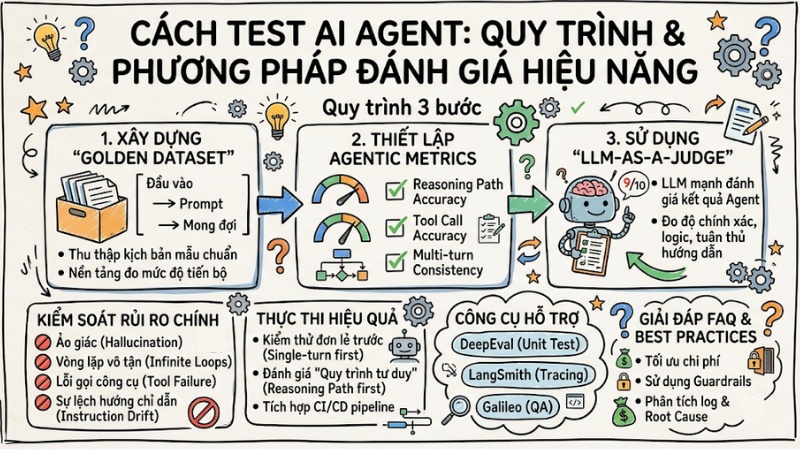
Cách test AI Agent: Quy trình và phương pháp đánh giá hiệu năng

Test AI Agent (còn được hiểu là kiểm thử AI Agent) là quá trình đảm bảo hệ thống tự động dựa trên mô hình ngôn ngữ lớn (LLM) có thể suy luận, sử dụng công cụ (tool) và hoàn thành tác vụ một cách chính xác. Bài viết dưới đây sẽ giúp các kỹ sư và quản lý sản phẩm xây dựng quy trình kiểm thử bài bản để kiểm soát hành vi, tăng độ tin cậy và giảm thiểu rủi ro cho các hệ thống AI.
Những điểm chính
- Bản chất kiểm thử: Hiểu rõ tại sao các phương pháp kiểm thử truyền thống là không đủ cho AI Agent, từ đó tập trung vào việc đánh giá "quy trình tư duy" (Reasoning Path) thay vì chỉ kết quả cuối cùng.
- Quản trị rủi ro: Nhận diện và kiểm soát các lỗi nghiêm trọng như ảo giác, vòng lặp vô tận, lỗi gọi công cụ và sự lệch hướng chỉ dẫn.
- Quy trình 3 bước: Áp dụng lộ trình bài bản từ xây dựng Golden Dataset, thiết lập Agentic Metrics chuyên dụng, đến sử dụng kỹ thuật LLM-as-a-judge để đánh giá tự động.
- Công cụ hỗ trợ: Tận dụng các nền tảng như DeepEval (Unit test), LangSmith (Tracing), và Galileo (QA chuyên sâu) để tự động hóa và trực quan hóa quy trình đánh giá.
- Thực thi hiệu quả: Áp dụng tư duy kiểm thử đơn lẻ trước khi tiến tới hội thoại phức tạp và tích hợp vào pipeline CI/CD để đảm bảo chất lượng liên tục.
- Giải đáp FAQ: Nắm bắt chiến lược tối ưu chi phí kiểm thử, cách sử dụng Guardrails để chặn hành vi nguy hiểm và kỹ thuật phân tích log để truy tìm nguyên nhân gốc rễ.
AI Agent Testing là gì? Tại sao giải pháp kiểm thử truyền thống là không đủ
AI Agent Testing là quá trình đánh giá xem một AI Agent có thực hiện nhiệm vụ đúng, an toàn và ổn định trong các điều kiện thực tế hay không. Thay vì chỉ so sánh input - output như kiểm thử phần mềm truyền thống, nó tập trung vào cách Agent suy luận, chọn tool, xử lý ngữ cảnh và hoàn thành mục tiêu trong các kịch bản đa bước, phi định hướng.
