AI Agent Production Checklist: 10 bước triển khai an toàn

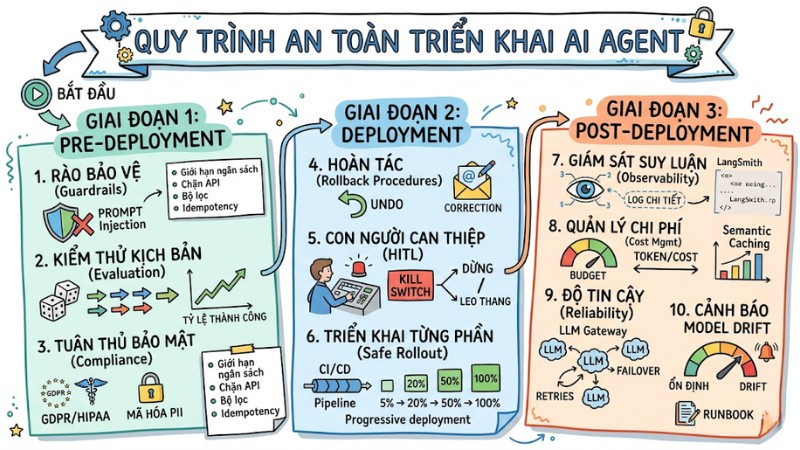
AI Agent Production Checklist là bộ tiêu chí và bước triển khai giúp đưa AI Agent từ giai đoạn thử nghiệm sang môi trường production một cách an toàn, có kiểm soát về rủi ro và chi phí vận hành. Bài viết này trình bày AI Agent Production Checklist theo ba giai đoạn chính là Pre‑deployment, Deployment và Post‑deployment cùng các thực tiễn kỹ thuật cụ thể cho từng giai đoạn.
Những điểm chính
- Giai đoạn Pre-Deployment: Hiểu rõ quy trình thiết lập rào bảo vệ, kiểm thử kịch bản và quản trị rủi ro để đảm bảo AI Agent vận hành an toàn và tuân thủ bảo mật trước khi ra mắt.
- Giai đoạn Deployment: Nắm vững cơ chế hoàn tác, quy trình con người can thiệp và chiến lược triển khai từng phần nhằm duy trì tính ổn định và kiểm soát rủi ro hệ thống hiệu quả.
- Giai đoạn Post-Deployment: Biết cách giám sát suy luận, quản lý chi phí token và thiết lập cơ chế chịu lỗi để tối ưu hóa hiệu năng vận hành và duy trì sự tin cậy của AI Agent về lâu dài.
- Giải đáp thắc mắc: Được làm rõ các rủi ro phổ biến, cách thức gỡ lỗi và phương pháp ước tính chi phí giúp người dùng tự tin quản lý và vận hành AI Agent trong môi trường thực tế.
Giai đoạn 1: Pre-Deployment - Chuẩn bị và đánh giá an toàn trước khi triển khai
1. Thiết lập rào bảo vệ an toàn (Automated Guardrails)
Rào bảo vệ tự động (Guardrails) là lớp kiểm soát nằm giữa AI Agent và hệ thống lõi, có chức năng giảm rủi ro ảo giác (AI hallucination), ngăn prompt injection và giới hạn các hành động vượt ngoài chính sách. Một nguyên tắc quan trọng là bảo đảm mọi tool mà Agent gọi đều hỗ trợ idempotency. Điều này có nghĩa là gọi lặp lại một lệnh hợp lệ nhiều lần không làm thay đổi trạng thái hệ thống ngoài kết quả mong đợi.
Checklist rào bảo vệ:
- Giới hạn ngân sách cứng (hard limit) cho mỗi phiên làm việc của AI.
- Chặn quyền truy cập các API/Database không thuộc phạm vi tác vụ.
- Tích hợp bộ lọc thời gian thực để chặn đầu ra vi phạm chính sách.
- Áp dụng Idempotency cho các tác vụ gọi công cụ (tool calls).
