How to Test AI Agents: Process and Performance Evaluation Methods

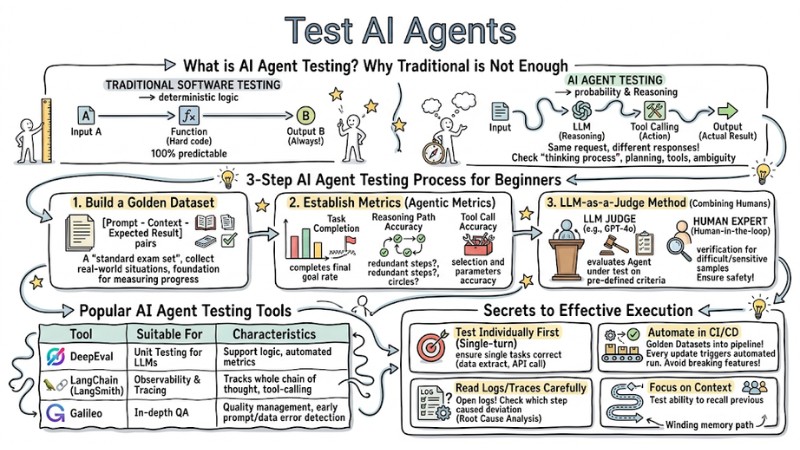
Test AI Agent (also understood as AI Agent testing) is the process of ensuring that automated systems based on Large Language Models (LLMs) can reason, use tools, and complete tasks accurately. The following article will help engineers and product managers build a systematic testing process to control behavior, increase reliability, and minimize risks for AI systems.
Key Takeaways
- Nature of Testing: Understand why traditional testing methods are insufficient for AI Agents, thereby focusing on evaluating the "Reasoning Path" instead of just the final result.
- Risk Governance: Identify and control critical errors such as hallucinations, infinite loops, tool-calling errors, and instruction drift.
- 3-Step Process: Apply a methodical roadmap from building a Golden Dataset and setting up specialized Agentic Metrics to using the LLM-as-a-judge technique for automated evaluation.
- Supporting Tools: Leverage platforms like DeepEval (Unit testing), LangSmith (Tracing), and Galileo (In-depth QA) to automate and visualize the evaluation process.
- Effective Execution: Apply a single-turn testing mindset before progressing to complex conversations and integrate into CI/CD pipelines to ensure continuous quality.
- FAQ: Capture strategies for optimizing testing costs, using Guardrails to block dangerous behavior, and log analysis techniques to trace root causes.
What is AI Agent Testing? Why Traditional Testing Solutions Are Not Enough
Traditional software testing (Unit/Integration tests) is based on deterministic logic: Input A always produces Output B. However, AI Agents operate based on probability and Reasoning mechanisms, making the output non-deterministic - meaning the same request can yield different responses.
- Traditional: Input -> Function (Hard code) -> Expected Output.
- AI Agent: Input -> LLM (Reasoning) -> Tool Calling (Action) -> Output (Actual Result).
Agent testing is not just about checking the output, but checking the "thinking process." You need to evaluate how the Agent plans, selects tools, and handles ambiguous situations. Applying traditional "rigid" tests often fails because they cannot keep up with the flexibility of AI responses.
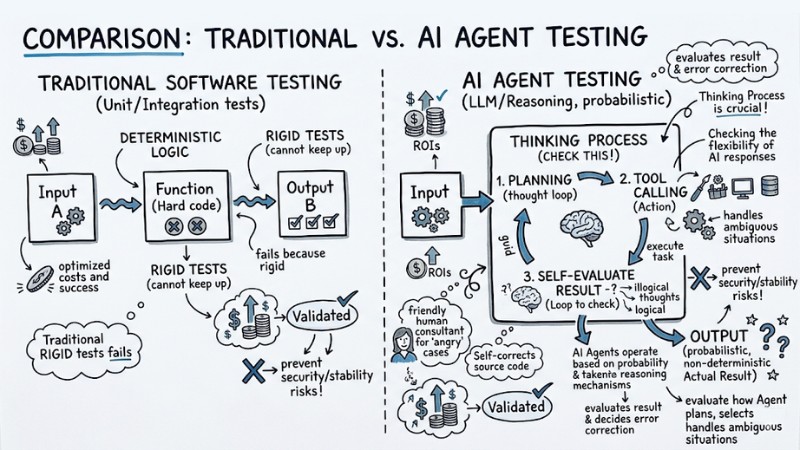
The diagram illustrates the AI Agent testing process
Common Risks to Check Immediately in AI Agents
When operating an Agent, you should pay special attention to the following potential failure points:
- Hallucination: The Agent confidently provides incorrect or non-existent information.
