15 Multi-Agent Metrics quan trọng đánh giá hệ thống AI Agent

Kiến trúc Multi-Agent cho phép nhiều tác nhân AI phối hợp để giải quyết các bài toán phức tạp nhưng đồng thời làm tăng rủi ro lỗi dây chuyền nếu không có cơ chế Multi-Agent Metrics để đo lường và kiểm soát. Bài viết này giới thiệu bộ 15 chỉ số Multi-Agent Metrics đánh giá hiệu suất và 5 khung đánh giá thực tế giúp kỹ sư và quản lý kỹ thuật giám sát, tối ưu và kiểm soát hệ thống Multi-Agent một cách có hệ thống.
Những điểm chính
- Khái niệm đo lường Multi-Agent: Hiểu rõ tại sao các chỉ số đơn lẻ như thời gian phản hồi hay chi phí token không còn đủ sức đo lường một hệ thống đa tác nhân phức tạp, nơi một lỗi nhỏ có thể tạo ra hiệu ứng dây chuyền.
- 15 Multi-Agent Metrics quan trọng: Nắm vững bộ chỉ số được chia thành 4 nhóm thiết yếu: Chất lượng kết quả, luồng tương tác, hiệu quả dùng công cụ và bảo mật hệ thống, giúp bạn giám sát toàn diện sức khỏe của AI.
- Công cụ đánh giá: Khám phá ưu nhược điểm của 5 nền tảng phổ biến để đưa ra quyết định phù hợp cho bài toàn của bạn.
- Thách thức thực tiễn: Nhận diện 3 rào cản lớn khi triển khai đánh giá gồm: Xử lý lượng log khổng lồ, kiểm soát các hành vi phát sinh khó dự đoán và bài toán tối ưu chi phí chấm điểm bằng mô hình LLM-as-a-Judge.
- Câu hỏi thường gặp: Được giải đáp các thắc mắc về chỉ số quan trọng nhất khi mới bắt đầu, cách ngăn chặn các Agent tự bịa thông tin khi giao tiếp với nhau và khả năng tự động sửa lỗi của các hệ thống đánh giá hiện tại.
Đo lường hiệu suất hệ thống Multi-Agent
Khái niệm đo lường hiệu suất Multi-Agent
Đo lường hiệu suất Multi-Agent là quá trình đánh giá khả năng phối hợp, độ chính xác khi sử dụng công cụ và mức độ nhất quán giữa nhiều AI Agent trong một nhiệm vụ chung. Phần này tập trung giải thích lý do các chỉ số của Single-Agent không còn đủ, đồng thời làm rõ vai trò của Agent Coordination trong kiến trúc Multi-Agent LLM.
Tại sao latency và token cost của Single-Agent không còn đủ?
Trong hệ thống Single-Agent, luồng xử lý thường tuyến tính nên có thể theo dõi chủ yếu bằng thời gian phản hồi và chi phí token. Khi chuyển sang Multi-Agent với các tương tác phi tuyến, một lỗi tại một tác nhân có thể lan truyền qua nhiều nút và làm sai lệch toàn bộ kết quả dù độ trễ vẫn thấp, vì vậy cần thêm các chỉ số gắn với cách các tác nhân phối hợp với nhau.
