No-code là gì? Cơ hội, rủi ro và trường hợp nên ứng dụng

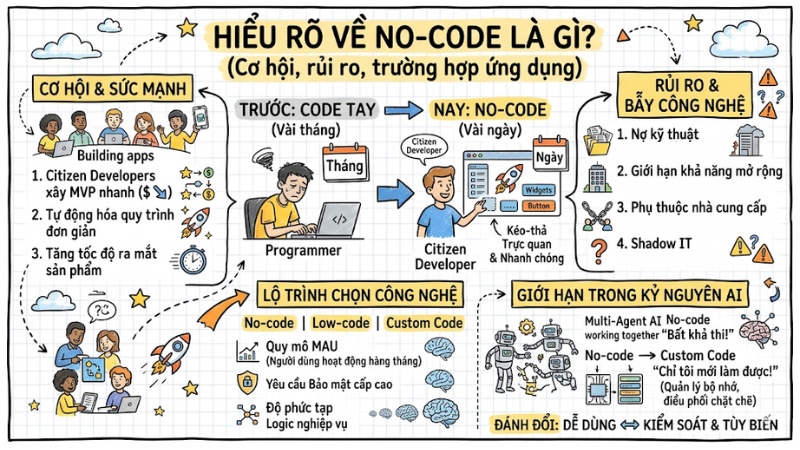
Các nền tảng No-code cho phép người dùng xây dựng ứng dụng bằng thao tác kéo-thả, rút ngắn thời gian ra mắt sản phẩm từ vài tháng xuống vài ngày. Tuy nhiên, chúng tiềm ẩn rủi ro nợ kỹ thuật và giới hạn khả năng mở rộng nếu lạm dụng mà thiếu tư duy thiết kế hệ thống chuẩn mực. Bài viết này sẽ đi thẳng vào bản chất kiến trúc ẩn sau No-code và chỉ ra ranh giới an toàn để doanh nghiệp không rơi vào “bẫy” công nghệ.
Những điểm chính
- Bản chất kiến trúc No-code: Hiểu rõ No-code không phải là "không code" mà là cơ chế biên dịch ngầm thông qua các Abstraction Layers, nơi mọi thao tác kéo-thả đều được chuyển đổi thành mã nguồn backend.
- Sức mạnh của Citizen Developers: Tận dụng nhân sự phi kỹ thuật để xây dựng MVP và tự động hóa các quy trình đơn giản, giúp doanh nghiệp tăng tốc độ ra mắt sản phẩm với chi phí tối thiểu.
- Nhận diện rủi ro cốt lõi: Nắm vững các "bẫy" kỹ thuật gồm nghẽn cổ chai hiệu năng khi dữ liệu lớn, rủi ro phụ thuộc nhà cung cấp và nguy cơ Shadow IT.
- Định luật Trade-off (Đánh đổi): Hệ thống càng dễ sử dụng (No-code) thì khả năng tùy biến và kiểm soát càng bị đóng kín. Khi logic nghiệp vụ phức tạp vượt quá template có sẵn, hệ thống sẽ trở nên bất khả thi để tái cấu trúc.
- Lộ trình lựa chọn công nghệ: Quy mô người dùng (MAU), yêu cầu bảo mật cấp cao, và độ phức tạp của logic nghiệp vụ để quyết định giữa No-code, Low-code hay Custom Code.
- Giới hạn trong kỷ nguyên AI: Hiểu tại sao No-code thất bại khi triển khai hệ thống Multi-Agent phức tạp, nơi đòi hỏi khả năng quản lý bộ nhớ và điều phối chặt chẽ mà chỉ Custom Code mới đáp ứng được.
- Giải đáp FAQ: Làm rõ bản chất của No-code, rủi ro Shadow IT trong doanh nghiệp, và chiến lược chọn công cụ dựa trên sự cân bằng giữa tốc độ MVP và khả năng mở rộng lâu dài.
No-code là gì?
No-code (Phát triển không mã) là một phương pháp tiếp cận thiết kế phần mềm cho phép người dùng xây dựng ứng dụng bằng giao diện đồ họa trực quan (GUI) và các khối logic cấu hình sẵn, thay vì viết các dòng lệnh truyền thống.
Tuy nhiên, ở góc độ hệ thống, mọi thao tác kéo-thả trên giao diện thực chất đều đang tạo ra mã nguồn. Nền tảng No-code hoạt động dựa trên các khái niệm Abstraction layers (Lớp trừu tượng hóa). Đây là cơ chế biên dịch ngầm, có nhiệm vụ phiên dịch các thao tác lập trình trực quan thành các API Request tĩnh, script tiêu chuẩn và câu lệnh truy vấn cơ sở dữ liệu ở backend.
