Prompt Caching: Cách tối ưu độ trễ và chi phí API LLM hiệu quả

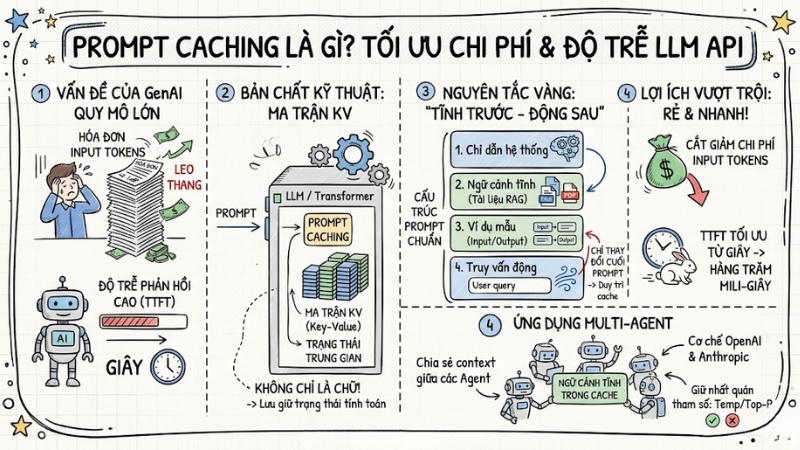
Hóa đơn Input Tokens API leo thang và độ trễ phản hồi cao, đặc biệt là chỉ số Time-to-First-Token (TTFT), luôn là hai vấn đề lớn khi mở rộng hệ thống AI Agent hoặc RAG. Để giải quyết triệt vấn đề này, Prompt Caching ra đời và đã trở thành tiêu chuẩn bắt buộc trong kiến trúc GenAI hiện đại. Trong bài viết này, mình sẽ đi sâu vào cơ chế hoạt động nội tại của bộ nhớ đệm LLM, đồng thời cung cấp các mẫu cấu trúc prompt thực tế để bạn áp dụng ngay vào mã nguồn.
Tìm hiểu về Prompt Caching
Prompt Caching là gì?
Prompt Caching là kỹ thuật lưu trữ các phần nội dung tĩnh của prompt (như hướng dẫn hệ thống, tài liệu tham khảo) vào bộ nhớ của mô hình LLM. Nhờ đó, ở các lần gọi sau, mô hình không cần tính toán lại toàn bộ ngữ cảnh từ đầu mà tái sử dụng kết quả trung gian, giúp giảm đáng kể chi phí input tokens và độ trễ phản hồi.
Prompt Caching là kỹ thuật lưu trữ các phần nội dung tĩnh của prompt vào bộ nhớ của LLM.
Prompt Caching không phải caching thông thường
Khi nhắc đến bộ nhớ đệm, các lập trình viên thường nghĩ ngay đến kỹ thuật Exact-match caching thông qua Redis hoặc Memcached. Với kiến trúc truyền thống này, hệ thống lưu trữ toàn bộ chuỗi string đầu vào làm Key và chuỗi text đầu ra làm Value. Nếu người dùng gửi một câu hỏi khác đi dù chỉ một dấu phẩy, hệ thống sẽ báo Cache Miss và tính toán lại từ đầu.