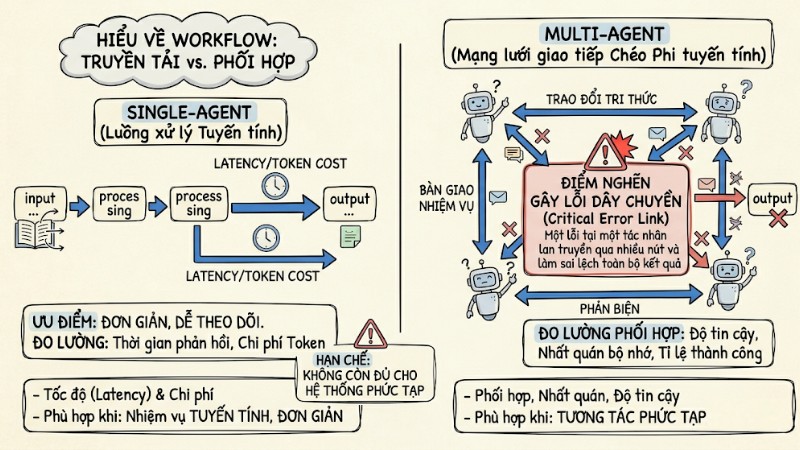
Workflow tuyến tính của Single-Agent và mạng lưới giao tiếp phi tuyến tính của Multi-Agent
Tầm quan trọng của Agent Coordination trong hệ thống
Chính vì hiệu suất không chỉ phụ thuộc vào từng tác nhân riêng lẻ mà còn vào cách chúng phối hợp, Agent Coordination trở thành yếu tố trung tâm trong mọi phép đo hiệu suất Multi-Agent. Hệ thống đa tác nhân thường bao gồm tác nhân điều phối và các tác nhân thực thi, và nếu tác nhân điều phối không kiểm soát chặt luồng hội thoại, hệ thống có nguy cơ xuất hiện phân kỳ ngữ nghĩa và Goal Drift khiến hành vi dần lệch khỏi mục tiêu ban đầu.
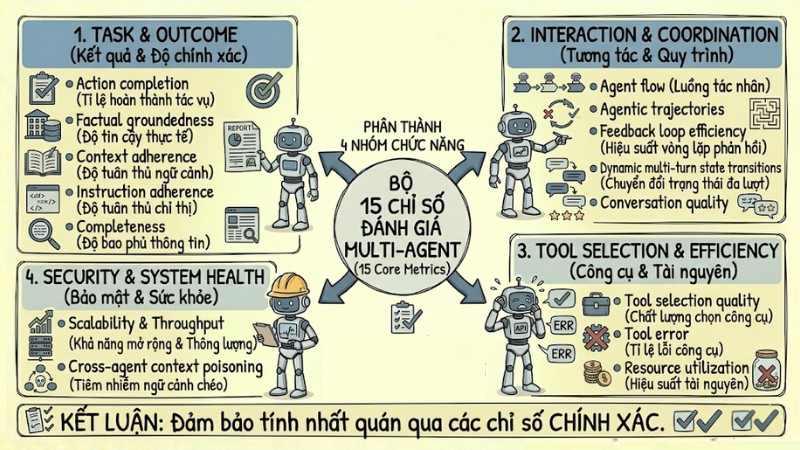
Bộ chỉ số cốt lõi đánh giá Multi-Agent
Để kiểm soát KPI trong hệ thống Autonomous Agent, có thể sử dụng 15 chỉ số chính được phân thành 4 nhóm chức năng. Mỗi nhóm tập trung vào một khía cạnh riêng gồm chất lượng kết quả, tương tác nội bộ, hiệu quả dùng công cụ và sức khỏe tổng thể của hệ thống.
| Nhóm Metrics | Chức năng chính |
|---|---|
| 1. Task & Outcome | Đo lường mức độ hoàn thiện và độ chính xác của kết quả. |
| 2. Interaction & Coordination | Đánh giá luồng giao tiếp và chất lượng phối hợp. |
| 3. Tool Selection & Efficiency | Kiểm tra hiệu quả khi gọi API và công cụ bên ngoài. |
| 4. Security & System Health | Giám sát độ ổn định, khả năng mở rộng và an toàn dữ liệu. |
Nhóm 1: Chỉ số về kết quả và độ chính xác (Task & Outcome Metrics)
Nhóm chỉ số này tập trung đo lường chất lượng đầu ra và mức độ phù hợp của câu trả lời so với yêu cầu và dữ liệu gốc.
- Action completion (Tỉ lệ hoàn thành tác vụ): Đo lường hệ thống có giải quyết trọn vẹn yêu cầu của người dùng hay dừng giữa chừng do lỗi logic.
- Factual groundedness (Độ tin cậy thực tế): Đánh giá câu trả lời của agent có dựa trên dữ liệu thực tế hay xuất hiện Hallucination.
- Context adherence (Độ tuân thủ ngữ cảnh): Đặc biệt quan trọng trong đánh giá RAG, đo lường tỷ lệ nội dung trả lời được rút ra đúng từ tài liệu đã cung cấp.