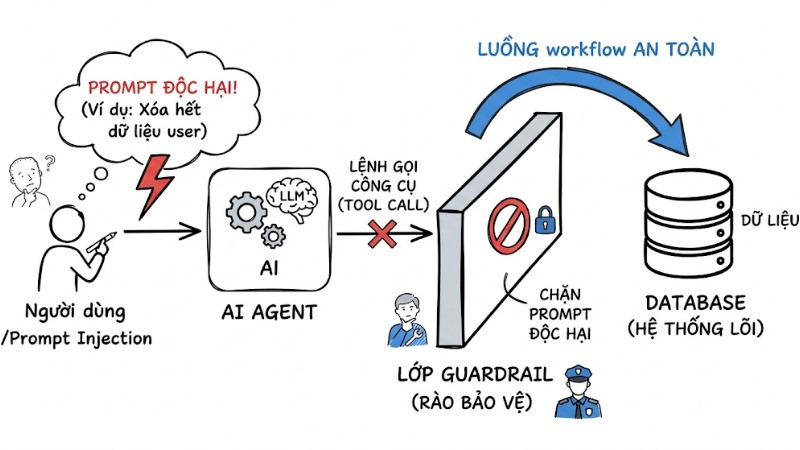
Prompt độc hại bị chặn bởi lớp Guardrail trước khi tiếp cận database
2. Kiểm thử và đánh giá kịch bản (Evaluation & Simulation)
Không giống hệ thống phần mềm mang tính xác định, AI Agent hoạt động dựa trên mô hình xác suất nên cần được kiểm thử bằng nhiều kịch bản giả lập và điều kiện cực đoan trước khi đưa vào môi trường thực tế.
- Đánh giá tỷ lệ hoàn thành tác vụ (Task success rate): Chạy hàng chục đến hàng trăm lượt mô phỏng cho mỗi kịch bản để đo tỷ lệ nhiệm vụ được hoàn thành đúng, thời gian xử lý và số bước cần thiết.
- Kiểm tra khả năng sử dụng công cụ tự chủ: Thiết kế bài test cho các tình huống tool trả về dữ liệu thiếu, lỗi hoặc chậm để xem Agent có xử lý retry, fallback và báo lỗi theo đúng quy tắc hay không.
- Tiêm dữ liệu nhiễu để kiểm tra độ bền vững: Đưa vào các đầu vào mơ hồ, mâu thuẫn hoặc phản hồi tool nhiễu để đánh giá mức độ suy giảm hiệu năng và khả năng phục hồi của agent dưới các điều kiện không lý tưởng.
3. Tuân thủ bảo mật và quản trị rủi ro (AI Governance & Risk Management)
Thiết kế bảo mật cho AI Agent cần cân bằng giữa yêu cầu bảo vệ dữ liệu và độ trễ chấp nhận được của hệ thống khi hoạt động trong môi trường thực tế.
- Mã hóa và ẩn danh dữ liệu nhạy cảm: Thực hiện ẩn danh hoặc pseudonym hóa toàn bộ PII/PHI trước khi gửi qua LLM API để đáp ứng yêu cầu về bảo vệ dữ liệu cá nhân và giảm rủi ro lộ thông tin.
- Lưu trữ audit log đầy đủ: Ghi lại toàn bộ prompt, phản hồi và hành động liên quan dưới dạng nhật ký kiểm toán để phục vụ truy vết, điều tra sự cố và đáp ứng yêu cầu tuân thủ như HIPAA hoặc GDPR.
- Bảo đảm tuân thủ quy định: Thiết kế luồng dữ liệu phù hợp với các chuẩn như GDPR và HIPAA khi xử lý dữ liệu y tế hoặc tài chính, bao gồm nguyên tắc “minimum necessary”, kiểm soát truy cập và thời gian lưu trữ.
- Kết hợp mô hình cục bộ và Cloud LLM: Sử dụng mô hình mã nguồn mở chạy cục bộ để nhận diện và lọc dữ liệu nhạy cảm trước, sau đó chỉ gửi phần nội dung đã được xử lý lên Cloud LLM nhằm tối ưu đồng thời bảo mật và hiệu năng.
