Deep Learning là gì? Phân tích kiến trúc và bản chất học sâu

Sự dịch chuyển từ lập trình dựa trên quy tắc sang hướng tiếp cận định hướng dữ liệu đã thay đổi hoàn toàn cách chúng ta xây dựng hệ thống phần mềm. Đối mặt với khối lượng khổng lồ của dữ liệu phi cấu trúc như hình ảnh, âm thanh hay văn bản tự nhiên, các kỹ sư phần mềm cần một giải pháp mạnh mẽ hơn so với các thuật toán tuyến tính truyền thống. Bài viết này sẽ "giải phẫu" kiến trúc bên trong và cơ chế toán học cốt lõi của Deep Learning (Học Sâu) giúp bạn hiểu rõ nguyên lý vận hành đằng sau sự bùng nổ của AI.
Những điểm chính
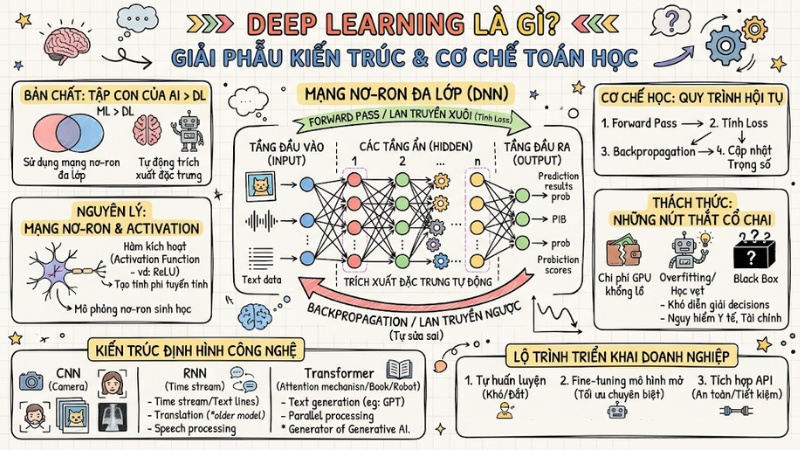
- Bản chất Deep Learning: Hiểu rõ Deep Learning là tập con của Machine Learning, sử dụng mạng nơ-ron đa lớp để tự động trích xuất đặc trưng, loại bỏ hoàn toàn gánh nặng thủ công của con người so với ML truyền thống.
- Nguyên lý toán học: Nắm vững cấu trúc 3 tầng (Input - Hidden - Output) và vai trò sống còn của Hàm kích hoạt (Activation Function) như ReLU trong việc tạo tính phi tuyến tính, giúp mạng nơ-ron học được các quy luật phức tạp.
- Cơ chế tự sửa sai: Hiểu sâu về quy trình Forward Pass (lan truyền xuôi để tính Loss) và Backpropagation (lan truyền ngược bằng đạo hàm/Gradient Descent) để mô hình hội tụ dần đến kết quả chính xác.
- Kiến trúc định hình công nghệ: Phân định các kiến trúc chuyên biệt: CNN (xử lý ảnh), RNN (xử lý chuỗi - cũ), và Transformer (cơ chế Self-Attention xử lý song song - nền tảng của Generative AI).
- Thách thức thực tế: Nhận diện các "nút thắt cổ chai" gồm chi phí GPU khổng lồ, hiện tượng Overfitting (học vẹt) và bài toán "Black Box" (khó diễn giải quyết định), đặc biệt nguy hiểm trong y tế và tài chính.
- Lộ trình triển khai: Khuyến nghị 3 hướng: Tự huấn luyện (tốn kém/yêu cầu chuyên gia), Fine-tuning mô hình mở (tối ưu chuyên biệt), và tích hợp API (phương án an toàn/hiệu quả chi phí cho doanh nghiệp).
- Giải đáp FAQ: Làm rõ sự khác biệt giữa ML và DL, tại sao cần GPU khủng, lý do Transformer thống trị hiện nay và cách quản lý bảo mật khi kết nối hệ thống với các API mô hình lớn.
