AI Hallucination là gì: Giải pháp khắc phục ảo giác AI hiệu quả

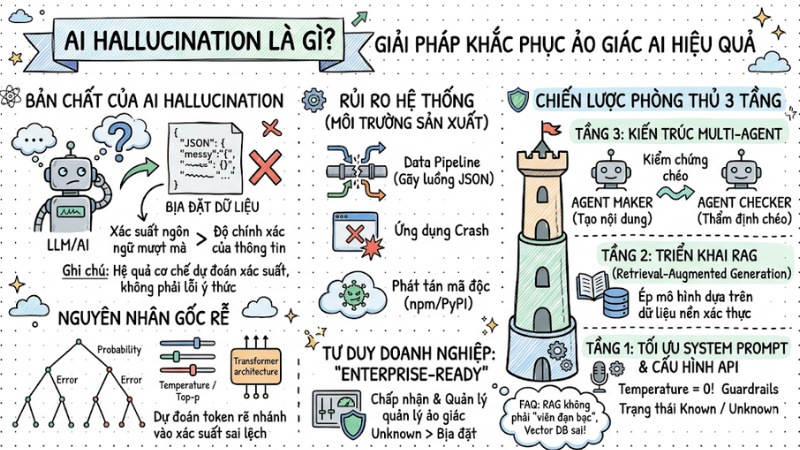
Khi đưa generative AI (AI tạo sinh) vào hệ thống thực tế, nỗi lo lớn nhất của developer không phải là tốc độ phản hồi, mà là những lần model trả về JSON với các trường bịa đặt làm gãy cả data pipeline phía sau. Hiện tượng này thường bị tưởng như “lỗi ma thuật”, nhưng thực chất là vấn đề kiến trúc hệ thống và xác suất thống kê; để AI chạy an toàn ở môi trường production, chúng ta cần hiểu rõ cơ chế AI hallucination và thiết kế guardrails nhiều lớp, từ tầng dữ liệu cho đến tầng điều phối agent.
Những điểm chính
- Bản chất của AI Hallucination: Hiểu rõ ảo giác AI không phải là lỗi ý thức mà là hệ quả từ cơ chế dự đoán xác suất của mạng nơ-ron, nơi mô hình ưu tiên sự mượt mà của ngôn ngữ hơn độ chính xác của thông tin.
- Nguyên nhân gốc rễ: Nắm vững vai trò của các tham số như
Temperature,Top-pvà kiến trúc Transformer khiến mô hình dễ bị "rẽ nhánh" vào các xác suất sai lệch khi thiếu cơ sở đối chiếu thực tế. - Rủi ro hệ thống: Nhận diện các mối nguy hại cụ thể trong môi trường sản xuất như làm gãy các luồng dữ liệu (Data Pipeline), gây lỗi ứng dụng (Crash) hoặc phát tán mã độc thông qua các tài nguyên ảo.
- Chiến lược phòng thủ 3 tầng: Xây dựng hệ thống bảo vệ đa lớp:
- Tầng 1: Tối ưu hóa System Prompt và cấu hình API (đặc biệt là Temperature = 0).
- Tầng 2: Triển khai RAG (Retrieval-Augmented Generation) để ép mô hình làm việc dựa trên dữ liệu nền xác thực.
- Tầng 3: Sử dụng kiến trúc Multi-agent để thực hiện kiểm chứng chéo (Agent Maker tạo nội dung, Agent Checker thẩm định).
- Tư duy thiết kế "Enterprise-ready": Chấp nhận ảo giác là một tính chất cần được quản lý, thay vì kỳ vọng loại bỏ 100%, từ đó xây dựng cơ chế cho phép AI trả về trạng thái "Unknown" thay vì bịa đặt.
- Giải đáp FAQ: Hiểu rõ tại sao RAG không phải là "viên đạn bạc" (vẫn có thể bị lỗi nếu dữ liệu Vector DB sai) và các chiến lược giảm thiểu rủi ro vận hành hiệu quả nhất.
AI Hallucination (Ảo giác AI) thực chất là gì?
AI Hallucination (Ảo giác AI) là hiện tượng các mô hình ngôn ngữ lớn (LLM) tự tin tạo ra nội dung sai lệch, nghe có vẻ hợp lý nhưng thực chất là không có căn cứ hoặc trái ngược với dữ liệu huấn luyện và thực tế.