Việc kiểm thử phần mềm truyền thống (Unit/Integration test) dựa trên logic xác định: Input A luôn tạo ra Output B. Tuy nhiên, AI Agent hoạt động dựa trên xác suất và cơ chế suy luận (Reasoning), khiến đầu ra trở nên phi định hướng – tức là cùng một yêu cầu có thể cho ra các phản hồi khác nhau.
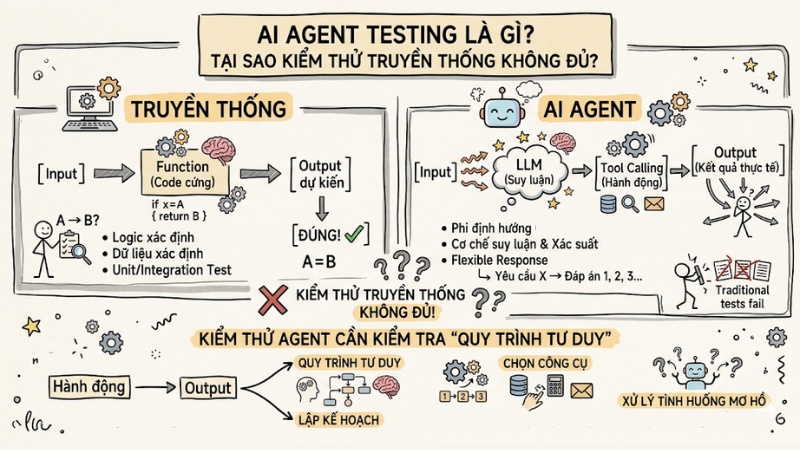
Sơ đồ mô tả quy trình kiểm thử AI Agent
- Truyền thống: Input -> Function (Code cứng) -> Output dự kiến.
- AI Agent: Input -> LLM (Suy luận) -> Tool Calling (Hành động) -> Output (Kết quả thực tế).
Kiểm thử Agent không chỉ là kiểm tra đầu ra, mà là kiểm tra "quy trình tư duy". Bạn cần đánh giá cách Agent lập kế hoạch, chọn công cụ và xử lý các tình huống mơ hồ. Việc áp dụng các bài kiểm tra "cứng" truyền thống thường thất bại vì chúng không thể bắt kịp sự linh hoạt trong phản hồi của AI.
Những rủi ro phổ biến cần kiểm tra ngay trong AI Agent
Khi vận hành Agent, bạn cần đặc biệt lưu ý các điểm lỗi tiềm ẩn sau:
- Ảo tưởng AI (AI Hallucination): Agent tự tin đưa ra thông tin sai lệch hoặc không có thực.
- Vòng lặp vô tận (Infinite Loops): Agent bị kẹt khi thực hiện một chuỗi suy luận sai mà không thể dừng lại.
- Lỗi sử dụng công cụ (Tool Calling Error): Gọi sai API, truyền sai tham số hoặc hiểu sai định dạng dữ liệu trả về từ công cụ.
- Lệch hướng chỉ dẫn (Instruction Drift): Qua nhiều bước suy luận, Agent quên mất yêu cầu gốc ban đầu của người dùng.
- Lỗi xác thực tham số (Parameter Validation): Không kiểm soát được dữ liệu đầu vào nguy hiểm có thể dẫn đến tấn công hoặc lỗi hệ thống.
Quy trình 3 bước kiểm thử AI Agent cho người mới
Để bắt đầu, bạn hãy áp dụng quy trình kiểm thử từ cấp độ thành phần đến toàn diện:
1. Xây dựng Golden Dataset
Golden Dataset là “bộ đề thi chuẩn” gồm các cặp [Prompt – Context – Kết quả mong đợi]. Bạn hãy thu thập những tình huống thực tế mà Agent cần xử lý tốt và lưu lại có hệ thống, vì bộ dữ liệu này sẽ là nền tảng để đo mức độ tiến bộ của Agent giữa các phiên bản khác nhau.
2. Thiết lập bộ chỉ số (Agentic Metrics)
Thay vì chỉ kiểm tra đúng/sai theo câu trả lời, bạn cần một nhóm chỉ số chuyên dụng để đo hiệu suất:
- Task Completion: Tỉ lệ Agent hoàn thành được mục tiêu cuối cùng.