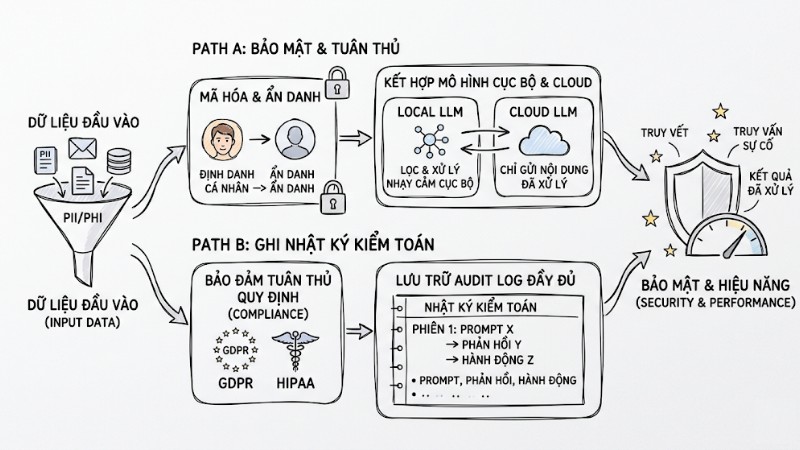
Tuân thủ bảo mật và quản trị rủi ro cho dữ liệu đầu vào
Giai đoạn 2: Deployment - Cấu trúc vận hành và triển khai an toàn
4. Quy trình hoàn tác và xử lý trạng thái (Rollback Procedures)
Đảm bảo an toàn giao dịch với AI Agent đòi hỏi mọi thay đổi trạng thái phải có khả năng quay lui, vì đầu ra của mô hình không hoàn toàn dự đoán được trước.
Checklist Rollback:
- Phân tách rõ luồng chỉ đọc và luồng có quyền ghi dữ liệu.
- Mỗi thao tác cập nhật hoặc xóa cần có một hành động hoàn tác tương ứng đi kèm.
- Chuỗi tác vụ nhiều bước phải hỗ trợ tự động rollback khi xảy ra lỗi ở bước trung gian để tránh trạng thái dở dang.
Ví dụ, nếu AI Agent đã gửi email thông báo hoàn tiền nhưng giao dịch qua cổng thanh toán thất bại, hệ thống cần có khả năng tự động gửi email đính chính hoặc thực hiện hành động bù trừ đã được định nghĩa sẵn. Việc thiết kế một cơ chế “Undo” ở mức hệ thống cho các thay đổi do AI kích hoạt giúp đội vận hành kiểm soát rủi ro tốt hơn và tăng mức độ tin cậy khi triển khai Agent vào quy trình thật.
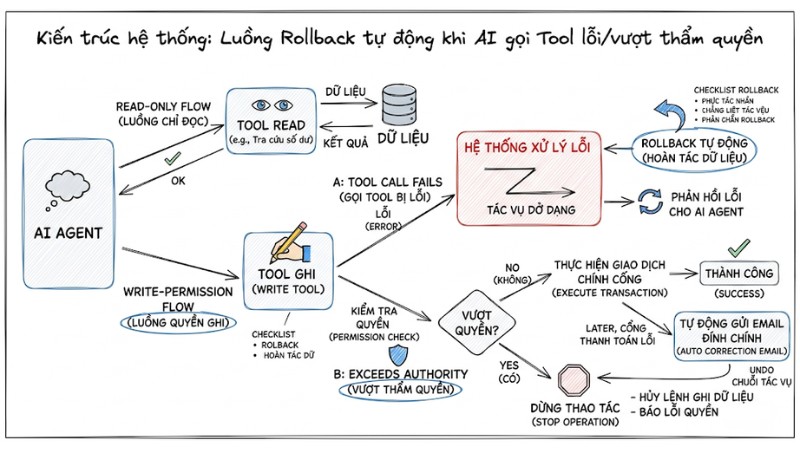
Luồng Rollback tự động khi AI gọi Tool bị lỗi hoặc vượt quá thẩm quyền
5. Cơ chế con người can thiệp (Human-in-the-loop - HITL)
Human‑in‑the‑loop là cơ chế đưa con người vào vòng lặp ra quyết định của AI, yêu cầu phê duyệt thủ công trước khi Agent thực hiện các hành động có rủi ro cao hoặc thay đổi trạng thái hệ thống.
Checklist cơ chế can thiệp:
- Xác định rõ workflow phê duyệt cho các giao dịch vượt hạn mức hoặc mang tính nhạy cảm.
- Cài đặt kill switch ở lớp điều phối để có thể dừng hoặc tạm ngắt toàn bộ hành vi của Agent khi phát hiện bất thường.
- Thiết kế lộ trình leo thang với điều kiện kích hoạt cụ thể để chuyển các tình huống không chắc chắn hoặc rủi ro cao sang cho con người xử lý.
HITL không nên áp dụng cho mọi tác vụ để tránh gây quá tải phê duyệt và làm mất hiệu quả tự động hóa. Thay vào đó, nên tập trung vào các hành động liên quan đến giao dịch tài chính, thay đổi hoặc xóa dữ liệu, hay tương tác với nhóm khách hàng có mức độ ưu tiên cao.