- Infinite Loops: The Agent gets stuck performing a chain of incorrect reasoning that it cannot stop.
- Tool Calling Error: Calling the wrong API, passing incorrect parameters, or misunderstanding the data format returned from the tool.
- Instruction Drift: Over many reasoning steps, the Agent forgets the user's original request.
- Parameter Validation: Failure to control dangerous input data can lead to attacks or system errors.
3-Step AI Agent Testing Process for Beginners
To start, apply a testing process from the component level to the comprehensive level:
1. Build a Golden Dataset
This is a "standard exam set" consisting of [Prompt - Context - Expected Result] pairs. Collect real-world situations that the Agent needs to handle well and save them systematically, as this dataset will be the foundation for measuring the Agent's progress across different versions.
2. Establish a Set of Metrics (Agentic Metrics)
Instead of just checking right/wrong based on the answer, you need a specialized group of metrics to measure performance:
- Task Completion: The rate at which the Agent completes the final goal.
- Reasoning Path Accuracy: The reasonableness of the intermediate step chain (whether the Agent goes in circles or takes redundant steps).
- Tool Call Accuracy: The accuracy of tool selection and the parameters passed in.
3. LLM-as-a-Judge Method (Combining Humans)
You can use a more powerful LLM (e.g., GPT-4o) to act as a "judge" to evaluate the results of the Agent under test based on pre-defined criteria. Combine this with verification by human experts (Human-in-the-loop) for difficult or sensitive test samples to ensure safety.
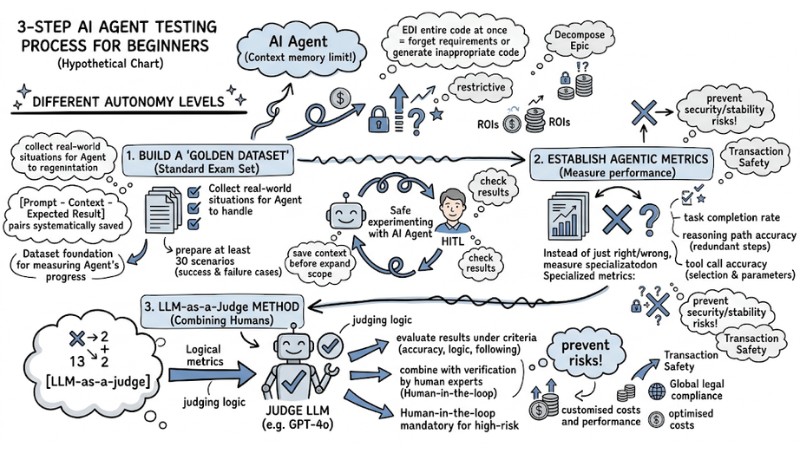
3-Step AI Agent Testing Process for Beginners
Popular AI Agent Testing Support Tools
Using tools helps automate the evaluation and tracing process, specifically:
| Tool | Suitable For | Characteristics |
|---|---|---|
| DeepEval | Unit Testing for LLMs. | Supports logic testing, evaluates results using automated metrics. |
| LangChain (LangSmith) | Observability & Tracing. | Tracks the entire chain of thought and the Agent's tool-calling process. |
| Galileo | In-depth QA. | AI quality management platform, early detection of prompt and data errors. |
Ví dụ snippet (DeepEval):
from deepeval.metrics import ToolCallMetric
from deepeval.test_case import LLMTestCase
# Verify if the Agent selects the correct Tool
test_case = LLMTestCase(input="Schedule a meeting", actual_output="call_tool: calendar_api")
metric = ToolCallMetric(threshold=0.9)
metric.measure(test_case)
Secrets to Effective AI Agent Testing Execution
To ensure AI Agent testing doesn't just stop at "running it to see," but truly helps you control quality and catch errors early, keep these tips in mind:
- Test Individually First (Single-turn): Before testing complex conversations, ensure the Agent performs single tasks correctly (such as data extraction or API calling).