- Reasoning Path Accuracy: Mức độ hợp lý của chuỗi bước trung gian (Agent có đi vòng vèo, thừa bước hay không).
- Tool Call Accuracy: Độ chính xác của việc chọn công cụ và tham số truyền vào.
3. Phương pháp LLM-as-a-Judge (kết hợp con người)
Bạn có thể sử dụng một LLM mạnh hơn (ví dụ GPT-4o) để làm "giám khảo" đánh giá kết quả của Agent đang kiểm thử dựa trên tiêu chí định sẵn. Kết hợp với sự thẩm định của chuyên gia con người (Human-in-the-loop) đối với những mẫu thử khó hoặc nhạy cảm để đảm bảo tính an toàn.
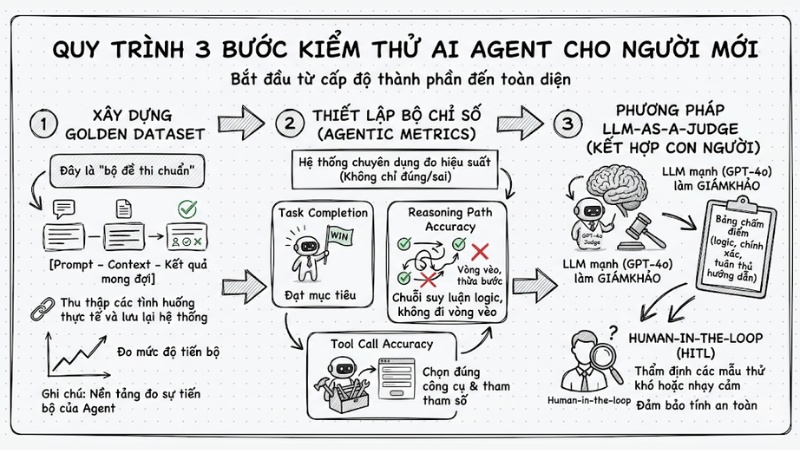
Quy trình 3 bước kiểm thử AI Agent cho người mới
Các công cụ hỗ trợ kiểm thử AI Agent phổ biến
Việc sử dụng công cụ giúp tự động hóa quá trình đánh giá và lưu vết (tracing), cụ thể như sau:
| Công cụ | Phù hợp cho | Đặc điểm |
|---|---|---|
| DeepEval | Unit Testing cho LLM. | Hỗ trợ kiểm thử logic, đánh giá kết quả bằng metric tự động. |
| LangChain (LangSmith) | Observability & Tracing. | Theo dõi toàn bộ luồng tư duy và quá trình gọi công cụ của Agent. |
| Galileo | QA chuyên sâu. | Nền tảng quản lý chất lượng AI, phát hiện sớm các lỗi về prompt và dữ liệu. |
Ví dụ snippet (DeepEval):
from deepeval.metrics import ToolCallMetric
from deepeval.test_case import LLMTestCase
# Kiểm tra xem Agent có chọn đúng Tool không
test_case = LLMTestCase(input="Đặt lịch họp", actual_output="call_tool: calendar_api")
metric = ToolCallMetric(threshold=0.9)
metric.measure(test_case)
Bí quyết thực thi kiểm thử AI Agent hiệu quả
Để việc kiểm thử AI Agent không chỉ dừng lại ở “chạy thử cho biết”, mà thật sự giúp bạn kiểm soát chất lượng và bắt lỗi sớm, hãy lưu ý một vài bí quyết sau:
- Kiểm thử đơn lẻ trước (Single-turn): Trước khi test các hội thoại phức tạp, hãy đảm bảo Agent làm đúng các tác vụ đơn lẻ (như trích xuất dữ liệu, gọi API).
- Đọc kỹ Logs/Traces: Khi Agent thất bại, đừng chỉ nhìn kết quả cuối. Bạn hãy mở log để xem bước nào trong chuỗi suy luận (Reasoning path) làm Agent bị lệch hướng (Root Cause Analysis).