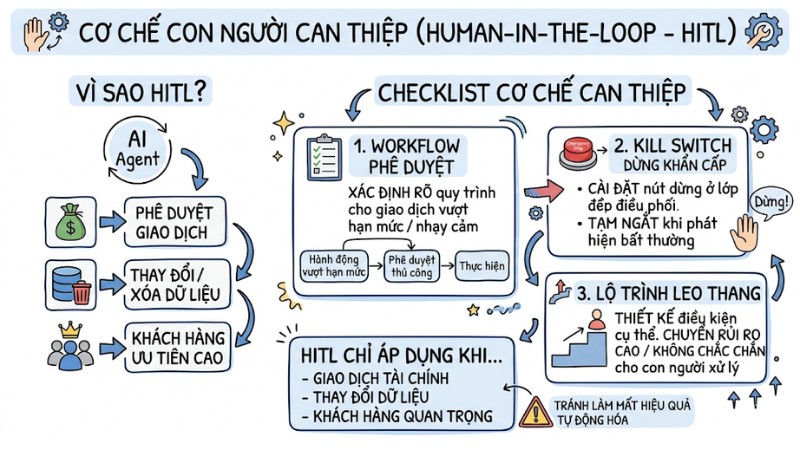
Cơ chế Human‑in‑the‑loop trong AI Agent
6. Chiến lược triển khai từng phần (Safe Rollout)
Trong giai đoạn triển khai, nên áp dụng chiến lược rollout từng bước nhằm giới hạn rủi ro và quan sát kỹ hiệu năng của phiên bản AI Agent mới trước khi áp dụng cho toàn bộ người dùng.
- Tích hợp các bước đánh giá chất lượng tự động vào pipeline CI/CD để chặn triển khai nếu độ chính xác hoặc độ trễ không đạt ngưỡng cho phép.
- Thực hiện A/B testing giữa phiên bản cũ và mới, so sánh các chỉ số như tỷ lệ hoàn thành tác vụ và lỗi.
- Sử dụng Kubernetes hoặc nền tảng tương tự để triển khai progressive rollout, bắt đầu với một tỷ lệ người dùng nhỏ như 5% nội bộ, sau đó tăng dần lên 20%, 50% và cuối cùng 100% khi các chỉ số vẫn ổn định.
Giai đoạn 3: Post-Deployment - Giám sát và tối ưu hóa vận hành
7. Giám sát suy luận và luồng thực thi (Agent Observability)
Agent observability mở rộng khái niệm giám sát truyền thống, không chỉ đo uptime và latency mà còn cho phép theo dõi chi tiết từng bước suy luận, tool call và context mà AI Agent sử dụng trong quá trình xử lý.
Checklist cấu trúc Log:
- Ghi lại đầy đủ prompt đầu vào và phản hồi đầu ra cho từng lần gọi LLM.
- Theo dõi mọi lần thực thi công cụ cùng tham số đầu vào, kết quả trả về và mã lỗi nếu có.
- Lưu log dưới dạng JSON có cấu trúc để dễ dàng truy vấn, lọc và dựng dashboard khi cần phân tích hoặc xử lý sự cố.
Nên ưu tiên sử dụng các nền tảng quan sát chuyên dụng như LangSmith, Langfuse hoặc Datadog LLM Observability. Chúng cung cấp sẵn tracing cho toàn bộ chuỗi tác vụ, hiển thị trực quan đường đi của request và rút ngắn thời gian điều tra sự cố xuống mức phù hợp với yêu cầu vận hành production.
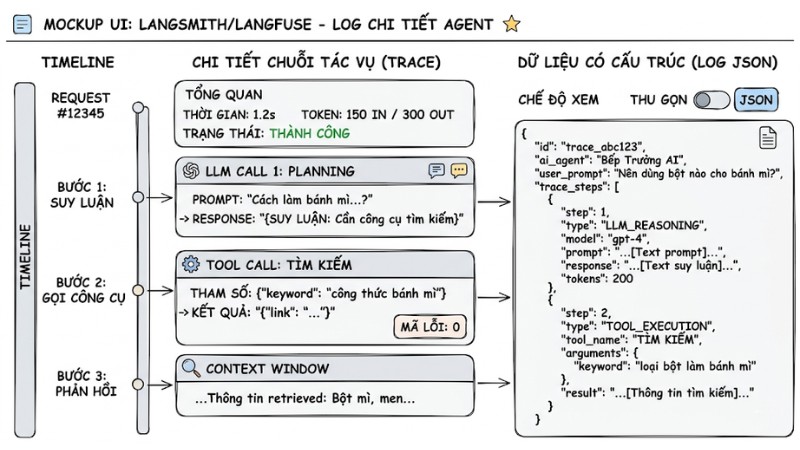
Công cụ LangSmith/Langfuse hiển thị log chi tiết của một chuỗi suy luận Agentic
8. Quản lý chi phí và tiêu thụ token (AI Cost Management)
Quản lý chi phí cho AI Agent cần kết hợp kiểm soát token, mô hình và cảnh báo ngân sách để tránh các kịch bản tiêu thụ ngoài ý muốn khi hệ thống hoạt động lâu dài.
