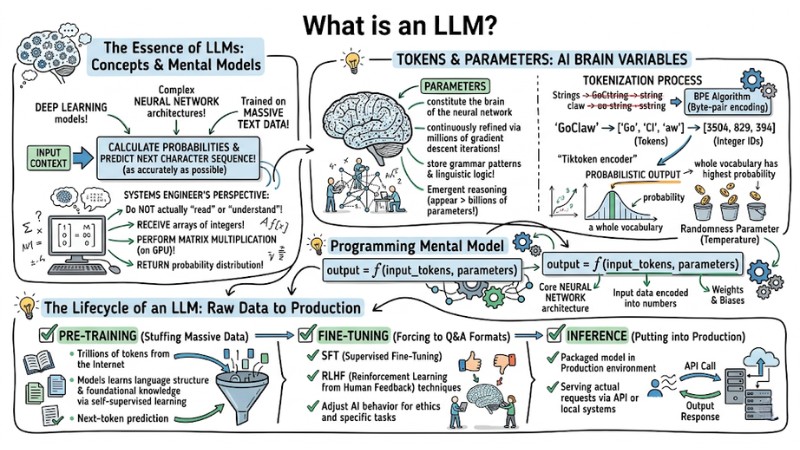
Large Language Models (LLMs) are Deep Learning models featuring complex neural network architectures, trained on massive amounts of text data. The core objective of this system is to calculate probabilities and predict the next character sequence as accurately as possible based on the input context.
From a systems engineer's perspective, language models do not actually "read" or "understand" human language. They receive arrays of integers, perform matrix multiplications on the GPU, and return a probability distribution.
From a programming standpoint, we can model Large Language Models as a basic mathematical function:
output = f(input_tokens, parameters)
In which:
fis the function representing the core neural network architecture.input_tokensis the input data encoded into numbers.parametersare the weights and biases.
Tokens and Parameters: Variables of the AI Brain
Parameters are the variables that constitute the brain of the neural network. They are continuously refined through millions of gradient descent iterations to store grammar patterns and linguistic logic. Emergent reasoning starts to appear when the number of parameters exceeds thresholds of billions or tens of billions.
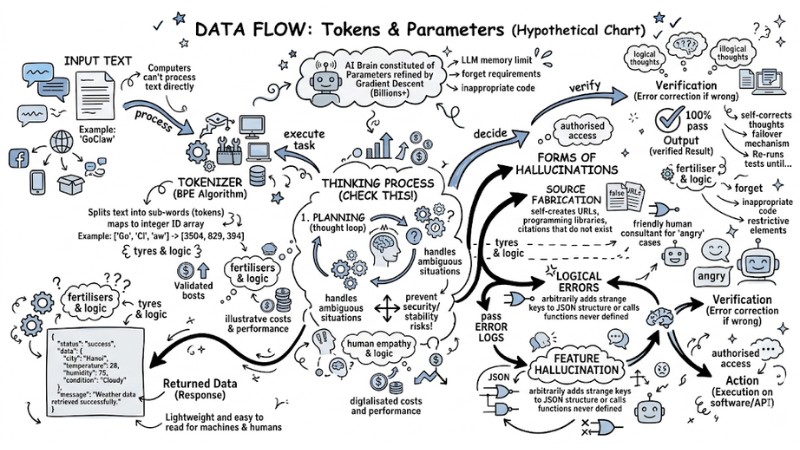
However, computers cannot directly push text strings into these parameters. This is where the Byte-pair encoding (BPE) algorithm enters the Tokenization process.
Example: When using the tiktoken encoder (a popular encoder from OpenAI), the word "GoClaw" might not be processed as a single unit, but split into sub-words (tokens) such as ["Go", "Cl", "aw"]. These are then mapped to an array of integer IDs like [3504, 829, 394].
The system processes this array and returns a Probabilistic output for the entire vocabulary. The final algorithm samples this output to select the next token with the highest probability, influenced by a randomness parameter (temperature).
