What is RAG? A Deep Dive into Retrieval-Augmented Generation

In the era of the LLM explosion, developers are facing two daunting challenges: AI hallucinations and knowledge being "frozen" at the time of training. This is where RAG emerges as an optimal solution: instead of fabricating answers, the model retrieves and extracts information from a specified external data repository, reducing information bias and opening a new generation for automation systems. In this article, we will explore in detail what RAG is and how it operates from a systems perspective.
Key Takeaways
- The Essence of RAG: Understand RAG as an "open-book exam" solution for AI, separating the LLM's reasoning from the data storage to ensure authenticity and reduce hallucinations.
- Standardized 4-Step Process: Master the data pipeline from Ingestion (chunking), Embedding (vector conversion), Retrieval (semantic retrieval), to Generation (context-based generation).
- Data Strategy: Clearly understand the importance of intelligent chunking.
- Semantic Search vs. Keyword Search: Leverage Cosine Similarity to search by true meaning rather than keyword matching, helping the AI understand even ambiguous questions, abbreviations, or slang.
- Distinguishing RAG from Fine-tuning: Define clearly: use RAG for dynamic, real-time knowledge updates; use Fine-tuning to shape tone and niche industry expertise. Combine both when a specialist is needed who understands complex language and has the latest data.
- Risk Management and Security: Confront real-world challenges like cross-data leakage and Prompt Injection attacks by isolating data and establishing strict moderation layers.
- The Future of Agentic RAG: Shifting from linear pipelines to autonomous systems where the AI Agent decides "when to call RAG" and rewrites queries for maximum accuracy.
- FAQ Resolution: Grasp how to optimize costs, multi-user security, and the irreplaceable role of the Vector Database in the RAG era.
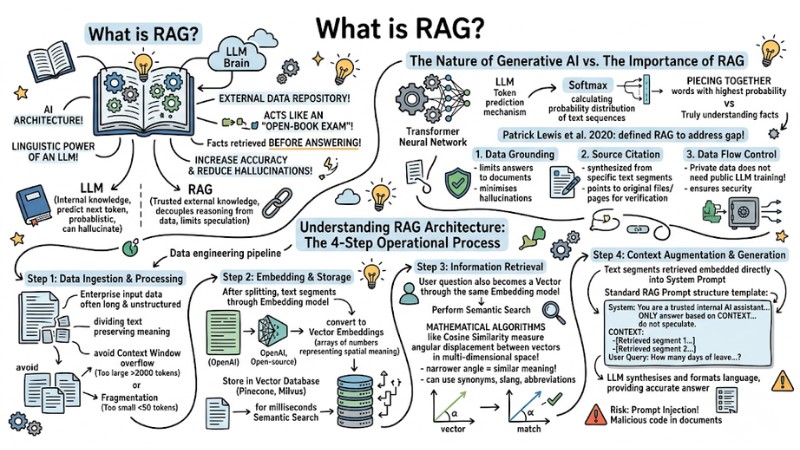
What is RAG?
RAG (Retrieval-Augmented Generation) is an AI architecture that combines the linguistic power of an LLM with an external data repository. This model acts like an "open-book exam," allowing the model to look up factual documents before answering to increase accuracy and reduce hallucinations.
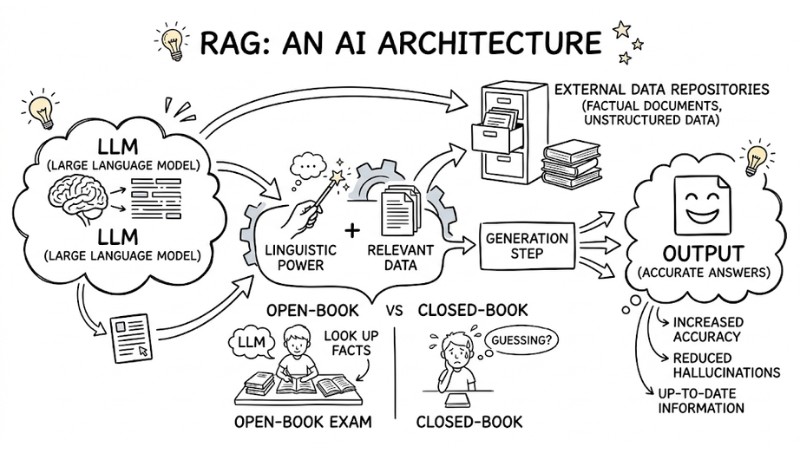
RAG is an AI architecture that combines the linguistic power of LLM with external data repositories
The Essence of RAG and its Importance for LLM Systems
The Nature of Generative AI Models
To understand why RAG architecture has become an industry standard, we need to look at the mathematical nature of Generative AI models. At a fundamental level, an LLM operates based on a Token prediction mechanism (predicting the next token) by calculating the probability distribution of learned text sequences.