Khác với bộ não con người có khả năng hiểu ngữ nghĩa và logic, LLM bản chất chỉ là các cỗ máy khớp mô hình thống kê. Chúng không thực sự “nói dối” hay “ảo tưởng” theo nghĩa tâm lý học, mà chỉ đơn giản là sinh ra các token (đơn vị từ ngữ) có xác suất tiếp nối cao nhất theo thuật toán, ngay cả khi kết quả sai sự thật.
Khi gọi API của các mô hình ngôn ngữ, hệ thống của bạn có thể đối mặt với các dạng ảo giác phổ biến sau:
- Source fabrication (Bịa nguồn tài liệu): Mô hình tự tạo ra các đường link URL, tên thư viện lập trình hoặc các trích dẫn bài báo khoa học không hề tồn tại.
- Logical errors (Lỗi logic suy luận): Phản hồi tuân thủ đúng định dạng ngôn ngữ nhưng vi phạm các nguyên tắc toán học cơ bản hoặc tự mâu thuẫn với chính bối cảnh (context) được cung cấp trong prompt.
- Feature hallucination (Bịa đặc tả kỹ thuật): Tự ý thêm các key lạ vào cấu trúc JSON hoặc gọi các hàm (functions) chưa từng được định nghĩa trong schema.
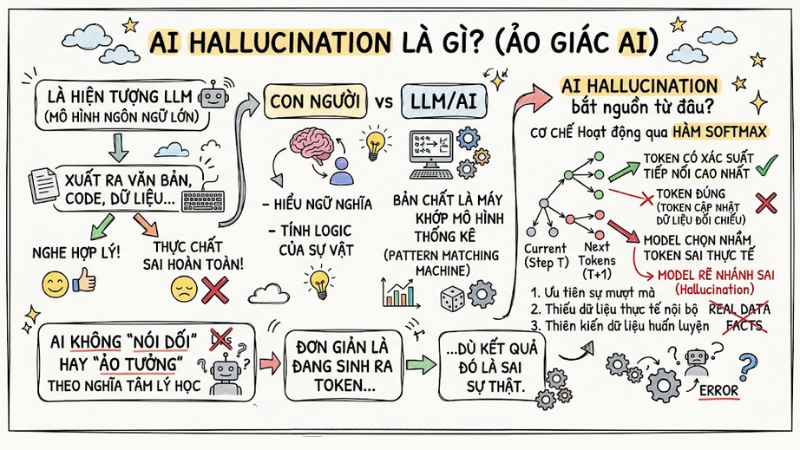
AI Hallucination là hiện tượng các mô hình ngôn ngữ lớn tự tin tạo ra nội dung sai lệch
AI Hallucination bắt nguồn từ đâu?
Bản chất của AI Hallucination bắt nguồn từ chính kiến trúc thiết kế của mạng nơ-ron Transformer. Dưới đây là 3 nguyên nhân cốt lõi từ góc độ thuật toán:
- Cơ chế dự đoán từ tiếp theo: Mô hình ưu tiên sự mượt mà của ngôn ngữ hơn là độ chính xác của thông tin.
- Thiếu cơ sở đối chiếu: Khi không được cung cấp dữ liệu thực tế nội bộ, mô hình phải “đoán” dựa trên trọng số tĩnh.
- Thiên kiến dữ liệu huấn luyện: Dữ liệu đầu vào bị nhiễu hoặc chứa thông tin sai lệch, dẫn đến mô hình học các liên kết thống kê không chính xác.
Tóm lại: Về mặt toán học, cơ chế dự đoán token tiếp theo hoạt động thông qua hàm Softmax. Tại mỗi bước sinh từ, hàm này chuyển đổi các điểm số (logits) thành một phân phối xác suất cho toàn bộ từ vựng. Khi thông tin nằm ngoài phạm vi chắc chắn của mô hình, các token đúng và sai có thể có điểm tự tin (Confidence Score) gần bằng nhau. Nếu thuật toán chọn nhầm một token có xác suất thấp ở cuối phân phối, hiện tượng ảo giác có thể xảy ra.