LLM Tokenization Data flow diagram
Dissecting LLM Architecture: The Dominance of the Transformer
The turning point of modern AI, shaping almost all LLM systems today, began with Google's "Attention Is All You Need" (2017) paper, with the Transformer at the center of this revolution.
The Heart of the System: Self-Attention Mechanism
Before the Transformer era, Recurrent Neural Network (RNN) or LSTM architectures processed data sequentially (one word at a time). This created O(N) time complexity for context processing, making the training process extremely slow, unable to fully exploit parallel computing power, and resulting in long-range context loss.
The Transformer solves this problem using the Self-attention mechanism. It allows processing the entire token sequence in parallel on the GPU with O(1) complexity for sequential transmission operations (although attention matrix multiplication has a cost of O(N²)).
Self-attention works by mapping each token into vector space through 3 weight matrices: Query (Q), Key (K), and Value (V). Below is the pseudo-code simulating the mathematics of this mechanism:
import numpy as np
def scaled_dot_product_attention(Q, K, V, d_k):
# Calculate dot product between Query and Key to find correlation (Scores)
matmul_qk = np.dot(Q, K.T)
# Scale result to prevent large gradients affecting softmax
scaled_attention_logits = matmul_qk / np.sqrt(d_k)
# Apply Softmax to convert into a probability distribution (0 to 1)
attention_weights = softmax(scaled_attention_logits)
# Multiply attention weights with Value to get the final context information
output = np.dot(attention_weights, V)
return output
Comparison Table: RNN vs. Transformer in Language Processing:
| Criteria | Recurrent Neural Network (RNN) | Transformer Architecture |
|---|---|---|
| Data Processing | Sequential - One token at a time | Parallel - Entire sequence at once |
| Long Context Retention | Poor (Prone to Vanishing Gradient) | Excellent (Directly via Self-Attention) |
| GPU Optimization | Low (Loop bottleneck) | Extremely High (Simultaneous matrix calculation) |
| Training Speed | Very slow | Extremely fast at large scale |
Evolution: Mixture of Experts (MoE)
While powerful, the biggest limitation of dense Transformer architecture is the massive computational cost during inference, because every parameter must be activated for every request.
To solve the VRAM and speed issues, the MoE (Mixture of Experts) architecture is applied to modern models like Mixtral or DeepSeek. Instead of using one giant network, MoE splits the model into many "expert" branches.
A routing gate (Router) analyzes the input token and only directs the data flow to the 1-2 most suitable experts. Consequently, a model structured with 56 billion parameters might only need to activate 14 billion parameters during inference, significantly optimizing hardware.
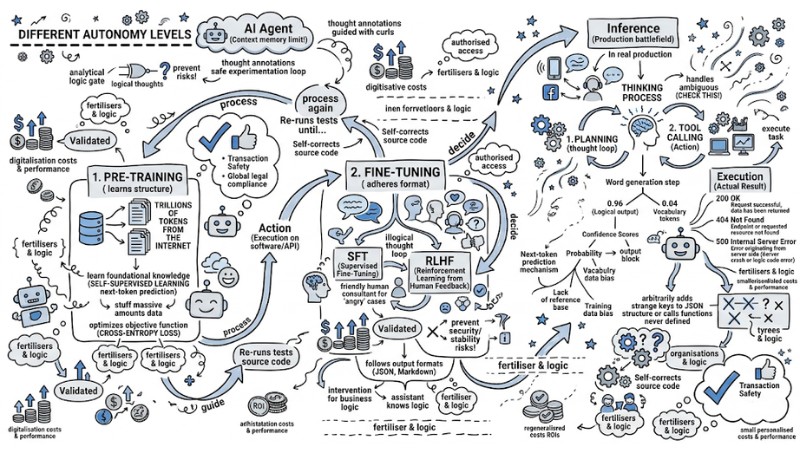
The Lifecycle of an LLM: From Raw Data to Production
To create an AI tool capable of programming, doing math, and summarizing text logically, the system is not just "coded," it must undergo an MLOps pipeline with 3 core stages:
- Pre-training: The stage of "stuffing" massive amounts of data (trillions of tokens) from the Internet so the model learns language structure and foundational knowledge through a self-supervised learning mechanism (next-token prediction).
