What Is Machine Learning? Core Principles and Real-World Applications

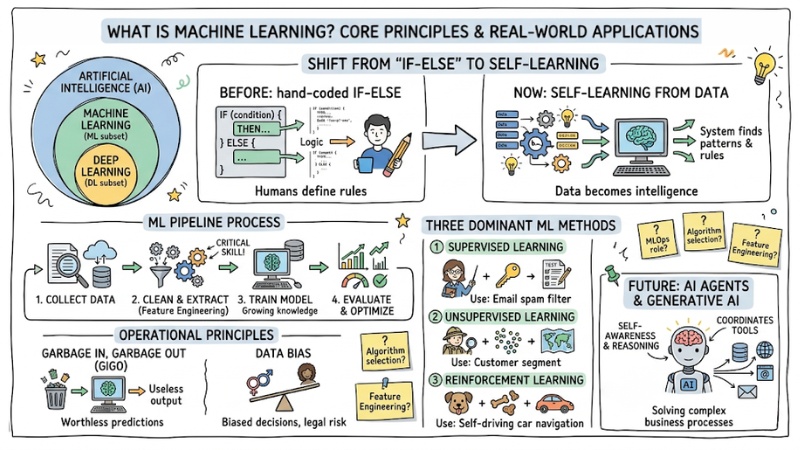
Machine Learning is the turning point that helps software step out of the pure if-else programming era, where every rule had to be hand-coded by humans. Instead of trying to encode all the complexity of the real world, Machine Learning allows systems to self-learn and identify patterns from data. This article focuses on clearly explaining what Machine Learning is, how data is "transformed" into intelligence, and the core algorithms behind modern AI applications.
Key Points
- The nature of Machine Learning: Understand that ML is the shift from the rule-based programming era to the era of self-learning from data, allowing systems to find rules themselves instead of humans defining them in advance.
- Technology stratification: Precisely define the boundaries between AI, Machine Learning, and Deep Learning to apply the right tools for specific problems.
- Standard Pipeline process: Master the 4 steps from collection, cleaning/extraction (Feature Engineering), training, to evaluation/optimization.
- Operational principles: Understand the philosophy of "Garbage In, Garbage Out" and the importance of controlling Data Bias to avoid biased decisions, legal risks, and system errors.
- Three dominant machine learning methods:
- Supervised Learning: Learning with labels (like a teacher holding the answer key), used for prediction/classification.
- Unsupervised Learning: Learning without labels, used for clustering/finding hidden patterns.
- Reinforcement Learning: Learning through reinforcement (reward/punishment), used for optimizing decision sequences/autonomous systems (self-driving cars).
- The future of AI Agents: Grasp the shift from traditional analytical ML to Generative AI and AI Agent architectures—systems capable of self-awareness, reasoning, and coordinating tools to solve complex business processes.
- FAQ resolution: Clarify the role of MLOps in maintaining model performance, how to select suitable algorithms, and why feature engineering skills are the most critical.
What is Machine Learning? Ending the "If-Else" programming era
Machine Learning is a subset of Artificial Intelligence that allows systems to automatically learn and improve from experience without being explicitly programmed for each task. Specifically, the system finds patterns in data to make predictions.
In older programming structures, humans provided data and rules (Logic) for the computer to process and return a result. But with Machine Learning, this architectural mindset is completely reversed: Software engineers only need to provide data and the desired result, and the computer automatically runs algorithms to find the rules. This shift from rule-based to data-driven has solved unstructured problems that pure code could not handle.
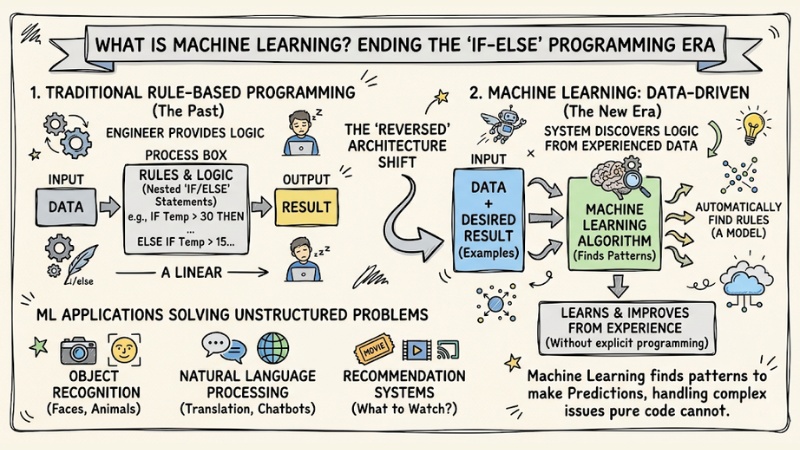
Machine Learning is a subset of Artificial Intelligence (AI)
Distinguishing AI, Machine Learning, and Deep Learning
To avoid terminology confusion when working, we need to clearly define these technology layers:
- Artificial Intelligence (AI): The broadest concept, describing any computer system capable of mimicking human intelligence. A chatbot answering based on a pre-set script is also considered AI.