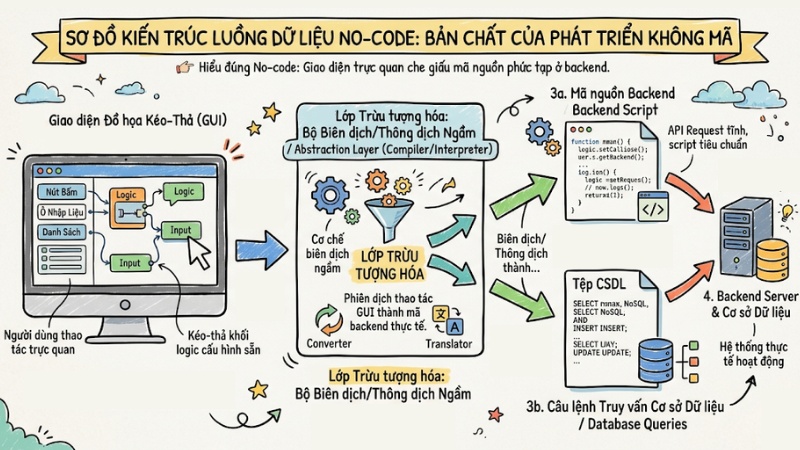
Sơ đồ kiến trúc luồng dữ liệu No-code
Điểm đánh đổi lớn nhất là việc toàn bộ xử lý logic sẽ dồn lên máy chủ của nền tảng No-code. Khi bạn tạo một vòng lặp bằng Visual programming, hệ thống phải sinh ra thêm nhiều lớp code trung gian và thư viện dư thừa – những thứ mà một kỹ sư phần mềm có thể viết gọn và tối ưu hơn rất nhiều.
Sự phát triển của "Citizen Developers"
Việc giấu đi sự phức tạp của hạ tầng máy chủ đã trao quyền cho một nhóm người dùng mới: Citizen developers (những nhân sự phi kỹ thuật như Marketing, HR, Ops). Lúc này, họ có thể tự tay xây dựng các công cụ nội bộ mà không cần chờ đợi đội ngũ IT.
Đối với các bài toán tự động hóa quy trình, như tự động gửi email hay đồng bộ dữ liệu khách hàng từ form vào CRM, những nền tảng No-code này phát huy sức mạnh tối đa. Nhờ lực lượng citizen developers, doanh nghiệp có thể rút ngắn thời gian đưa MVP ra thị trường với chi phí thấp nhất.
Những rủi ro khi ứng dụng No-code: Góc nhìn chuyên sâu
Khi áp dụng vào môi trường Enterprise (Doanh nghiệp quy mô lớn), việc phụ thuộc hoàn toàn vào giao diện kéo-thả tiềm ẩn 3 rủi ro cốt lõi:
- Giới hạn khả năng mở rộng: Xung đột hiệu năng khi xử lý dữ liệu lớn.
- Rủi ro phụ thuộc: Bị trói buộc vào hạ tầng của nhà cung cấp.
- Shadow IT (Công nghệ ngầm): Mất kiểm soát dữ liệu và vi phạm chuẩn bảo mật.
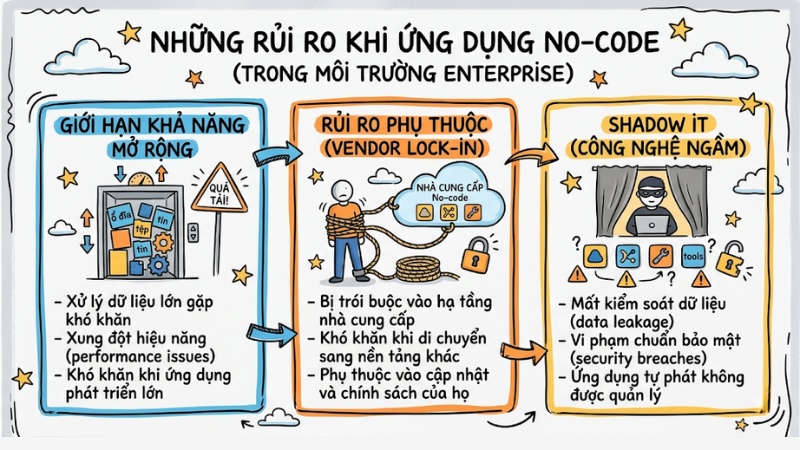
Những rủi ro khi ứng dụng No-code: Góc nhìn chuyên sâu
Giới hạn khả năng mở rộng
Về khả năng mở rộng, giới hạn lớn nhất của No-code nằm ở vấn đề nghẽn cổ chai hiệu năng. Thực tế triển khai No-code cho thấy, khi query database lên đến hàng triệu rows, các vòng lặp ẩn của hệ thống thường gây crash hoặc đẩy chi phí lên mức khổng lồ.