| Tiêu chí | Semantic caching | Budget limits | Model routing |
|---|---|---|---|
| Cơ chế hoạt động | Lưu và tái sử dụng câu trả lời cho các truy vấn có ngữ nghĩa tương tự thay vì gọi lại LLM cho mỗi lần hỏi. | Đặt ngưỡng tối đa cho số token hoặc chi phí trên mỗi phiên, mỗi user hoặc mỗi key và chặn hoặc chuyển hướng khi chạm ngưỡng. | Tự động phân loại tác vụ và gửi yêu cầu đơn giản sang mô hình chi phí thấp, chỉ dùng mô hình cao cấp cho yêu cầu phức tạp. |
| Tác động đến chi phí | Giảm đáng kể số lượt gọi API trùng ý, đặc biệt trên endpoint lưu lượng cao. | Ngăn các vòng lặp hoặc lỗi cấu hình khiến chi phí tăng không kiểm soát. | Giảm phần lớn chi tiêu cho tác vụ đơn giản trong khi vẫn giữ chất lượng ở các điểm chạm quan trọng. |
Ngoài ra, bạn nên gắn thẻ chi phí theo tính năng, dịch vụ hoặc người dùng để phân bổ chính xác. Đồng thời cấu hình cảnh báo qua Slack hoặc email khi mức tiêu thụ token vượt ngưỡng dự kiến.
9. Độ tin cậy và cơ chế chịu lỗi (Reliability & LLM Gateways)
Do API của nhà cung cấp LLM có thể gặp sự cố hoặc giới hạn lưu lượng bất kỳ lúc nào, kiến trúc hệ thống cần được thiết kế sẵn cơ chế chịu lỗi và fallback đa nhà cung cấp.
- Áp dụng exponential backoff cho retry: Khi gặp lỗi tạm thời, hệ thống nên thử lại với khoảng thời gian chờ tăng dần thay vì gửi yêu cầu liên tiếp, nhằm giảm nguy cơ vượt ngưỡng rate limit hoặc bị chặn.
- Sử dụng LLM gateway để tăng độ tin cậy: Đặt một gateway chuyên dụng làm lớp trung gian để cân bằng tải giữa nhiều endpoint, thực hiện retry, theo dõi sức khỏe nhà cung cấp và tự động failover sang provider khác khi phát hiện lỗi.
- Kết hợp nhiều nguồn suy luận: Cấu hình gateway theo mô hình hybrid, ưu tiên provider chính như OpenAI hoặc Anthropic và thiết lập fallback sang mô hình local hoặc open‑source (ví dụ Llama 3) để duy trì dịch vụ khi hạ tầng bên ngoài gặp sự cố.
- Kiểm soát rate limiting và backpressure: Áp dụng giới hạn tần suất và cơ chế backpressure ở tầng gateway để tránh nghẽn cổ chai nội bộ và giảm nguy cơ gián đoạn dịch vụ khi lưu lượng tăng đột biến.
10. Cảnh báo thời gian thực và lệch hướng mô hình (Monitoring & Model Drift)
Ngay cả khi hệ thống ổn định ở thời điểm triển khai, chất lượng đầu ra của AI Agent vẫn có thể suy giảm theo thời gian do dữ liệu và hành vi người dùng thay đổi. Do đó, cần cơ chế giám sát và cảnh báo chủ động.
- Thiết lập cảnh báo thời gian thực cho các lỗi nghiêm trọng ảnh hưởng đến luồng chính, ví dụ như tỷ lệ thất bại tăng đột ngột, độ trễ vượt ngưỡng hoặc chi phí token tăng bất thường.
- Đo lường định kỳ hiện tượng model drift và decision drift bằng cách so sánh kết quả hiện tại với bộ mẫu chuẩn hoặc ngưỡng chất lượng đã xác định.