- Tự động hóa trong CI/CD: Đưa các bộ "Golden Dataset" vào pipeline. Mỗi khi cập nhật Prompt hoặc cấu hình Model, hệ thống sẽ tự chạy test để tránh việc "sửa một lỗi, sinh ra mười lỗi".
- Tập trung vào Context: Đảm bảo Agent giữ vững ngữ cảnh trong các hội thoại đa vòng (Multi-turn) bằng cách kiểm tra khả năng nhớ lại thông tin trước đó.
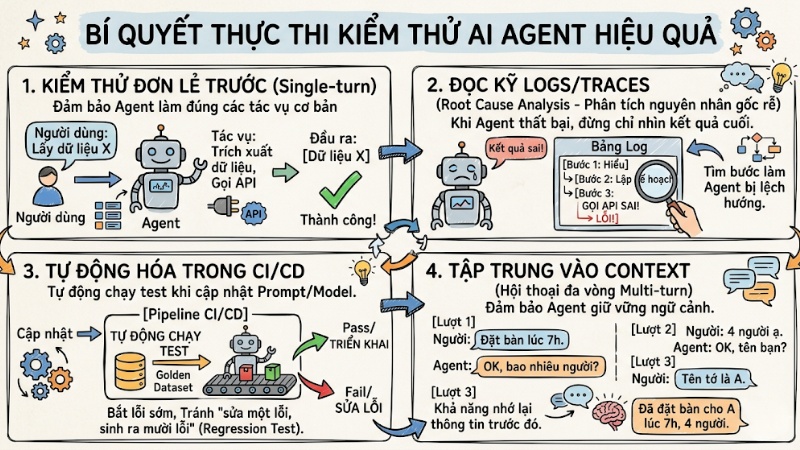
Bí quyết thực thi kiểm thử AI Agent hiệu quả
Giải đáp thắc mắc thường gặp khi test AI agent
Tại sao chi phí kiểm thử AI Agent lại cao?
Test AI agent thường có chi phí cao do cần sử dụng các mô hình (LLM-as-a-Judge) để đánh giá và chạy nhiều vòng lặp. Để tối ưu, bạn hãy sử dụng các model nhỏ hơn (SLM) cho các bài test đơn giản và chỉ dùng model lớn cho các trường hợp phức tạp.
Làm thế nào để kiểm soát hành vi "tự ý" của Agent?
Bạn cần thiết lập các Guardrails (hàng rào an toàn) cứng trong hệ thống để chặn các đầu ra không hợp lệ hoặc các lệnh gọi API nguy hiểm trước khi chúng thực thi.
Stress testing cho AI Agent là gì?
Stress testing là quá trình cố tình cung cấp dữ liệu độc hại hoặc prompt chứa lỗ hổng để xem Agent có tuân thủ các quy tắc an toàn hay không.
Kiểm thử Multi-turn có khó hơn Single-turn không?
Có, vì lỗi ở vòng trước có thể kéo theo sự suy giảm logic ở vòng sau (Compound error). Do đó bạn cần thiết lập kịch bản thay vì chỉ kiểm tra từng câu đơn lẻ.
AI Agent Testing là gì?
AI Agent Testing là quá trình đánh giá và xác minh hoạt động của các hệ thống AI Agent, tập trung vào khả năng suy luận, sử dụng công cụ, và hoàn thành mục tiêu một cách tự động. Khác với kiểm thử phần mềm truyền thống, nó chú trọng vào tính phi quyết định và khả năng "tư duy" của Agent.
Tại sao kiểm thử truyền thống không đủ cho AI Agent?
Kiểm thử truyền thống dựa trên quy tắc "input-output" cố định, không phù hợp với bản chất phi quyết định của AI Agent. AI Agent có thể đưa ra các phản hồi khác nhau cho cùng một đầu vào, khiến các bài kiểm thử cố định trở nên lỗi thời và không hiệu quả.
Những rủi ro phổ biến cần kiểm tra trong AI Agent là gì?