- Instruction adherence (Độ tuân thủ chỉ thị): Kiểm tra agent có thực hiện đúng yêu cầu trong System Prompt, ví dụ yêu cầu trả về JSON nhưng lại xuất hiện văn bản thuần.
- Completeness (Độ bao phủ thông tin): Đánh giá mức độ agent bỏ sót thông tin quan trọng trong kho dữ liệu khi tổng hợp câu trả lời.
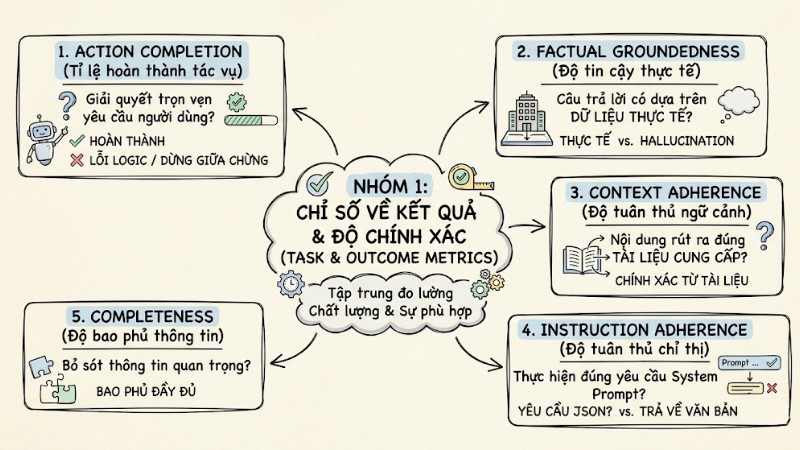
Nhóm chỉ số về kết quả và độ chính xác
Nhóm 2: Chỉ số về tương tác và quy trình (Interaction & Coordination Metrics)
Nhóm chỉ số này phản ánh cách các tác nhân phối hợp với nhau trong suốt hành trình giải quyết nhiệm vụ.
- Agent flow (Luồng tác nhân): Theo dõi tính hợp lý trong thứ tự kích hoạt và bàn giao giữa các tác nhân.
- Agentic trajectories (Quỹ đạo hành động): Đánh giá đường đi từ lúc nhận yêu cầu đến khi trả kết quả, quỹ đạo ngắn và hợp lý thể hiện chiến lược suy luận hiệu quả.
- Feedback loop efficiency (Hiệu suất vòng lặp phản hồi): Đo số lượt cần thiết để agent tự sửa lỗi và đưa ra kết quả đúng sau khi bị từ chối.
- Dynamic multi-turn state transitions (Chuyển đổi trạng thái đa lượt): Đo khả năng duy trì và cập nhật ngữ cảnh trong các hội thoại nhiều lượt có thay đổi ý định người dùng.
- Conversation quality (Chất lượng hội thoại): Chấm điểm mức độ mạch lạc, tự nhiên và mức độ hài lòng của người dùng trong toàn bộ phiên làm việc.
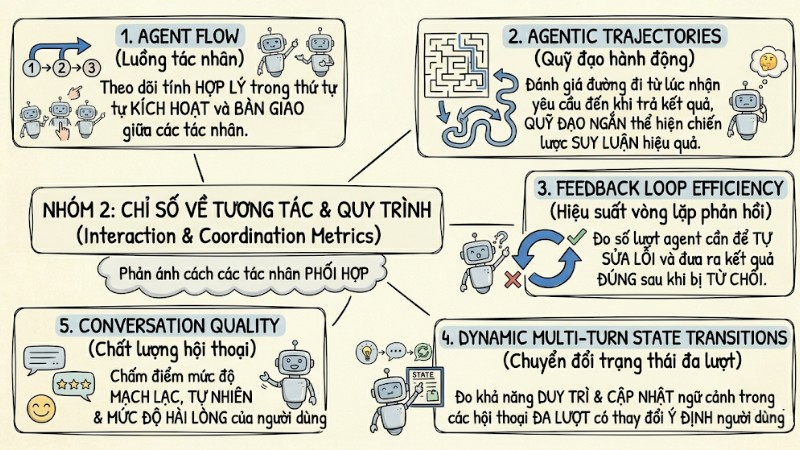
Nhóm chỉ số về tương tác và quy trình
Nhóm 3: Chỉ số về công cụ và tài nguyên (Tool Selection & Efficiency)
Nhóm chỉ số này cho biết hệ thống sử dụng API và tài nguyên tính toán hiệu quả đến mức nào.