- Machine Learning (ML): A core branch of AI that uses mathematical and statistical methods to let machines "learn" and improve accuracy based on real-world data.
- Deep Learning (DL): A specialized subset of machine learning. This method is inspired by biological neural networks through artificial neural networks, specialized for handling ultra-complex tasks like voice recognition or computer vision.
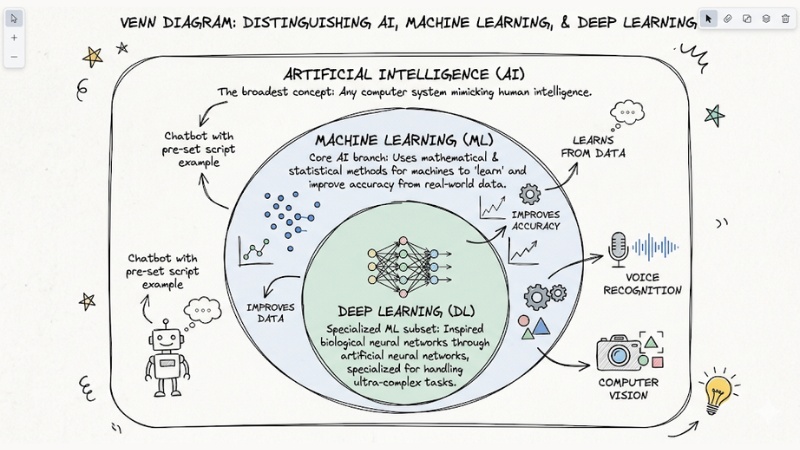
Distinguishing AI, Machine Learning, and Deep Learning
Understanding the Machine Learning Pipeline process
The 4 core steps of the Machine Learning Pipeline are:
- Data collection: Gathering raw data from multiple sources.
- Data preprocessing: Cleaning and extracting features.
- Model training: Running algorithms to make the machine learn the patterns.
- Evaluation and optimization: Measuring error and self-correcting.
This process is the backbone of every Data Science project. Practical deployment shows that the majority of engineers' effort and time is not spent on model tuning, but entirely on feature engineering. Raw data collected from systems is often messy, incomplete, or contains high levels of noise. Without proper formatting and cleaning, mathematical models cannot process it.
After preparing a quality training dataset, the algorithm begins the learning process. The essence of "learning" is the system continuously calculating a Loss function to measure the gap between the predicted result and reality. Thanks to this mechanism, the model proceeds to optimize the algorithm, automatically updating weights repeatedly until the error is suppressed to the lowest allowable level.
The "Garbage In, Garbage Out" principle and Data Bias
The "Garbage In, Garbage Out" principle in data systems indicates that: No matter how optimally designed a model architecture is, if it is fed with garbage data, the predicted results will be completely worthless.
Even more seriously, if your training data contains implicit biases regarding gender, race, or customer behavior, the machine learning system will not only learn them but also amplify those biases at scale, creating skewed decisions that pose legal risks to the business.
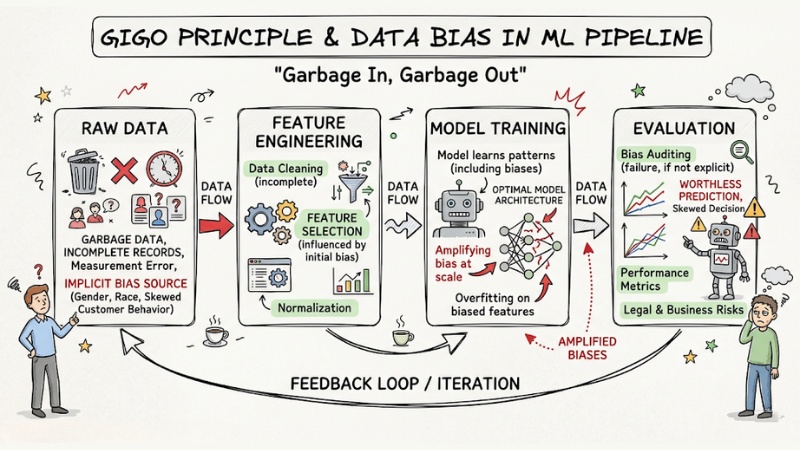
The "Garbage In, Garbage Out" principle and Data Bias
3 most popular machine learning methods
| Criteria | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data type | Labeled data. | Unlabeled data. | State/Environment. |
| Core goal | Map input/output, classification. | Find hidden structures, clustering. | Optimize action sequences for rewards. |
| Metaphor | A teacher holding the answer key. | Sorting a basket of strange coins. | Training a dog with treats and penalties. |
Supervised Learning
The algorithm is provided with a training dataset that already has labels (correct answers) to find the mapping function from input to output. This mechanism is exactly like a "teacher holding the answer key for grading."