Dưới góc độ thuật toán (Big O), các truy vấn tự động sinh ra thường thiếu các Index (Chỉ mục) tối ưu, khiến độ phức tạp tính toán tăng theo cấp số nhân khi dữ liệu phình to. Điều này tạo ra khoản nợ kỹ thuật khổng lồ mà đội ngũ kỹ sư sau này gần như không thể tái cấu trúc (refactor).
Rủi ro phụ thuộc
Bên cạnh đó, rủi ro phụ thuộc vào nhà cung cấp khi sử dụng No-code là một ranh giới nguy hiểm. Bạn không sở hữu mã nguồn lõi. Nếu nền tảng bên thứ 3 tăng giá API, thay đổi chính sách, hoặc đóng cửa, doanh nghiệp không thể chuyển hệ thống sang AWS hay Google Cloud.
Shadow IT
Cuối cùng, việc nhân sự tự ý tạo luồng dữ liệu dẫn đến rủi ro "Shadow IT", khiến dữ liệu khách hàng (PII) bị luân chuyển ra ngoài server công ty, vi phạm nghiêm trọng các tiêu chuẩn bảo mật như SOC2 hay GDPR.
Sự đánh đổi giữa tốc độ và khả năng tùy biến của No-code
Trong Software Engineering, luôn tồn tại định luật Trade-off (Đánh đổi). Giao diện càng dễ sử dụng, hệ thống "hộp đen" càng đóng kín. Bạn có thể xây dựng tính năng login trong 5 phút, nhưng sẽ rất khó nếu muốn can thiệp sâu để tùy chỉnh, hệ thống sẽ từ chối. Ranh giới kỹ thuật bị phá vỡ khi logic nghiệp vụ của doanh nghiệp bắt đầu vượt quá các template có sẵn.
Nên chọn No-code, Low-code hay Custom Code
Để tránh bẫy công nghệ, các IT Manager và CTO cần phân định rõ ràng khi nào nên dùng công cụ kéo-thả, khi nào bắt buộc phải dùng Low-code hay Custom Code
| Tiêu chí cốt lõi | No-code (Kéo thả hoàn toàn) | Low-code (Kéo thả + Scripting) | Traditional development / Custom code |
|---|---|---|---|
| Tốc độ ra mắt MVP | Vài ngày (Cực nhanh). | Vài tuần (Nhanh). | Vài tháng (Chậm). |
| Mở rộng | Thấp (Dễ nghẽn cổ chai). | Trung bình. | Cực cao (Kiểm soát 100% tài nguyên). |
| Bảo mật và tuân thủ | Phụ thuộc nhà cung cấp. | Có thể tùy chỉnh một phần. | Đáp ứng mọi chuẩn (On-premise, SOC2). |
| Tùy biến | Cực thấp (Bị giới hạn). | Trung bình (Viết thêm logic). | Tuyệt đối (Không giới hạn). |
| Yêu cầu nhân sự | Non-tech, Business user. | Junior Dev, Data Analyst. | Senior Engineer, Solution Architect. |
Dựa vào bảng trên, trước khi khởi tạo dự án, bạn hãy sử dụng checklist đánh giá sau:
- Quy mô người dùng dự kiến có vượt mốc 10,000 MAU (Người dùng hoạt động hàng tháng) không?
- Hệ thống có xử lý dữ liệu nhạy cảm cần tuân thủ bảo mật cấp cao không?
- Mức độ tùy biến của logic nghiệp vụ có phức tạp không?
Nếu câu trả lời đa số là "Có", Custom code sẽ là con đường duy nhất để đảm bảo hệ thống vận hành trơn tru trong dài hạn, tránh việc đập đi xây lại toàn bộ hạ tầng chỉ sau 6 tháng.
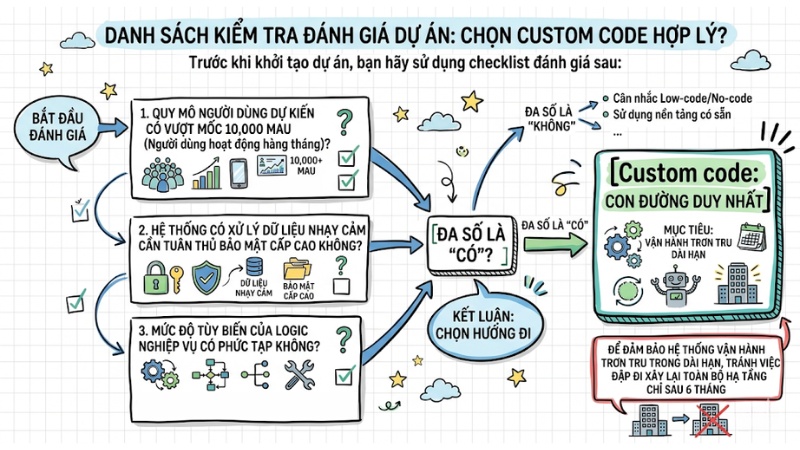
Checklist đánh giá khi nảo nên sử dụng No-code, Low-code và Custom Code
Sự giao thoa: No-code, Low-code và kỷ nguyên AI Agent
Trong bối cảnh bùng nổ của tự động hóa bằng AI, các công cụ không mã đang được ứng dụng mạnh mẽ để kết nối với các mô hình ngôn ngữ lớn (LLM). Việc gọi một API từ OpenAI hay Anthropic để tóm tắt email hay phân tích cảm xúc khách hàng thông qua giao diện kéo-thả diễn ra cực kỳ mượt mà cho các tác vụ đơn lẻ, tĩnh.