- Tool selection quality (Chất lượng chọn công cụ): Đánh giá agent có chọn đúng API hoặc công cụ phù hợp với bài toán hay không.
- Tool error (Tỉ lệ lỗi công cụ): Theo dõi tần suất agent truyền tham số sai dẫn đến lỗi API ở mức 4xx hoặc 5xx.
- Resource utilization (Hiệu suất tài nguyên): Đo lượng RAM, GPU và token tiêu thụ trên mỗi hành động hoặc mỗi tác vụ hoàn thành.
Ví dụ thực tế: Một agent được giao nhiệm vụ lấy dữ liệu thời tiết nhưng liên tục truyền sai định dạng ngày tháng vào API, hệ thống trả lỗi và agent tự động gọi lại API hàng trăm lần mỗi phút, làm tiêu tốn tài nguyên và chi phí token không cần thiết. Việc thiết lập cảnh báo dựa trên chỉ số Tool error giúp phát hiện sớm vòng lặp bất thường và ngăn chặn hành vi gây lãng phí này.
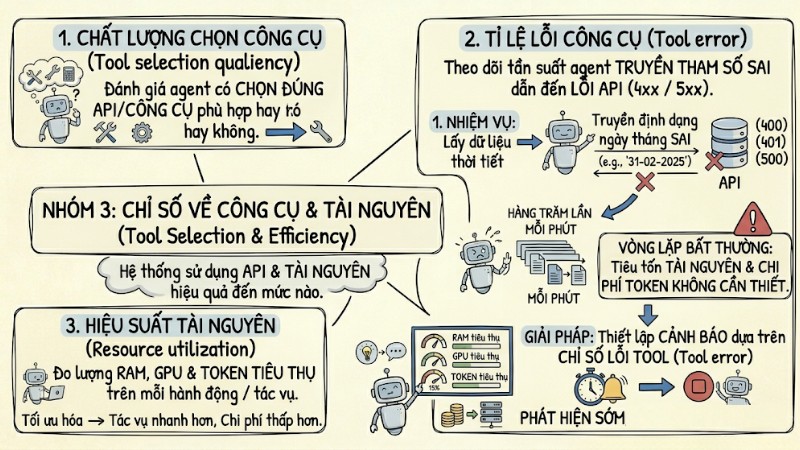
Nhóm chỉ số về công cụ và tài nguyên
Nhóm 4: Chỉ số về bảo mật và sức khỏe hệ thống (Security & System Health)
Nhóm chỉ số này tập trung vào tính ổn định dài hạn và an toàn của hệ thống multi-agent khi mở rộng.
- Scalability & Throughput (Khả năng mở rộng và thông lượng): Đo khả năng hệ thống duy trì tốc độ xử lý khi số lượng agent hoặc phiên làm việc đồng thời tăng lên.
- Cross-agent context poisoning (Tiêm nhiễm ngữ cảnh chéo): Đo rủi ro bảo mật của autonomous agent, đánh giá khả năng dữ liệu hoặc prompt độc hại từ một agent ảnh hưởng và thao túng quyết định của các agent khác trong cùng hệ thống.