- Read Logs/Traces Carefully: When an Agent fails, don't just look at the final result. Open the logs to see which step in the reasoning path caused the Agent to deviate (Root Cause Analysis).
- Automate in CI/CD: Put "Golden Datasets" into the pipeline. Every time a Prompt or Model configuration is updated, the system will automatically run tests to avoid "fixing one error, creating ten more."
- Focus on Context: Ensure the Agent maintains context in multi-turn conversations by testing its ability to recall previous information.
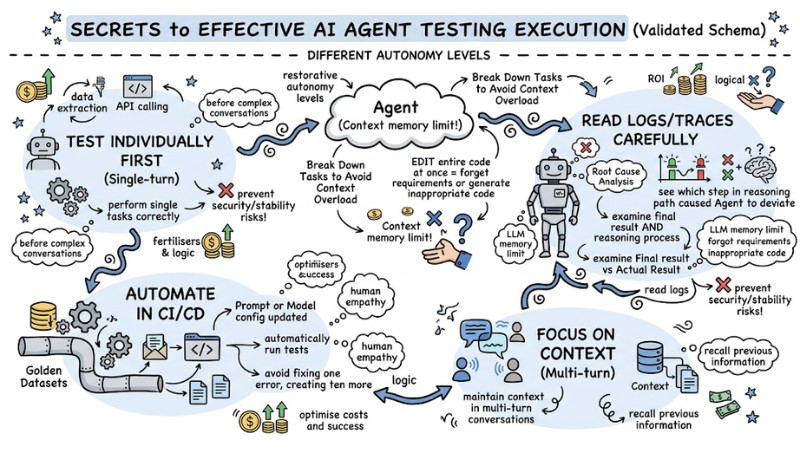
Guide to effectively executing AI Agent testing
FAQ
Why is AI Agent testing expensive?
AI Agent testing often has high costs due to the need for models (LLM-as-a-Judge) to evaluate and run multiple iterations. To optimize, use smaller models (SLM) for simple tests and only use large models for complex cases.
How to control "arbitrary" behavior of the Agent?
You need to set up rigid Guardrails in the system to block invalid outputs or dangerous API calls before they execute.
What is AI Agent Testing?
AI Agent Testing is the process of evaluating and verifying the operation of AI Agent systems, focusing on the ability to reason, use tools, and complete goals automatically. Unlike traditional software testing, it emphasizes non-determinism and the Agent's "thinking" ability.
How to build a "Golden Dataset" for AI Agent Testing?
A "Golden Dataset" is built by collecting data pairs including the Prompt, Context, and Expected Result. This data acts as a standard exam set to evaluate the performance and accuracy of the AI Agent.
What are the important metrics when evaluating an AI Agent?
Key metrics include Task Completion, Reasoning Path, Tool Call Accuracy, and Instruction Adherence.
How to analyze errors in an AI Agent by reading Logs (Trace)?
Logs (or Trace) record the detailed data flow and the Agent's decisions. By analyzing the Trace, you can pinpoint failure points in reasoning, tool usage, or context handling, thereby finding the root cause of the error.
Read more:
- Debugging AI Agents: A Workflow from JSON Logs to Visualization
- Guide to Building AI Agents for Efficient Workflow Automation
- AI Agent Observability: How to Monitor AI Agent Systems for Business
In summary, AI Agent testing is a continuous process to ensure the system reasons correctly, uses tools accurately, and always stays close to the original goal. When you build a Golden Dataset, establish a set of Agentic Metrics, and combine LLM-as-a-judge with human experts, evaluation becomes both automated and reliable. Finally, bring this entire test process into CI/CD so that every change in the model, prompt, or Agent architecture is strictly controlled before reaching users.
Tags