Bản chất của Deep Learning và sự khác biệt so với Machine Learning
Định nghĩa Deep Learning
Deep Learning (Học sâu) là một nhánh của Machine Learning, sử dụng mạng nơ-ron nhân tạo đa lớp để tự động trích xuất đặc trưng và học các biểu diễn dữ liệu phức tạp từ lượng lớn thông tin phi cấu trúc, giảm thiểu sự can thiệp thủ công của con người.
Bản chất của phương pháp này dựa trên định lý xấp xỉ phổ quát, chứng minh rằng một mạng nơ-ron với đủ độ sâu và số lượng tham số có khả năng mô phỏng bất kỳ hàm toán học liên tục nào.
Mối quan hệ giữa các tầng AI
Trong hệ sinh thái công nghệ hiện đại, trí tuệ nhân tạo được chia thành các tầng kế thừa nhau. AI là khái niệm rộng nhất bao trùm mọi nỗ lực mô phỏng trí tuệ. Machine Learning là tập con của AI, tập trung vào việc dùng thuật toán để phân tích dữ liệu và học hỏi. Ở lõi sâu nhất, chúng ta có Deep Learning, một trong những kỹ thuật tiên tiến nhất hiện nay để xử lý các loại dữ liệu phức tạp như hình ảnh, âm thanh và văn bản.
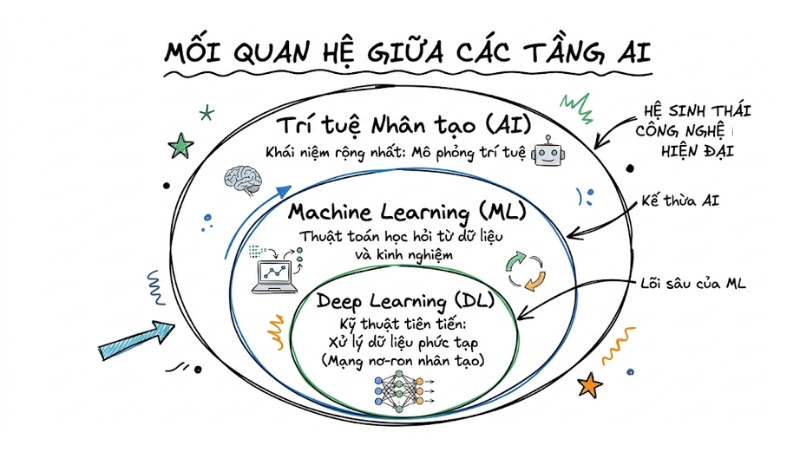
Mối quan hệ giữa các tầng AI
Sự dịch chuyển từ Feature Engineering sang Feature Extraction
Điểm khác biệt cốt lõi nhất giữa Machine Learning truyền thống (như SVM, Random Forest) và Deep Learning nằm ở quy trình xử lý luồng dữ liệu. Trong Machine Learning, Data Scientist thường phải dành rất nhiều thời gian để tự tay thực hiện bước trích xuất đặc trưng (Feature Engineering). Ví dụ, để AI nhận diện khuôn mặt, kỹ sư phải lập trình để máy tính đo đạc khoảng cách giữa hai mắt, độ cong của môi.
Ngược lại, kiến trúc học phân cấp cho phép tự động hóa hoàn toàn bước này thông qua cơ chế Feature Extraction (Trích xuất đặc trưng tự động). Ví dụ, mạng nơ-ron sẽ tự phân tích hàng triệu điểm ảnh và xác định đâu là đặc trưng quan trọng nhất để phân loại, giảm thiểu sự định kiến của con người.
| Tiêu chí | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|
| Đặc trưng dữ liệu | Dữ liệu dạng bảng, có cấu trúc. | Dữ liệu phi cấu trúc (ảnh, text, video). |
| Yêu cầu Data | Hoạt động tốt với lượng dữ liệu nhỏ/vừa. | Yêu cầu lượng Big Data khổng lồ để hội tụ. |
| Trích xuất đặc trưng | Kỹ sư tự định nghĩa thủ công (Feature Engineering). | Hệ thống tự động trích xuất (Feature Extraction). |
| Phần cứng yêu cầu | Xử lý tốt trên CPU tiêu chuẩn. | Bắt buộc dùng GPU/TPU hiệu năng cao. |
| Tính diễn giải | Cao (dễ hiểu logic ra quyết định). | Thấp (Hộp đen - Black Box). |
Phân tích cấu trúc mạng Nơ-ron nhân tạo
Giới truyền thông thường ví von Artificial Neural Networks (Mạng nơ-ron nhân tạo) giống như bộ não con người. Tuy nhiên, dưới góc nhìn của một kỹ sư, hệ thống này không có "nhận thức"; bản chất của nó là hàng triệu phép nhân ma trận số học chạy song song.