This means that when generating an answer, the AI is essentially piecing together words with the highest probability of appearing adjacently, rather than truly "understanding" the truth or falsehood of the facts.
The Importance of RAG
In 2020, a research group led by Patrick Lewis defined the concept of RAG to address this mathematical gap. Instead of trying to cram all knowledge into the model's parameters, which is expensive to train, RAG decouples the AI's reasoning from the data storage.
The system allows the LLM to access a trusted knowledge base before responding. This process brings three core advantages:
- Data Grounding: Forces the language model to limit its answers based on factual data in the documents, minimizing hallucinations.
- Source Citation: Since answers are synthesized from specific retrieved text segments, the system can point to original files or document pages for users or auditors to verify accuracy.
- Data Flow Control: Private data does not need to be included in the public LLM training process, ensuring security.
Note: RAG architecture does not make the AI "smarter" or change the model's inherent logical reasoning capability. RAG simply plays the role of providing the correct input information for an excellent language processing engine.
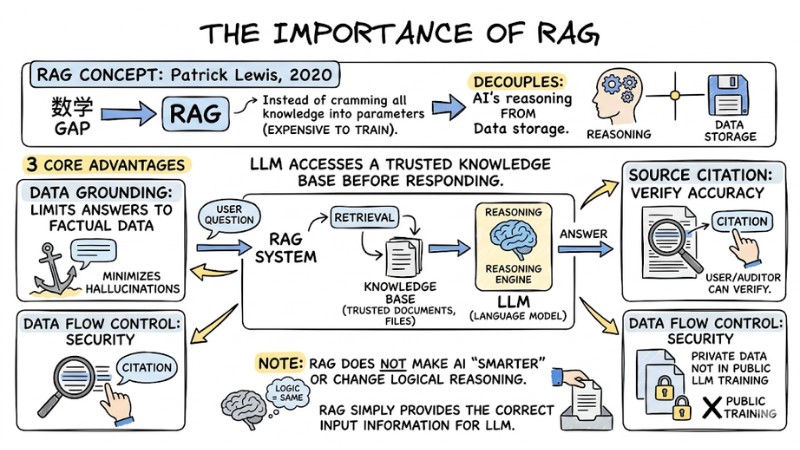
The importance of RAG to the LLM system
Understanding RAG Architecture: The 4-Step Operational Process
From a Data Engineering perspective, a RAG data processing flow operates in four sequential steps:
- Ingestion and Chunking: Dividing raw data into suitably sized text segments.
- Embedding Generation: Converting text segments into numerical vectors representing meaning and storing them.
- Retrieval: Querying the most semantically relevant pieces of information based on the user's query.
- Augmentation and Generation: Incorporating the found context into the Prompt and requesting the LLM to generate the final answer.