Tuy nhiên, giới hạn lộ rõ khi doanh nghiệp muốn tiến tới kiến trúc Multi-Agent. Các nền tảng kéo-thả hiện tại hoàn toàn thất bại trong việc xử lý bộ nhớ ngữ cảnh, Context Routing (Định tuyến ngữ cảnh) và Orchestration phức tạp. Để một đội AI Agent hoạt động không bị "ảo giác" (hallucination) và tuân thủ chặt chẽ quyền truy cập, hệ thống bắt buộc phải được lập trình bằng Custom Code với khả năng can thiệp sâu vào tầng xử lý RAM và Rate limit.
Câu hỏi thường gặp
No-code là gì trong phát triển phần mềm?
No-code là nền tảng phát triển ứng dụng sử dụng giao diện kéo-thả thay vì viết mã thủ công. Về bản chất, nó hoạt động thông qua các lớp trừu tượng hóa (abstraction layers), biên dịch thao tác trực quan của người dùng thành các đoạn mã thực thi và truy vấn cơ sở dữ liệu ở tầng backend.
Sự khác biệt cốt lõi giữa No-code và Low-code là gì?
No-code phục vụ người dùng không chuyên với các mô-đun được đóng gói sẵn, trong khi Low-code cho phép lập trình viên chèn code tùy chỉnh vào các phần logic phức tạp. Bạn có thể chọn No-code để tăng tốc MVP, chọn Low-code khi cần cân bằng giữa tốc độ và khả năng tùy biến.
Tại sao No-code có thể đem lại rủi ro cho doanh nghiệp?
No-code tạo ra rủi ro phụ thuộc vào nhà cung cấp và nợ kỹ thuật khó kiểm soát. Khi hệ thống scale lên hàng triệu lượt truy cập, các vòng lặp ẩn của nền tảng thường gây nghẽn cổ chai hiệu năng, khiến việc di chuyển dữ liệu sang môi trường khác trở nên cực kỳ phức tạp.
Có nên sử dụng No-code để triển khai AI Agent quy mô lớn không?
Không nên. No-code phù hợp để gọi API đơn lẻ, nhưng thất bại khi xây dựng hệ thống Multi-Agent phức tạp. Các dự án AI Agent đòi hỏi khả năng quản lý trạng thái, bộ nhớ và điều phối chặt chẽ, vốn yêu cầu kiến trúc Custom Code để đảm bảo bảo mật và hiệu suất tối ưu.
Rủi ro Shadow IT trong No-code là gì?
Shadow IT xảy ra khi nhân viên tự ý triển khai các ứng dụng No-code mà không thông qua bộ phận IT quản lý. Điều này có thể dẫn đến lỗ hổng bảo mật, vi phạm các tiêu chuẩn dữ liệu như GDPR hoặc SOC2, và làm mất kiểm soát luồng dữ liệu quan trọng của doanh nghiệp.
Làm thế nào để chọn đúng công cụ phát triển?
Nếu dự án cần MVP trong vài ngày, hãy dùng No-code. Nếu cần tùy biến tính năng sâu và tích hợp hệ thống phức tạp, hãy sử dụng Custom code để đảm bảo khả năng mở rộng và tính an toàn của hệ thống.
Xem thêm:
- RAG là gì? Tìm hiểu chi tiết về Retrieval-Augmented Generation
- AIaaS là gì? Tìm hiểu chi tiết về Artificial Intelligence as a Service
- Cách chọn nền tảng AI Agent tối ưu cho doanh nghiệp 2026
No-code là vũ khí tối thượng để thử nghiệm MVP, tự động hóa quy trình nội bộ và giải quyết bài toán thời gian. Tuy nhiên, ranh giới công nghệ nằm ở nhu cầu cốt lõi của doanh nghiệp. Khi bài toán đòi hỏi mức độ bảo mật khắt khe, luồng dữ liệu phức tạp và khả năng mở rộng cấp doanh nghiệp, Custom code vẫn là tiêu chuẩn vàng không thể thay thế.