Cấu trúc 3 tầng cốt lõi
Một mạng nơ-ron đa lớp (DNN) chuẩn mực bao gồm ba thành phần chính:
- Lớp đầu vào: Nơi tiếp nhận dữ liệu thô đã được mã hóa thành các cấu trúc đa chiều (Tensor).
- Các lớp ẩn: Đây là nguồn gốc của từ "Deep" trong Deep Learning. Dữ liệu đi qua hàng trăm lớp ẩn, mỗi lớp bóc tách một mức độ trừu tượng khác nhau của dữ liệu.
- Lớp đầu ra: Chứa các hàm phân phối xác suất (như Softmax) để đưa ra kết quả dự đoán cuối cùng.
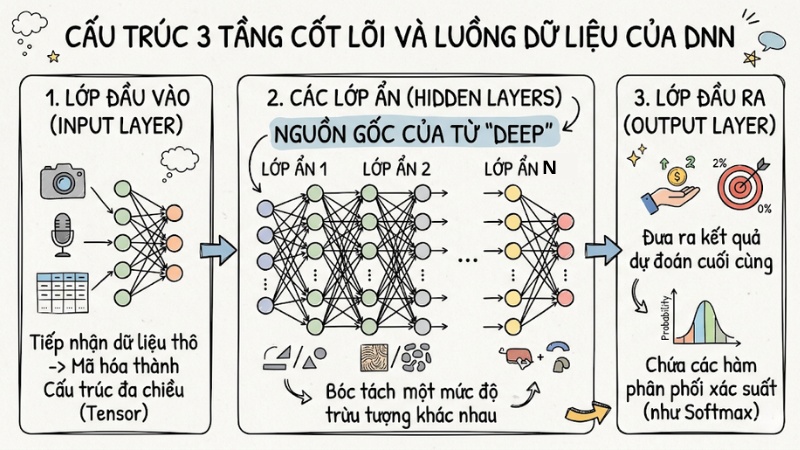
Một mạng nơ-ron đa lớp (DNN) bao gồm ba thành phần chính
Toán học đằng sau một Node (Nơ-ron)
Mỗi nơ-ron nhân tạo (Node) trong mạng thực thi một phương trình toán học đơn giản nhưng mạnh mẽ:
$$y = f(\sum_{i=1}^{n} (w_i \cdot x_i) + b)$$
Trong đó:
- $x_i$: Các tín hiệu đầu vào từ lớp trước đó.
- Weight ($w_i$): Trọng số biểu thị mức độ quan trọng của tín hiệu đầu vào.
- Bias($b$): Độ lệch, giúp dịch chuyển đường thẳng của hàm số nhằm tăng độ linh hoạt.
- Hàm kích hoạt $f(x)$: Là yếu tố sống còn tạo ra tính phi tuyến tính (Non-linear). Nếu không có hàm kích hoạt như ReLU, toàn bộ mạng nơ-ron khổng lồ sẽ mất đi tính phi tuyến, trở thành một mô hình hồi quy tuyến tính đơn giản và kém hiệu quả.
Dưới đây là mã giả minh họa luồng tính toán này bằng Python:
import numpy as np
# Mô phỏng một node (nơ-ron) đơn giản
inputs = np.array([1.5, 2.0, -0.5]) # Dữ liệu đầu vào (Tensor 1D)
weights = np.array([0.8, -0.2, 0.5]) # Trọng số (Weights)
bias = 0.1 # Độ lệch (Bias)
# Tính tổng có trọng số: Sum(w * x) + b
z = np.dot(inputs, weights) + bias
# Hàm kích hoạt ReLU: f(z) = max(0, z)
# Loại bỏ giá trị âm để tạo tính phi tuyến tính
output = np.maximum(0, z)
print(f"Output sau kích hoạt: {output}")
Trung tâm của hệ thống: Forward Pass và Backpropagation
Để mạng nơ-ron có thể "học", nó cần một cơ chế tự sửa sai liên tục. Chu trình này phụ thuộc hoàn toàn vào hai pha xử lý dữ liệu: Lan truyền xuôi và Lan truyền ngược.