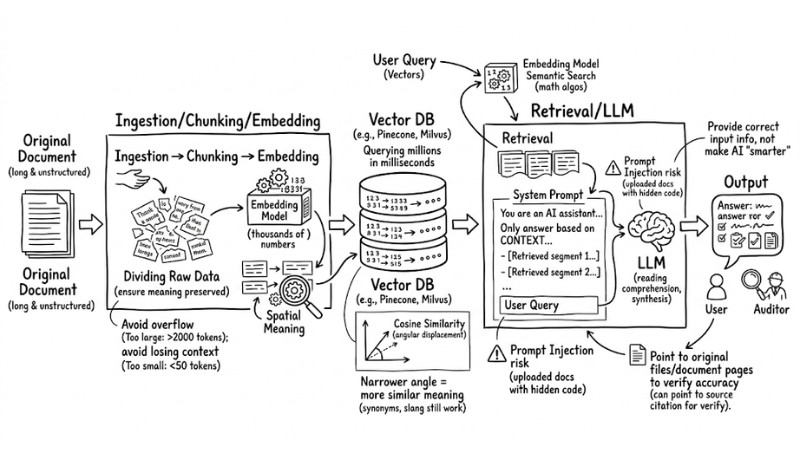
RAG's operating procedures
Let's dive deep into the technical mechanism of each stage in this pipeline.
Step 1: Data Ingestion and Processing
Enterprise input data is often long and unstructured, while LLMs have a hard limit on the maximum number of tokens they can process in a single API call. If a 100-page document is fed entirely, the system will report a memory overflow or refuse to respond.
Therefore, data engineers must apply chunking strategies. Dividing the text must ensure the meaning of the sentence or paragraph is preserved.
Experience: If the chunk size is set too large (e.g., >2000 tokens), retrieving multiple chunks can overflow the Context Window. Conversely, if chunks are too small (under 50 tokens), the text is fragmented, causing the AI to completely lose the context needed to understand the core message.
Step 2: Embedding and Storage
After splitting, the text segments are passed through a specialized Embedding model (such as OpenAI's text-embedding-3-large or an open-source model) to convert them into Vector Embeddings. These are arrays containing thousands of numbers, representing the spatial meaning of that segment.
These vectors are then indexed and stored in a Vector Database such as Pinecone or Milvus. The speed of querying millions of vectors in this type of database takes only a few milliseconds, providing a solid foundation for real-time systems.
Step 3: Information Retrieval
When a user asks a question, that question is also run through the Embedding model from Step 2 to become a Vector. At this point, the system performs a Semantic Search inside the Vector Database.
Unlike traditional keyword search, which requires an exact character match, Semantic Search uses mathematical algorithms like Cosine Similarity to measure the angular displacement between vectors in multi-dimensional space. The narrower the angle between two vectors (Cosine index approaching 1), the more similar the meaning. As a result, even if the user enters synonyms, slang, or abbreviations, the system still retrieves the correct document segment containing the answer.
Step 4: Context Augmentation and Generation
This is the final stage where RAG "packages" the information to give to the LLM. The text segments retrieved in Step 3 will be embedded directly into a predefined "System Prompt" along with the user's original question.
Standard Prompt structure template in RAG:
System: You are a trusted internal AI assistant. Only answer questions based on the CONTEXT provided below. If the CONTEXT does not contain relevant information, say "I could not find the data," and absolutely do not speculate.
CONTEXT:
- [Retrieved segment 1: Leave regulations for 2024 only apply to...]
- [Retrieved segment 2: Social insurance appendix on maternity...]
User Query: How many days of leave is an employee entitled to after working for 2 years?
With this tightly locked Prompt structure, the LLM will use its reading comprehension skills to synthesize, format the language, and provide the most accurate answer. However, the biggest risk at this step is Prompt Injection, where uploaded documents contain hidden malicious code to overwrite System commands.
Should You Use Fine-Tuning or RAG?
When designing an AI system, confusing Fine-tuning (model refinement) and RAG often leads to wasting thousands of dollars in computing costs while the results still do not solve hallucinations.
Fine-tuning is the process of updating AI weights by training it on an example dataset. It is excellent at changing the tone, nuances of expression, or helping the AI learn to output complex data formats. However, Fine-tuning is often very limited in stuffing new facts into the model and incurs retraining costs every time data changes.
In contrast, RAG represents the trend of cost-effective knowledge expansion. You can provide new documents to the AI immediately without touching the model's core. The limitation of RAG is that it does not change the model's innate behavior.