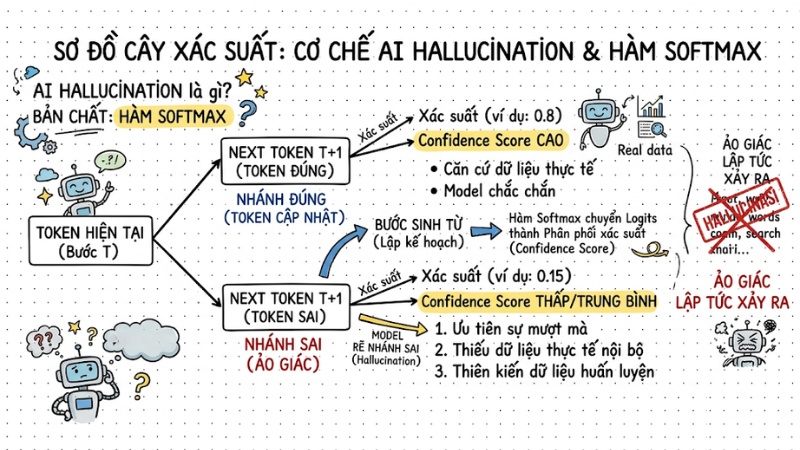
Bản chất của AI Hallucination bắt nguồn từ chính kiến trúc thiết kế của mạng nơ-ron Transformer
Tác động của Decoding Strategies
Các tham số bạn truyền vào API (Chiến lược Giải mã - Decoding Strategies) quyết định trực tiếp mức độ ảo giác. Để ép mô hình bớt "sáng tạo", bạn cần hiểu rõ ba tham số can thiệp vào đuôi phân phối xác suất:
- Temperature (Nhiệt độ): Giá trị càng gần 0, mô hình càng bảo thủ, luôn chọn token có xác suất cao nhất. Phù hợp cho code và JSON.
- Top-p (Nucleus Sampling): Chỉ xem xét nhóm các token có tổng xác suất tích lũy đạt một ngưỡng
pnhất định. - Top-k: Cắt bỏ toàn bộ từ vựng, chỉ giữ lại
ktoken có xác suất cao nhất ở mỗi bước sinh.
{
"model": "claude-3-5-sonnet-20240620",
"messages": [{"role": "user", "content": "Trích xuất thông tin khách hàng từ đoạn hội thoại dưới dạng JSON."}],
"temperature": 0.0, // Giữ Temperature ở mức 0 để model không sáng tạo thêm key lạ
"top_p": 0.9,
"max_tokens": 1024
}
Rủi ro khi đưa AI lên Production
Triển khai một mô hình AI trực tiếp tương tác với cơ sở dữ liệu hoặc người dùng mà không có lớp kiểm duyệt sẽ tạo ra những lỗ hổng chí mạng. Một lỗi mô hình nhỏ ở đầu ra có thể gây thiệt hại lớn cho vận hành doanh nghiệp:
- Gãy luồng Data Pipeline: Khi AI nhận nhiệm vụ phân tích log hệ thống và xuất ra JSON, việc tự ý thay đổi tên trường (ví dụ: đổi
error_codethànherrorCode) có thể khiến các parser phía sau báo lỗi, làm ứng dụng bị crash. - Tấn công chuỗi cung ứng: Kẻ xấu lợi dụng việc AI thường bịa ra các tên gói thư viện chưa tồn tại để tạo malware và đẩy lên npm hoặc PyPI với tên gọi đó. Developer thiếu cảnh giác copy lệnh
npm installtừ AI sẽ trực tiếp đưa mã độc về máy. - Phát tán thông tin sai lệch: Doanh nghiệp tin tưởng và sử dụng trực tiếp kết quả AI để tư vấn pháp lý hoặc y tế có thể đối mặt với kiện tụng.