Lan truyền xuôi (Forward Pass) và Loss Function
Trong pha lan truyền xuôi, dữ liệu đi từ lớp Input xuyên qua các lớp Hidden và sinh ra một dự đoán ở lớp Output. Lúc này, hệ thống sẽ đối chiếu kết quả dự đoán với nhãn thực tế thông qua Loss Function. Hàm này sẽ đo lường sai số: Giá trị càng cao, mô hình dự đoán càng sai.
Lan truyền ngược (Backpropagation) và tối ưu hóa
Khi đã biết sai số ở đầu ra, thuật toán Backpropagation (Lan truyền ngược) sẽ được kích hoạt. Bằng việc sử dụng quy tắc chuỗi trong giải tích, hệ thống sẽ tính toán đạo hàm riêng của Loss Function theo từng trọng số trong mạng từ lớp cuối cùng ngược về lớp đầu tiên.
Sau đó, thuật toán Gradient Descent sẽ cập nhật lại toàn bộ các giá trị Weights. Bạn có thể tưởng tượng quá trình này giống như việc tìm đường đi xuống tận cùng chân núi trong điều kiện sương mù dày đặc: Mỗi bước đi được quyết định bằng cách dò xem độ dốc dưới chân mình đang nghiêng về hướng nào. Do phải nhân hàng tỷ ma trận cùng lúc, quá trình này đòi hỏi kiến trúc tính toán song song cực mạnh từ GPU.

Terminal log quá trình training Gradient Descent
# Quá trình Gradient Descent cập nhật Weights qua các Epochs
Epoch 1/50 - Loss: 2.5401 - Accuracy: 0.2310 # Mạng dự đoán sai, hàm mất mát cao
Epoch 10/50 - Loss: 1.8320 - Accuracy: 0.4502 # Lan truyền ngược bắt đầu cập nhật trọng số
Epoch 25/50 - Loss: 0.9405 - Accuracy: 0.7250 # Mô hình bắt đầu nắm bắt đặc trưng dữ liệu
Epoch 50/50 - Loss: 0.1004 - Accuracy: 0.9850 # Hội tụ thành công, chạm đáy dốc Gradient
Các kiến trúc Deep Learning định hình thế giới công nghệ
Ngành khoa học dữ liệu đã phát triển các kiến trúc mạng chuyên biệt để xử lý những định dạng dữ liệu khác nhau.
Mạng nơ-ron tích chập (CNN)
CNN (Convolutional Neural Networks) là kiến trúc thống trị lĩnh vực Computer Vision (CV). Dựa trên cơ chế quét các ma trận bộ lọc (filters) qua bức ảnh, CNN có thể nhận diện các đặc trưng cục bộ như cạnh, góc, góc viền, sau đó ghép nối chúng lại để nhận diện các vật thể phức tạp.
- Ứng dụng: Nhận diện khuôn mặt, chẩn đoán ảnh y tế, xe tự lái.
- Cột mốc: Đã vượt mốc độ chính xác của con người trên bộ dữ liệu kinh điển ImageNet.
Mạng nơ-ron hồi quy (RNN)
Trong quá khứ, RNN (Recurrent Neural Networks) là tiêu chuẩn vàng cho các tác vụ xử lý NLP và dữ liệu chuỗi thời gian. Bằng cách duy trì "trạng thái ẩn" (hidden state), RNN nhớ được các thông tin từ bước trước đó. Tuy nhiên, nó mắc phải điểm yếu chí mạng là hiện tượng suy giảm đạo hàm, khiến nó không thể "nhớ" được ngữ cảnh của những đoạn văn bản quá dài.