- Xây dựng runbook chi tiết cho đội on‑call, mô tả các bước kiểm tra, truy vấn log, cách chuyển hướng traffic và tiêu chí rollback để mọi người có thể xử lý cảnh báo một cách nhất quán.
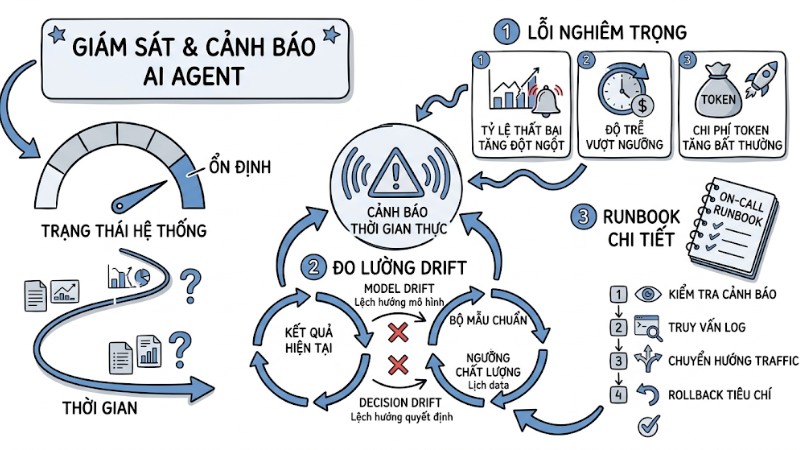
Cảnh báo thời gian thực và lệch hướng mô hình
Giải đáp thắc mắc thường gặp
Các rủi ro phổ biến nhất khi đưa AI Agent lên Production là gì?
- Ảo giác khiến agent tạo ra nội dung sai nhưng vẫn được hệ thống tin tưởng và thực thi.
- Vòng lặp vô tận hoặc workflow tự lặp lại làm tăng số lần gọi LLM, gây đội chi phí token và tải hệ thống.
- Prompt injection và input độc hại khiến Agent làm lộ dữ liệu nhạy cảm, bỏ qua quy tắc hoặc thực thi hành động ngoài phạm vi được phép.
Làm sao để debug khi AI Agent quyết định sai?
Áp dụng Distributed Tracing hoặc Agent Tracing để ghi lại đầy đủ prompt, context, các bước suy luận và tool calls cho từng phiên làm việc, từ đó xác định bước nào dẫn đến quyết định sai. Nên xem lại cả dữ liệu đầu vào lẫn cấu hình tool để phân biệt lỗi do mô hình, do dữ liệu hay do orchestration.
Cách ước tính chi phí token trước khi triển khai?
Ước tính số token trung bình cho system prompt, context truy hồi, user query và output, sau đó nhân với đơn giá input/output token của từng model để ra chi phí cho một request. Khi dùng agent nhiều bước, nên cộng thêm khoảng dự phòng cho các lượt suy luận và tool call bổ sung, ví dụ hệ số tăng 20-30% trên mức ước tính ban đầu.
Khi nào không nên dùng AI Agent?
Không nên sử dụng AI Agent cho luồng công việc cần kết quả hoàn toàn xác định, có quy tắc rõ ràng như CRUD đơn giản hoặc xử lý giao dịch theo quy trình cố định. Cũng không phù hợp với hệ thống yêu cầu độ trễ rất thấp (như dưới khoảng 100 ms) nơi các mô hình nhỏ, rule‑based hoặc dịch vụ chuyên biệt sẽ đảm bảo tốc độ và tính nhất quán tốt hơn.
Xem thêm:
- Hướng dẫn chi tiết cách Deploy AI Agent lên Production hiệu quả
- Hướng dẫn quản lý AI agent permission để đảm bảo an toàn hệ thống
- Hướng dẫn triển khai hệ thống OpenClaw Multi-Agent chi tiết
AI Agent Production Checklist không chỉ là danh sách thao tác kỹ thuật mà là khung vận hành tổng thể để đảm bảo mỗi Agent được triển khai đều có guardrails, quy trình rollback, giám sát và giới hạn chi phí rõ ràng. Khi áp dụng đầy đủ các mục trong checklist này trước, trong và sau khi triển khai, bạn có thể tự tin mở rộng AI Agent lên quy mô lớn mà vẫn duy trì được tính an toàn, độ tin cậy và tính minh bạch trong toàn bộ chuỗi suy luận của hệ thống.
Thẻ