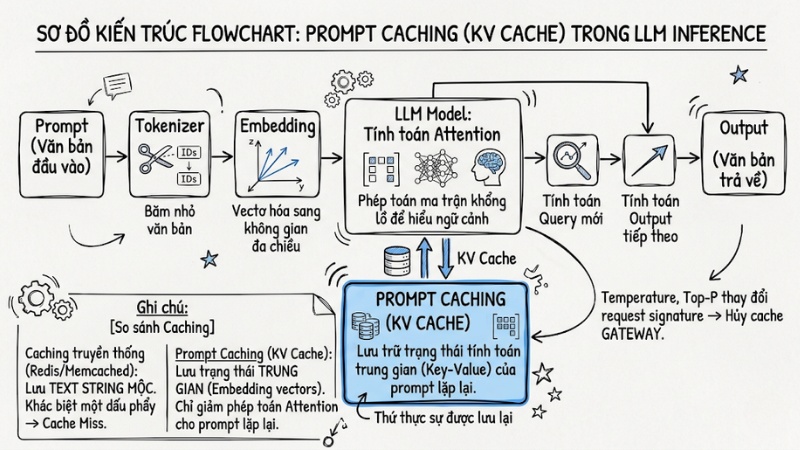
Tuy nhiên, cách tối ưu hóa quá trình suy luận của LLM hoạt động hoàn toàn khác biệt. Mô hình ngôn ngữ lớn không lưu chuỗi văn bản thuần túy. Khi bạn gửi một prompt, dữ liệu sẽ đi qua Tokenizer để chuyển thành các ID số học, sau đó được ánh xạ thành các vector đa chiều trong không gian Embedding. Tại đây, mô hình bắt đầu thực hiện các phép toán ma trận phức tạp để hiểu ngữ cảnh. Thứ thực sự được lưu lại chính là trạng thái tính toán trung gian của các mạng nơ-ron này.
Bên cạnh đó, việc bạn thay đổi các tham số cấu hình như Temperature, Top-P hoặc Max Tokens trong payload API sẽ lập tức làm thay đổi chữ ký (signature) của request. Hệ thống gateway của nhà cung cấp sẽ đánh giá đây là một luồng xử lý mới và vô hiệu hóa hoàn toàn bộ nhớ đệm trước đó.
Tìm hiểu về KV Matrices
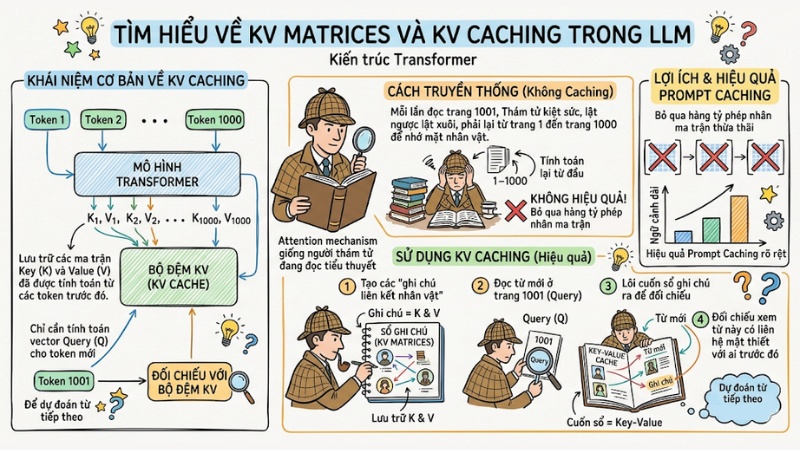
KV Cache (Key-Value Caching) trong LLM là cơ chế lưu trữ các ma trận Key (K) và Value (V) đã được tính toán từ các token trước đó trong kiến trúc Transformer, giúp tăng tốc độ suy luận. Thay vì phải xử lý lại toàn bộ ngữ cảnh từ đầu, mô hình chỉ cần tính toán vector Query (Q) cho token mới nhất và đối chiếu với bộ đệm KV để dự đoán từ tiếp theo.
Để dễ hình dung, hãy xem cơ chế Attention mechanism như một người thám tử đang đọc một cuốn tiểu thuyết trinh thám dài 1000 trang.
- Thay vì mỗi lần đọc đến trang 1001, thám tử phải đọc lại từ trang 1 đến trang 1000 để nhớ lại các chi tiết liên quan (tính toán lại từ đầu).
- Người thám tử này tạo ra các "ghi chú liên kết nhân vật" (chính là KV Matrices).