Kiến trúc Transformer
Kiến trúc Transformer xử lý luồng dữ liệu thông qua cơ chế Self-Attention, cho phép mô hình đánh giá tầm quan trọng của mọi từ trong một câu cùng lúc (xử lý song song) thay vì đọc từng từ một. Đây chính là kiến trúc lõi tạo ra kỷ nguyên Generative AI và các mô hình ngôn ngữ lớn (LLMs).
- Ứng dụng: Dịch thuật ngữ cảnh sâu, tóm tắt văn bản tự động, lập trình code.
- Điểm mạnh: Khả năng mở rộng không giới hạn với hàng nghìn tỷ tham số.
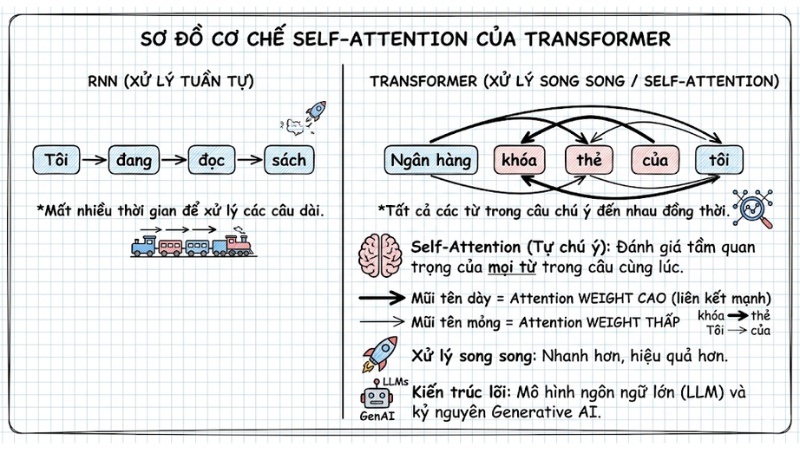
Cơ chế Self-Attention của kiến trúc Transformer
Thách thức kỹ thuật và giới hạn thực tế của Deep Learning
Dù mang sức mạnh tính toán khổng lồ, công nghệ Deep Learning vẫn tồn tại những điểm mù mà bất kỳ đội ngũ kỹ sư nào cũng cần lường trước khi đưa lên môi trường thực tế (production).
Nút thắt phần cứng và dữ liệu
Chi phí tính toán là một rào cản vật lý lớn. Các mô hình hiện đại tiêu tốn hàng nghìn GPU NVIDIA chạy ngày đêm. Đồng thời, nếu cố ép một mạng nơ-ron phức tạp học trên một tập dữ liệu quá nhỏ, hiện tượng Overfitting sẽ xảy ra. Mô hình sẽ học vẹt bộ data mẫu một cách hoàn hảo nhưng thất bại toàn tập khi xử lý dữ liệu thực tế.
Lỗi Out Of Memory (OOM): Khi cấu hình Batch Size quá lớn so với dung lượng VRAM thực tế của GPU trong quá trình training, hệ thống sẽ lập tức crash với lỗi CUDA Out Of Memory. Kỹ sư buộc phải giảm thiểu kích thước batch hoặc cấu hình thuật toán Gradient Accumulation (Tích lũy Gradient) để tránh treo máy chủ.
Vấn đề hộp đen (Black Box)
Hạn chế gây tranh cãi nhất là khả năng diễn giải mô hình. Mặc dù chúng ta viết ra mã nguồn của hàm mục tiêu, nhưng khi mạng nơ-ron tự điều chỉnh hàng tỷ trọng số ẩn bên trong, không một kỹ sư nào trên thế giới có thể giải thích chính xác tại sao mô hình lại đưa ra kết quả đó.
Điều này dẫn đến khuyến cáo quan trọng: Tuyệt đối không giao phó hoàn toàn các quyết định liên quan đến tính mạng y tế hay giao dịch tài chính cho mô hình nếu quy định doanh nghiệp yêu cầu hệ thống phải có tính diễn giải rõ ràng.