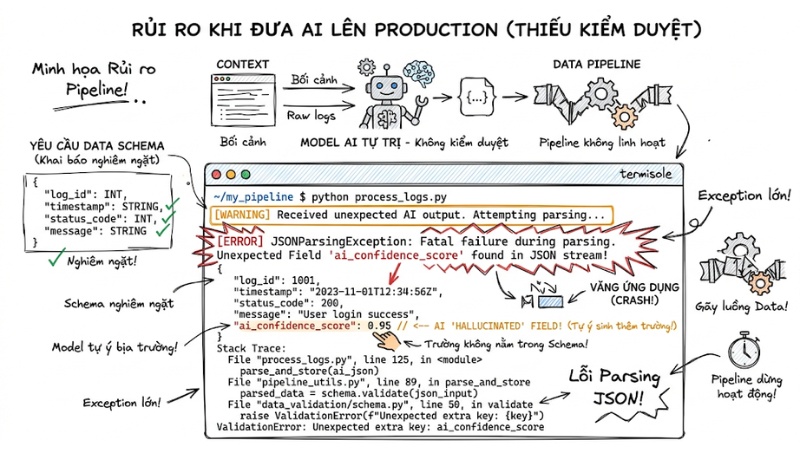
Màn hình báo lỗi Exception khi Parsing JSON thất bại do model tự ý sinh thêm một trường dữ liệu
Kiến trúc hệ thống chống AI Hallucination cho Developer
Không có giải pháp nào loại bỏ hoàn toàn 100% tỷ lệ ảo giác của LLM. Để triển khai trong môi trường doanh nghiệp (enterprise), hệ thống của bạn cần được thiết kế theo tư duy phòng thủ theo chiều sâu với 3 tầng cụ thể:
- Thiết lập Guardrails bằng Prompt Engineering và Tham số API.
- Cung cấp Dữ liệu Nền (Grounding Data) bằng kỹ thuật RAG.
- Kiểm duyệt chéo bằng Điều phối Đa Tác tử (Multi-agent Orchestration).
Tầng 1: Prompt Engineering & Tham số API
Cách hiệu quả và tiết kiệm chi phí nhất để ngăn chặn ảo giác là thiết kế System Prompt chặt chẽ ngay từ đầu. Thay vì để model tự do suy diễn, hãy ép nó tuân thủ một bộ quy tắc nghiêm ngặt. Quan trọng nhất là cấp quyền cho AI được phép nói "Tôi không biết" - hay trả về "Unknown" - thay vì cố gắng bịa câu trả lời.
Mẫu System prompt chống ảo giác và ép xuất định dạng chuẩn:
system_prompt = """
Bạn là một kỹ sư trích xuất dữ liệu nghiêm ngặt.
Quy tắc:
1. CHỈ sử dụng thông tin được cung cấp trong [CONTEXT].
2. Nếu không tìm thấy thông tin trong [CONTEXT], BẮT BUỘC trả về giá trị "Unknown".
3. KHÔNG TỰ SUY DIỄN hoặc lấy thông tin từ kiến thức nền của bạn.
4. Đầu ra phải tuân thủ chuẩn định dạng JSON, không kèm giải thích.
"""
Tầng 2: Cấp bối cảnh thực tế với kỹ thuật RAG
RAG hiện là tiêu chuẩn ngành để khắc phục điểm yếu thiếu kiến thức nội bộ của LLM. Thay vì hỏi trực tiếp mô hình, luồng hệ thống sẽ truy vấn Vector Database (Cơ sở dữ liệu Vector) trước.
Khi người dùng gửi truy vấn, hệ thống RAG sẽ tìm kiếm các đoạn văn bản có ý nghĩa tương đồng nhất với truy vấn trong Vector DB. Sau đó, nó đính kèm các tài liệu này vào làm ngữ cảnh và ép LLM chỉ được phép đọc và tổng hợp từ đó.
Tuy nhiên, RAG vẫn có thể thất bại nếu Vector DB truy xuất nhầm các tài liệu không phù hợp, do đó cần có tầng kiểm soát cao nhất ở cấp độ Agent.
Tầng 3: Multi-agent Orchestration & Guardrails
Khi mở rộng hệ thống (scale) lên mức độ phức tạp, việc sử dụng một mô hình duy nhất cho nhiều nhiệm vụ (tính toán, truy xuất dữ liệu, định dạng code) sẽ làm tăng đáng kể xác suất sinh ảo giác. Đây là lúc multi-agent orchestration (điều phối đa tác tử) giải quyết bài toán bằng cách chia để trị.
Bạn sẽ thiết lập một kiến trúc gồm hai thành phần: Agent Maker (đảm nhận việc sinh nội dung) và Agent Checker (đảm nhận việc thẩm định chéo). Kết quả đầu ra (Output) từ Maker sẽ không trả trực tiếp cho người dùng mà được chuyển qua Checker để xác minh.