You give the computer 10,000 photos, each clearly labeled by an engineer as "Spam" or "Normal." The computer will extract the common features of Spam images. When a completely new image is introduced, it applies the knowledge the "teacher" taught it to make a classification prediction.
Use Case: Applications for building corporate Email Spam filters, or setting up regression models to predict real estate prices based on area and location.
Unsupervised Learning
In this method, the algorithm works with raw data that has no labels, automatically scanning to find structures, patterns, or hidden relationships within.
Imagine you throw this problem at the system: "Sort a basket of strange coins based on size/color" without providing their denomination or origin. Based on similarities in diameter and metal material, the algorithm automatically groups the coins into separate, logical clusters.
Use Case: Running K-Means Clustering algorithms to segment customers for the Marketing department, or detecting unusual transactions in a credit card system without pre-defining what "unusual" means.
Reinforcement Learning
This is the most complex technique, where the model (called an Agent) learns how to make decisions by interacting directly with a simulated environment.
This process is completely analogous to "Training a dog with treats and penalties." If the Agent takes an action in the right direction (e.g., turning right to avoid an obstacle), the system grants a Reward. If it makes a mistake, it receives a Penalty. Through millions of trials and errors, the system continuously optimizes the algorithm to find the most optimal sequence of actions.
Use Case: Implementing navigation algorithms for self-driving cars, optimizing loading/unloading processes in supply chains, or developing AI bots to play chess/Go.

The most popular machine learning methods
From predictive Machine Learning to the era of AI Agents
For decades, traditional Machine Learning has focused on brilliantly solving problems of analysis, risk prediction, and content classification. However, system architecture is witnessing a major revolution. The rise of large language models (LLMs) based on the Transformer mechanism has opened the Generative AI era—where machines not only predict but also have the capability to autonomously create text, code, and images.
As the number of model parameters continues to grow, maintaining infrastructure becomes a headache regarding MLOps. Furthermore, the current trend among tech companies does not stop at calling APIs from a single model. Instead, they focus on building AI Agent architectures—software entities capable of self-awareness of context, autonomous logical reasoning, automatically calling external tools (Tool calling), and coordinating in teams to solve long-running business processes.
Frequently Asked Questions about Machine Learning
How is Machine Learning different from traditional AI?
AI is a broad field encompassing all techniques that help computers simulate human intelligence. Machine Learning is a subset of AI, focusing on algorithms that self-learn from data instead of following hard-coded "if-else" rules.
Why is 80% of a Data Scientist's work Feature Engineering?
The quality of an ML model depends entirely on input data. The preprocessing step helps select, clean, and format data so that the algorithm can easily identify patterns. If the input data is "garbage," the output will be worthless.
When should you choose Supervised Learning over Unsupervised Learning?
Choose Supervised Learning when you have a labeled dataset (with target results) to predict values or classify accurately. Choose Unsupervised Learning when the data is unlabeled and you need the machine to find hidden structures or groups on its own.
Which fields is Reinforcement Learning typically applied in?
Reinforcement Learning is extremely effective in environments requiring autonomy and continuous decision sequences such as self-driving cars, supply chain optimization, automated financial trading systems, or robot control based on trial and error.
Why is it necessary to care about MLOps when deploying AI systems?
MLOps helps standardize processes from collection, training, to deployment and model monitoring. This ensures the model does not degrade in performance after moving to production, while also helping to manage system resources effectively.
See more:
- What is MCP Transport? Understanding the Transmission Mechanisms of the Model Context Protocol
- What Is an Orchestration Layer? Understanding Its Importance in System Architecture
- What is no-code? Opportunities, risks, and when you should use it
Machine Learning remains the core computational engine behind every smart application today. Mastering how to set up Data Pipelines and clearly distinguishing between supervised and reinforcement learning algorithms is a mandatory technical foundation for developers to build optimal solutions.