- Khi đọc từ mới ở trang 1001 (Query), thám tử chỉ cần lôi cuốn sổ ghi chú (Key-Value) ra để đối chiếu xem từ này có liên hệ mật thiết với nhân vật nào trước đó.
Nhờ việc tái sử dụng KV Matrices, LLM bỏ qua được hàng tỷ phép nhân ma trận thừa thãi. Càng cung cấp ngữ cảnh đầu vào dài, hiệu quả Prompt Caching mang lại càng thể hiện rõ rệt.
KV Cache (Key-Value Caching) trong LLM
Nghệ thuật cấu trúc prompt để tối ưu hóa Cache Hit
Nguyên tắc tĩnh trước - động sau
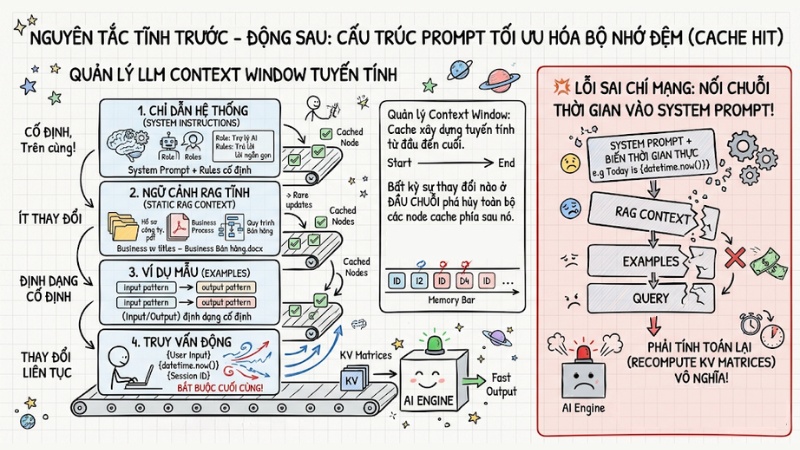
Để xử lý ngữ cảnh ăn khớp với cơ chế bộ nhớ đệm, bạn phải quản lý LLM Context Window theo đúng thứ tự tuyến tính. Bộ nhớ đệm được xây dựng từ token đầu tiên đến token cuối cùng theo một chiều duy nhất. Bất kỳ sự thay đổi nào ở đầu chuỗi đầu vào sẽ phá hủy toàn bộ các node cache phía sau nó.
Dưới đây là 4 quy tắc vàng định hình cấu trúc prompt tối ưu:
- Chỉ dẫn hệ thống: Đặt các chỉ thị hệ thống, vai trò (role-play) và quy tắc (rules) cố định ở vị trí trên cùng.
- Ngữ cảnh RAG tĩnh: Chèn các tài liệu nền, tệp PDF, quy trình doanh nghiệp ít thay đổi vào vị trí thứ hai.
- Ví dụ mẫu: Cung cấp các ví dụ mẫu (Input/Output) định dạng cố định tiếp theo.
- Truy vấn động: Các biến động liên tục như
User Input,Session ID, hoặcdatetime.now()BẮT BUỘC phải nằm ở vị trí cuối cùng.
Lỗi sai phổ biến nhất mà nhiều người dùng thường gặp là nối chuỗi thời gian thực vào System Prompt. Ví dụ: You are an AI. Today is {datetime.now()}. Vì biến thời gian thay đổi theo từng giây, hệ thống phải liên tục tính toán lại KV Matrices từ đầu, biến bộ nhớ đệm thành vô nghĩa.
Nguyên tắc tĩnh trước - động sau
So sánh cơ chế Prompt Caching: OpenAI tự động và Anthropic thủ công
Hiện tại, hai ông lớn đang tiếp cận bộ nhớ đệm theo hai triết lý trái ngược nhau, đòi hỏi sự tinh chỉnh code khác biệt:
- OpenAI (GPT-4o): Hoạt động hoàn toàn ngầm định (implicit). API tự động nhận diện các đoạn prompt dài (thường trên 1024 tokens) và đưa vào cache nếu yêu cầu (request) tiếp theo trùng khớp phần đầu. Ưu điểm là dễ tích hợp, bạn không cần đổi code. Nhược điểm là thiếu tính kiểm soát; đôi khi cache bị thu hồi sớm do server load cao mà dev không hề hay biết.