Comparison Table: Detailed Application of Fine-Tuning vs. RAG
| Criteria | RAG Architecture | Fine-Tuning | When to Combine Both |
| Main Purpose | Adding dynamic info, new docs, real-time facts. | Teaching AI communication style, output formatting, niche terminology. | When needing an AI that understands complex legal language and retrieves the latest laws. |
| Hallucination Handling | Very effective due to mandatory source referencing. | Poorly effective; model is still prone to fabrication. | - |
| Data Updates | Instant. Just add/delete files in Vector Database. | Slow and expensive. Requires data cleaning and retraining. | - |
| Security and Authorization | Easy to assign access rights (RBAC) on each doc segment. | Cannot authorize. Anyone can query trained data. | - |
| Infrastructure Cost | Low to medium (Mainly API fees and Vector storage). | Very high (Requires powerful GPUs like A100/H100 and ML engineers). | - |
Robust System Design Principle: Always use RAG as the foundation for knowledge processing first, and only consider Fine-tuning when the original LLM model cannot understand your industry's specialized formatting or language.
Challenges in Deploying RAG
Despite having a fairly clear processing flow, moving RAG from a test environment (POC) to a real-world organizational scale (Production) faces significant technical issues.
In a Multi-tenant architecture, sharing a single Vector Database carries a serious risk of cross-data leakage. If the namespace division or metadata permission filtering is not precisely isolated, a lower-level employee could cleverly use a Prompt to search for and extract salary reports from the shared data pool. Additionally, RAG is susceptible to attacks through malicious input documents containing hidden commands to manipulate the LLM's results.
The Future with AI Agentic Workflow
Overcoming the barriers of data isolation, RAG architecture is evolving strongly into the Agentic RAG system model. Instead of being just a linear pipeline (ask -> search -> answer), RAG at this point becomes a specialized "tool" assigned to AI Agent Orchestration flows to manage.
In the AI Agent Orchestration process, the AI agent will automatically reason and make a decision: "With this query, should I call RAG to retrieve internal documents, or call a web search API?". Furthermore, if the text segment returned from the database lacks information, the AI Agent will automatically rewrite the query and call RAG once more until enough facts are gathered, turning the system into a truly autonomous machine.
Frequently Asked Questions about RAG
What is RAG (Retrieval-Augmented Generation)?
RAG is an AI architecture that combines the linguistic capabilities of an LLM with an external data repository. It acts as an "open-book exam," allowing the AI to look up factual documents before answering, ensuring information accuracy and minimizing hallucinations.
Why use RAG instead of just Fine-tuning the model?
RAG outperforms Fine-tuning in real-time data updates and cost management. While Fine-tuning helps the AI learn linguistic nuances, RAG provides access to a dynamic knowledge base that can change constantly without retraining the entire model.
What are the main components of a RAG process?
A standard RAG system consists of 4 components:
- Data Ingestion: Dividing and converting text into vectors.
- Vector Database (Vector DB): Storing and indexing data.
- Retrieval: Searching for relevant information.
- Generation: Synthesizing the answer based on context.
Does RAG completely solve AI "hallucination" problems?
Not entirely. RAG significantly reduces hallucinations by grounding answers in factual data (AI Grounding), but the quality of output still depends on the accuracy of source documents and the system's data retrieval strategy.
How to secure data when deploying RAG for multiple users?
You need to apply a Multi-tenant architecture with workspace isolation mechanisms. Each user should have a separate index and security layers like API key encryption and access control (RBAC) to prevent cross-data leakage or SSRF attacks.
Does RAG architecture need a Vector Database?
Yes, a Vector Database is a core component for performing semantic search. It stores numerical representations, allowing the system to find documents most relevant to the user's question based on meaning rather than just keyword matching.
Read more:
- 10 AI Agent Cost Optimization Strategies for Budget Management
- How to Choose the Optimal AI Agent Platform for Your Business in 2026
- Self-hosted vs SaaS AI Agents: Which option is right for your business?
In summary, RAG is becoming the "backbone" for modern LLM systems: instead of cramming everything into the model and accepting hallucinations, you separate the knowledge, retrieve the correct data, and then let the AI reason and answer. By combining the 4-step pipeline, intelligent chunking strategies, Vector Databases, multi-tenant security, and (when necessary) fine-tuning, you can build autonomous AI Agents that understand deep language while always being updated with real-time knowledge, all while controlling costs and operational risks.