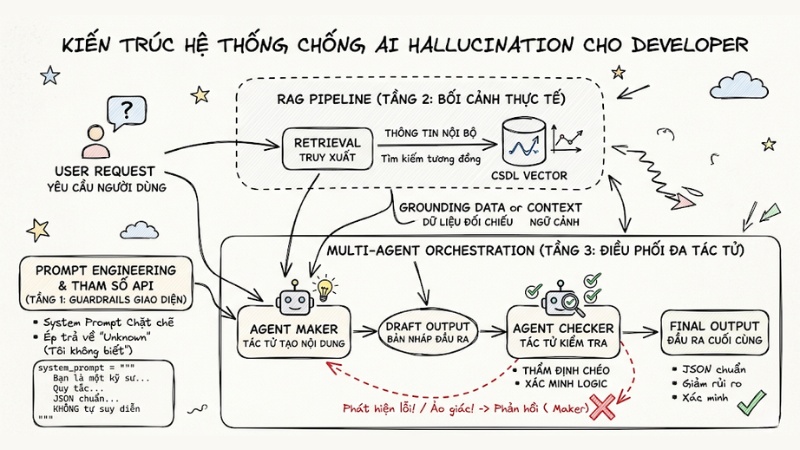
Kiến trúc hệ thống chống AI Hallucination cho Developer
Câu hỏi thường gặp liên quan tới AI Hallucination
AI Hallucination là gì?
AI Hallucination (ảo giác AI) là hiện tượng các mô hình ngôn ngữ lớn (LLM) tự tin tạo ra nội dung sai lệch, vô nghĩa hoặc không có căn cứ trong dữ liệu huấn luyện. Bản chất đây là sự cố dự đoán chuỗi token sai lệch do cơ chế xác suất của mô hình, không phải lỗi ý thức.
Tại sao mô hình AI lại tạo ra thông tin sai lệch?
Hiện tượng này xuất phát từ cơ chế dự đoán token tiếp theo (next-token prediction). LLM tính toán phân phối xác suất để tạo ra từ ngữ nghe có vẻ hợp lý về mặt thống kê, thay vì truy xuất thông tin từ cơ sở dữ liệu xác thực, dẫn đến việc “điền khuyết” thông tin thiếu hụt một cách không kiểm soát.
Làm thế nào để giảm thiểu hiện tượng ảo giác khi sử dụng LLM?
Để giảm thiểu, bạn cần:
- Triển khai kiến trúc RAG (Retrieval-Augmented Generation) để cung cấp ngữ cảnh thực tế cho mô hình.
- Điều chỉnh các tham số decoding như
Temperaturevề mức thấp (0.1–0.3) để tăng tính ổn định. - Sử dụng hệ thống Đa Tác tử (Multi-agent) để thực hiện kiểm chứng chéo (Cross-check) giữa các kết quả đầu ra.
AI Hallucination có thể gây ra những rủi ro nào cho doanh nghiệp?
Rủi ro chính bao gồm:
- Lỗi hệ thống dữ liệu (ví dụ: cấu trúc JSON bị gãy trong pipeline).
- Phát tán thông tin sai lệch gây mất uy tín thương hiệu.
- Rủi ro bảo mật (ví dụ: AI đề xuất các thư viện phần mềm độc hại chưa từng tồn tại).
Liệu việc sử dụng RAG có loại bỏ hoàn toàn AI Hallucination không?
Không. RAG giúp giảm thiểu đáng kể bằng cách giới hạn phạm vi truy vấn. Tuy nhiên, nếu dữ liệu đầu vào (Vector DB) chứa thông tin sai lệch hoặc quá trình truy xuất (retrieval) bị lỗi, mô hình vẫn có thể tạo ra phản hồi không chính xác dựa trên ngữ cảnh đó.
Xem thêm:
- Cách chọn nền tảng AI Agent tối ưu cho doanh nghiệp 2026
- Đo lường AI Agent ROI: Lộ trình từ thực thi đến giá trị thực tế
- Self-hosted vs SaaS AI Agent: Lựa chọn nào cho doanh nghiệp?
Bản chất của ai hallucination không phải là lỗi rác, mà là tính "sáng tạo" của thuật toán Transformer bị đặt sai ngữ cảnh. Trong môi trường doanh nghiệp, kỳ vọng một mô hình ngôn ngữ không bao giờ bịa đặt thông tin là điều phi thực tế. Giải pháp kiến trúc bền vững nhất là bạn hãy thừa nhận rủi ro và xây dựng hệ thống Guardrails nhiều lớp: Từ tối ưu Temperature, giới hạn bối cảnh bằng RAG, cho đến thiết lập mạng lưới kiểm duyệt chéo.