Các rủi ro phổ biến bao gồm ảo tưởng (hallucination) về thông tin, vòng lặp vô tận trong quá trình suy luận, lỗi sử dụng công cụ hoặc tham số không chính xác và việc Agent bị lệch khỏi mục tiêu ban đầu.
Làm thế nào để xây dựng "Golden Dataset" cho AI Agent Testing?
"Golden Dataset" được xây dựng bằng cách thu thập các cặp dữ liệu bao gồm Prompt (lời nhắc), Context (ngữ cảnh) và Expected Result (kết quả mong đợi). Dữ liệu này đóng vai trò là bộ đề thi chuẩn để đánh giá hiệu suất và tính chính xác của AI Agent.
Các chỉ số quan trọng khi đánh giá AI Agent là gì?
Các chỉ số chính bao gồm Task Completion (hoàn thành nhiệm vụ), Reasoning Path (logic suy luận), Tool Call Accuracy (độ chính xác khi gọi công cụ) và Instruction Adherence (mức độ tuân thủ chỉ dẫn ban đầu).
Có thể kết hợp kiểm thử AI Agent với chuyên gia con người không?
Có, việc kết hợp chuyên gia con người (Human-in-the-loop) là rất quan trọng. Chuyên gia sẽ thẩm định kết quả do AI tạo ra, đặc biệt là trong các trường hợp phức tạp hoặc khi sử dụng phương pháp "LLM-as-a-Judge" để đảm bảo tính khách quan và đúng đắn.
Các công cụ phổ biến để kiểm thử AI Agent?
Các công cụ phổ biến bao gồm DeepEval, LangChain và Galileo. DeepEval mạnh về các chỉ số đánh giá, LangChain hỗ trợ xây dựng luồng Agent và tích hợp, còn Galileo cung cấp nền tảng toàn diện cho việc đánh giá và vận hành.
Làm thế nào để đưa kiểm thử AI Agent vào CI/CD pipeline?
Bạn có thể tích hợp các bài kiểm thử dựa trên "Golden Dataset" và các chỉ số đánh giá vào CI/CD pipeline. Điều này giúp tự động hóa quy trình kiểm thử mỗi khi có thay đổi về Prompt hoặc cấu trúc Agent, đảm bảo chất lượng liên tục.
Nên bắt đầu kiểm thử AI Agent với Single-turn hay Multi-turn?
Nên bắt đầu với kiểm thử Single-turn trước. Khi Agent có khả năng xử lý một lượt tương tác hoàn chỉnh, bạn mới nên chuyển sang kiểm thử Multi-turn phức tạp hơn, nơi Agent cần duy trì ngữ cảnh qua nhiều lượt hội thoại.
Làm thế nào để phân tích lỗi trong AI Agent bằng cách đọc Logs (Trace)?
Logs (hay Trace) ghi lại chi tiết luồng dữ liệu và quyết định của Agent. Bằng cách phân tích Trace, bạn có thể xác định các điểm thất bại trong quá trình suy luận, sử dụng công cụ, hoặc xử lý ngữ cảnh, từ đó tìm ra nguyên nhân gốc rễ của lỗi.
Xem thêm:
- Cách Debug AI Agent: Quy trình từ Log JSON đến trực quan hóa
- Hướng dẫn Build AI Agent để tự động hóa quy trình hiệu quả
- AI Agent Observability: Cách giám sát hệ thống AI Agent cho doanh nghiệp
Tóm lại, kiểm thử AI Agent là một quá trình liên tục nhằm đảm bảo hệ thống suy luận đúng, dùng tool chính xác và luôn bám sát mục tiêu ban đầu. Khi bạn xây dựng được Golden Dataset, thiết lập bộ Agentic Metrics và kết hợp LLM-as-a-judge với chuyên gia con người, việc đánh giá sẽ trở nên vừa tự động vừa đáng tin cậy. Cuối cùng, hãy đưa toàn bộ quy trình test này vào CI/CD để mỗi lần thay đổi model, prompt hay kiến trúc Agent đều được kiểm soát chặt chẽ trước khi tới tay người dùng.