- Fine-tuning: The stage of forcing the model to adhere to Q&A formats. Using SFT (Supervised Fine-Tuning) and RLHF (Reinforcement Learning from Human Feedback) techniques to adjust AI behavior to suit ethics and specific tasks.
- Inference: The stage of putting the packaged model into a Production environment to serve actual requests via API or local systems.
The Lifecycle of an LLM: From Raw Data to Production
Pre-training
In the Pre-training stage, hardware cost is a harsh physical problem. Optimizing the objective function (usually Cross-Entropy Loss) on hundreds of billions of parameters consumes the power of thousands of H100 GPUs running continuously for months. This is why most businesses will only consume APIs or self-host open-source models instead of training a model from zero.
Fine-tuning
The Fine-tuning stage is where engineers actually intervene so the model can serve business logic. A base model after Pre-training might only know how to continue sentences based on web habits, but after the refinement process, it becomes a virtual assistant that knows how to follow output formats (e.g., JSON, Markdown).
Inference
Finally, the Inference environment is the real battlefield for Developers. The problem here is no longer how smart the model is, but optimizing Latency, Throughput, and strictly managing the Context window to serve tens of thousands of users simultaneously without system crashes.
The Dark Sides of Putting LLMs into Reality (Operational Perspective)
A model that runs excellently in a Lab environment may not necessarily survive when put into Production. Systems engineers frequently face infrastructure and security limits. Specifically:
- Hallucination: By nature, an LLM is a probability calculator; it has no concept of "truth," leading to situations where the AI confidently fabricates information. For practical deployment, RAG architecture is a mandatory requirement. RAG systems use Vector DBs to directly retrieve the most accurate internal documents, then embed them into the context to "force" the LLM to only synthesize answers from this source.
- Rate Limit Errors and Out of Memory (OOM): When sending data sequences that exceed the design limit, the system will return an Out of Memory (VRAM overflow) error. Conversely, if sending large batches of requests via a provider's API, a 429 Too Many Requests error will occur. Engineers must set up retry/backoff mechanisms (retrying with increasing delay) and trim tokens at the backend.
- Cost: The price per 1 million tokens (Input/Output cost) can exceed budgets very quickly in RAG systems processing long documents. Integrating the Prompt Caching mechanism from providers like Anthropic can cut costs by up to 90% by reusing static context chunks.

Terminal console errors 429 OOM
#Error Rate Limit (API Provider)
HTTP/1.1 429 Too Many Requests
Content-Type: application/json
{
"error": {
"message": "Rate limit reached for requests per minute (RPM).",
"type": "requests",
"code": "rate_limit_exceeded"
}
}
# Internal VRAM error (Local Deployment)
RuntimeError: CUDA out of memory. Tried to allocate 2.50 GiB.
GPU 0 has a total capacity of 24.00 GiB of which 1.12 GiB is free.
Process requires 25.30 GiB. Limit context window or apply quantization.
Security Note:
When setting up LLMs with the ability to call external APIs or interact with databases, hackers can exploit Prompt Injection vulnerabilities by inserting hidden commands into input to steal internal System Prompts.
More dangerously, if the model is connected without isolation, it could be manipulated to perform SSRF (Server-Side Request Forgery) attacks, scanning and retrieving data from the enterprise's internal network. Applying strict authorization layers is a prerequisite.