Cách triển khai Deep Learning trong thực tế
Để giải quyết bài toán nghiệp vụ, các Data Scientist và Developers hiện nay thường áp dụng 3 hướng tiếp cận chính, phân cấp theo nguồn lực tài chính:
- Tự huấn luyện từ đầu: Yêu cầu đội ngũ chuyên gia tự cấu hình tensor, loss function bằng các thư viện gốc như PyTorch, TensorFlow. Phương án này tốn kém hàng triệu USD tiền hạ tầng Model Training (Huấn luyện Mô hình) và yêu cầu lượng dữ liệu siêu lớn.
- Sử dụng mô hình huấn luyện sẵn: Tải các trọng số mã nguồn mở trên HuggingFace và tinh chỉnh (Fine-tuning) thêm một lượng data nhỏ nội bộ để phục vụ ngách nghiệp vụ riêng.
- Tích hợp API (Khuyên dùng cho Doanh nghiệp): Đối với các tác vụ văn bản/code phức tạp, hướng đi an toàn và tối ưu chi phí nhất là gọi trực tiếp RESTful API của các LLMs đến từ OpenAI, Anthropic hay DeepSeek (các nhà cung cấp LLM hàng đầu) thay vì "nướng tiền" vào việc xây dựng hệ thống lại từ số không.
Câu hỏi thường gặp về Deep Learning (Học sâu)
Deep Learning là gì?
Deep Learning (Học sâu) là một tập hợp con của Machine Learning, sử dụng các mạng nơ-ron nhân tạo với nhiều tầng xử lý để tự động trích xuất đặc trưng từ dữ liệu phi cấu trúc, giúp máy tính thực hiện các tác vụ phức tạp như nhận diện hình ảnh hay xử lý ngôn ngữ tự nhiên.
Machine Learning khác gì Deep Learning?
Machine Learning đòi hỏi con người thực hiện thủ công bước trích xuất đặc trưng (Feature Engineering), trong khi Deep Learning có khả năng tự động học các đặc trưng đó (Feature Extraction). Bạn nên chọn Machine Learning cho dữ liệu có cấu trúc, chọn Deep Learning cho dữ liệu phi cấu trúc khối lượng lớn.
Tại sao Deep Learning cần nhiều sức mạnh tính toán?
Do bản chất của Deep Learning là hàng tỷ phép nhân ma trận song song trong các lớp ẩn (hidden layers). Việc đào tạo mô hình đòi hỏi các dòng GPU hoặc NPU mạnh mẽ để xử lý khối lượng dữ liệu khổng lồ và rút ngắn thời gian hội tụ của hàm mất mát.
Transformer là gì trong Deep Learning?
Transformer là kiến trúc mạng nơ-ron hiện đại sử dụng cơ chế "Self-Attention" để xử lý song song toàn bộ dữ liệu đầu vào. Đây là nền tảng cốt lõi của các mô hình Generative AI như ChatGPT, vượt trội hơn hẳn so với các kiến trúc tuần tự cũ như RNN.
Vấn đề "Black Box" trong Deep Learning là gì?
Đây là hiện tượng các kỹ sư không thể giải thích chi tiết cách mô hình đưa ra một quyết định cụ thể dựa trên các tham số nội tại. Vì lý do thiếu tính minh bạch, nhiều hệ thống y tế hoặc tài chính thận trọng khi áp dụng Deep Learning.
Xem thêm:
- Prompt Caching: Cách tối ưu độ trễ và chi phí API LLM hiệu quả
- Low-code là gì? Tìm hiểu về kiến trúc kỹ thuật và rủi ro tiềm ẩn
- Generative AI là gì? Các ứng dụng thực tế của Generative AI
Tóm lại, Deep Learning không phải là phép màu thần bí, bản chất của nó là các ma trận toán học khổng lồ thực hiện việc trích xuất và chuyển đổi dữ liệu thô thành tri thức. Sức mạnh phân tích dữ liệu phi cấu trúc vô song này đang dẫn dắt thị trường, nhưng đòi hỏi gánh nặng lớn về hạ tầng phần cứng, chi phí duy trì GPU và đi kèm các rủi ro bảo mật thông tin. Đó là lý do phần lớn các doanh nghiệp hiện đại đang dịch chuyển từ việc tự train model khổng lồ sang sử dụng API của các LLM hàng đầu.