- Anthropic (Claude 3.5): Yêu cầu cấu hình thủ công cho Granular cache control. Bạn phải chủ động gắn cờ
cache_control: {"type": "ephemeral"}vào mảng JSON message tại đúng điểm dừng mong muốn (breakpoint). Ưu điểm là tối ưu triệt để chi phí, đảm bảo tỉ lệ Cache Hit 100%. Nhược điểm là yêu cầu lập trình viên phải đếm và theo dõi (tracking) token cẩn thận.
Dưới đây là ví dụ cấu trúc mảng message trong Python:
# [BAD PRACTICE] - Gây Cache Miss liên tục do biến thời gian nằm ở trên cùng
bad_messages = [
{"role": "system", "content": f"Today is {datetime.now()}. You are a support bot."},
{"role": "user", "content": "Company policy document: [10,000 words...]"},
{"role": "user", "content": "Can I take a day off tomorrow?"}
]
# [GOOD PRACTICE] - Đảm bảo Cache Hit 100% cho phần System và Document
good_messages = [
{"role": "system", "content": "You are a support bot."}, # Tĩnh
{"role": "user", "content": "Company policy document: [10,000 words...]"}, # Tĩnh (Gắn breakpoint cache tại đây nếu dùng Anthropic)
{"role": "user", "content": f"Today is {datetime.now()}. Can I take a day off tomorrow?"} # Động - Nằm cuối cùng
]
Bài toán thực tế: Tác động đến chi phí và độ trễ
Tại sao các nhà cung cấp API sẵn sàng giảm giá sâu khi hit cache? Câu trả lời nằm ở tài nguyên GPU. Việc tái sử dụng bộ nhớ đệm giúp bỏ qua giai đoạn suy luận tốn kém chi phí nhất. Bạn tiết kiệm compute cho họ, họ giảm tiền cho bạn.
Lưu ý quan trọng: Chính sách giảm giá này chỉ áp dụng cho Input tokens. Chi phí sinh ra Output tokens vẫn giữ nguyên vì mô hình vẫn phải tạo ra phản hồi mới một cách tự động.
| Tiêu chí đánh giá | Không sử dụng Prompt Caching (Cache Miss) | Áp dụng Prompt Caching (Cache Hit) |
|---|---|---|
| Chi phí suy luận trên mỗi 1 triệu Input Tokens | $5.00 (Giá tiêu chuẩn). | $0.50 (Giảm 90% chi phí). |
| Độ trễ khởi động - Time-to-First-Token (TTFT) | ~2,500ms (Cho prompt 50k tokens). | ~150ms - 200ms (Phản hồi gần như tức thì). |
| Tokens được xử lý (Tính toán mới) | 100% độ dài chuỗi đầu vào. | Chỉ tính toán từ User Query cuối cùng. |
Với dữ liệu trên, việc áp dụng bộ nhớ đệm không còn là một tính năng tùy chọn mà đã trở thành tiêu chuẩn cốt lõi cho bất kỳ hệ thống RAG cấp doanh nghiệp nào.
Prompt Caching trong kiến trúc Multi-Agent
Khi xây dựng hệ thống AI Multi-Agent phân tán, vấn đề không chỉ dừng lại ở một API request đơn lẻ. Giả sử bạn có một đội gồm 5 agents cần phối hợp phân tích chung một tài liệu PDF báo cáo tài chính 100 trang. Nếu thiết kế kiến trúc không tốt, mỗi agent sẽ tự động gửi đi một bản sao của tệp PDF đó tới LLM.