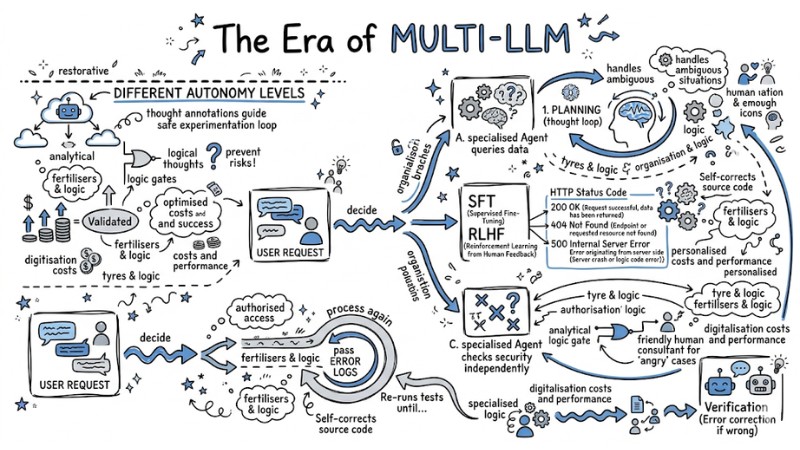
The Future of LLMs: The Era of AI Agents and Multi-LLM
The Era of AI Agents
We are witnessing a powerful shift from static chatbot systems to the Era of Agentic Workflows. The latest generations of Reasoning models have allowed AI to possess chain-of-thought capabilities directly within the architecture.
Instead of answering immediately, they generate hidden tokens to plan, analyze errors, and self-correct before returning the final result, thoroughly solving high-level code and logic problems.
The Era of Multi-LLM
Furthermore, tool integration is no longer manual thanks to the birth of the MCP protocol. MCP provides a unified standard that helps models connect securely to local servers, IDEs, or databases without having to rewrite integration code for each provider.
This shapes the future of Orchestration: A group of specialized AI Agents working asynchronously (Multi-LLM). In that workflow, Agent A is responsible for querying data, Agent B writes the processing code, and Agent C checks security independently.
The Future of LLM: The Era of AI Agents and Multi-LLM
Frequently Asked Questions about LLM
What is an LLM?
A Large Language Model (LLM) is a deep learning model trained on massive datasets to predict the next token in a sequence. The nature of an LLM is not a conscious artificial intelligence, but a complex statistical probability mathematical system.
What is the difference between RNN and Transformer?
RNN processes data sequentially, causing bottlenecks and difficulty remembering long context. In contrast, the Transformer uses the self-attention mechanism to process the entire data sequence in parallel on the GPU, optimizing training performance and capturing superior context.
Why do LLMs experience "hallucinations"?
Since LLMs operate based on the probability of predicting the next word, they prioritize the fluency of text over factual accuracy. If training data is flawed or the input is noisy, the model may confidently generate incorrect information.
How to reduce API costs for LLMs?
You can optimize costs by using the Prompt Caching techniques of providers, or by implementing RAG architecture to leverage internal data instead of requiring the model to remember every piece of information in the prompt.
What is the difference between Pre-training and Fine-tuning?
Pre-training is the stage of teaching the model to understand basic language structure from massive raw data. Fine-tuning is the step of refining a pre-trained model on a specialized dataset to perform specific business tasks accurately.
Why is security important when deploying AI Agents?
AI Agents often access internal systems via APIs or tools. Without security layers like prompt injection protection, SSRF, or workspace isolation (multi-tenant), attackers can exploit the agent to seize system control or leak sensitive data.
Read more:
- Multi-agent vs Single-agent: How to choose the optimal AI architecture
- AI Agents vs Chatbots: Key differences and how to choose the right tool
- How to Choose the Optimal AI Agent Platform for Your Business in 2026
In summary, an LLM is by no means a "thinking entity," but rather the pinnacle of combining the powerful Transformer architecture with large-scale probability processing techniques. Understanding the technical nature from Tokenization and Context Window limits to the Self-attention mechanism helps engineers master system integration, optimize costs, and avoid unfortunate security risks.