Giải pháp sử dụng Prompt Caching trong kiến trúc Multi-Agent là cách dùng bộ nhớ đệm LLM theo kiểu “chia sẻ ngữ cảnh” giữa nhiều agent để tất cả cùng tận dụng lại phần context tĩnh (tài liệu, policy, hướng dẫn hệ thống) thay vì mỗi agent gửi và tính toán lại ngữ cảnh từ đầu.
Nhờ đó, đội nhiều agent có thể đọc chung một bộ tài liệu mà vẫn giữ được Cache Hit cao, giảm mạnh chi phí input tokens và độ trễ, đặc biệt khi hệ thống phải xử lý các file lớn như PDF báo cáo tài chính, log hệ thống hay knowledge base nội bộ.
Câu hỏi thường gặp về Prompt Caching
Prompt Caching là gì?
Prompt Caching là kỹ thuật lưu trữ các phần nội dung tĩnh của prompt (như hướng dẫn hệ thống, tài liệu tham khảo) vào bộ nhớ của mô hình AI. Thay vì xử lý lại từ đầu, hệ thống tái sử dụng kết quả tính toán trung gian, giúp giảm thiểu đáng kể chi phí và độ trễ.
Sự khác biệt giữa Prompt Caching và Caching thông thường là gì?
Prompt Caching lưu trữ các ma trận Key-Value (KV Cache) bên trong kiến trúc Transformer để tránh tính toán lại attention mechanism. Trong khi đó, caching truyền thống (ví dụ: Redis) lưu trữ dữ liệu đầu ra dưới dạng văn bản tĩnh để truy xuất nhanh.
Làm thế nào để đạt được "Cache Hit" tối đa?
Để đạt hiệu quả tối ưu, bạn cần áp dụng cấu trúc "Tĩnh trước - Động sau":
- Đặt các chỉ dẫn hệ thống (System Instructions) ở vị trí đầu tiên.
- Theo sau là các tài liệu tham khảo cố định.
- Đặt các câu hỏi biến động (User Query) ở cuối cùng.
Tại sao thay đổi tham số (Temperature) lại làm hỏng cache?
Prompt Caching yêu cầu sự đồng nhất tuyệt đối về đầu vào và cấu hình. Vì các tham số như Temperature hoặc Top-P ảnh hưởng trực tiếp đến quá trình suy luận, bất kỳ thay đổi nhỏ nào cũng sẽ khiến hệ thống không thể khớp với cache hiện có, dẫn đến Cache Miss.
Prompt Caching có làm giảm chi phí API không?
Prompt Caching có làm giảm đáng kể chi phí cho các phần input tokens được cache. Tuy nhiên, bạn cần lưu ý rằng cơ chế này chỉ áp dụng cho Input Tokens; phần Output Tokens do mô hình tạo ra vẫn giữ nguyên đơn giá tùy thuộc vào từng nhà cung cấp dịch vụ LLM.
Xem thêm:
- Generative AI là gì? Các ứng dụng thực tế của Generative AI
- Low-code là gì? Tìm hiểu về kiến trúc kỹ thuật và rủi ro tiềm ẩn
- Orchestration Layer là gì? Tìm hiểu tầm quan trọng trong hệ thống
Prompt Caching là một bước tiến đột phá về kiến trúc, giúp tận dụng lại KV Matrices để giảm thiểu đáng kể chi phí suy luận và triệt tiêu độ trễ TTFT. Chìa khóa để làm chủ công nghệ này nằm ở việc tuân thủ tuyệt đối nguyên tắc "Tĩnh trước - Động sau" trong quá trình xây dựng mảng tin nhắn (message) đầu vào. Nhờ đó, Prompt Caching không chỉ là một kỹ thuật tối ưu hiệu năng, mà trở thành nền tảng bắt buộc cho mọi hệ thống GenAI và RAG nghiêm túc muốn mở rộng quy mô (scale) với chi phí hợp lý.