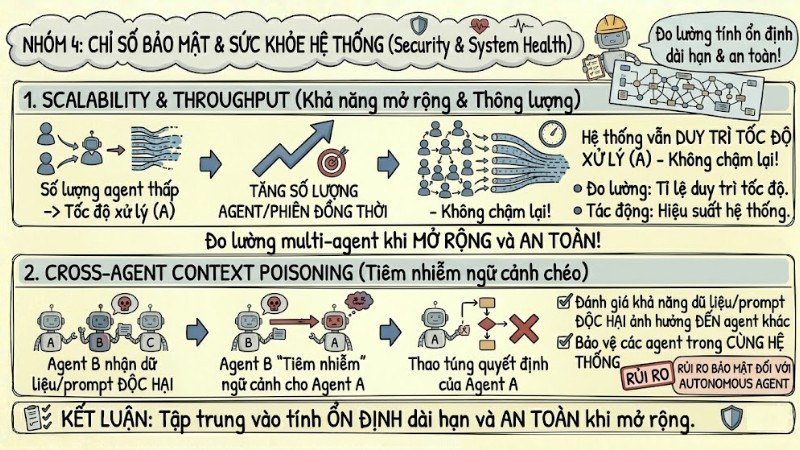
Nhóm chỉ số về bảo mật và sức khỏe hệ thống
Khung đánh giá Multi-Agent LLM
Để đo lường bộ 15 chỉ số ở trên một cách nhất quán, cần sử dụng các framework đánh giá chuyên dụng thay vì thực hiện thủ công. Dưới đây là 5 lựa chọn phổ biến, được xem xét theo chi phí, độ khó triển khai và mức độ phù hợp với từng loại dự án:
| Tiêu chí | Galileo AI | BFCL | τ-bench | Orq.ai | LangGraph + DeepEval |
|---|---|---|---|---|---|
| Chi phí | Cao (Enterprise) | Miễn phí | Miễn phí | Trung bình | Miễn phí |
| Độ khó triển khai | Thấp | Trung bình | Cao | Thấp | Cao |
| Tốt nhất cho | Doanh nghiệp lớn, CI/CD | Đánh giá Function calling | Mô phỏng tương tác thực tế | Quản lý vòng đời LLM, Guardrails | Lập trình viên muốn tùy biến 100% |
1. Galileo AI
Galileo AI là nền tảng quan sát và đánh giá chuyên sâu cho các hệ thống LLM và Agent trong môi trường sản xuất. Nền tảng này hỗ trợ thiết lập metric tùy chỉnh, theo dõi phiên tương tác end-to-end và tích hợp trực tiếp với quy trình CI/CD.
- Ưu điểm: Có sẵn leaderboard đánh giá nhiều LLM, tích hợp vào pipeline CI/CD, hỗ trợ thiết lập guardrails và chặn nội dung không phù hợp theo thời gian thực.
- Nhược điểm: Chi phí cao, thường chỉ phù hợp với tổ chức có ngân sách và yêu cầu tuân thủ nghiêm ngặt.
- Phù hợp với: Đội ngũ Enterprise cần giám sát chất lượng nghiêm ngặt và tối ưu chi phí Token.
2. Berkeley Function-Calling Leaderboard (BFCL)
BFCL là benchmark tập trung vào khả năng gọi hàm và sử dụng công cụ của các mô hình ngôn ngữ lớn, được sử dụng rộng rãi trong cộng đồng nghiên cứu và kỹ sư. Bộ dữ liệu bao gồm nhiều kịch bản thực tế để kiểm tra độ chính xác trong việc chọn hàm, tham số và phối hợp nhiều lệnh gọi.
- Ưu điểm: Cung cấp bộ dữ liệu kiểm thử đa dạng, đo tốt khả năng lên kế hoạch và thực thi mã thông qua function calling.
- Nhược điểm: Tập trung nhiều vào các tình huống đơn lẻ hoặc chuỗi ngắn, chưa bao quát đầy đủ các luồng phối hợp multi-agent phức tạp.
- Phù hợp với: Kỹ sư cần chọn base model có năng lực Tool-use và Function Calling tốt trước khi xây dựng hệ thống multi-agent.
3. τ-bench
τ-bench là benchmark mô phỏng hội thoại động giữa người dùng, agent và tập công cụ trong các miền nghiệp vụ như đặt vé, thương mại điện tử hoặc dịch vụ khách hàng. Khung này được thiết kế để đánh giá hành vi agent trong môi trường có quy tắc, API domain-specific và yêu cầu tuân thủ chính sách.
- Ưu điểm: Đo rất tốt chỉ số Action Completion, phát hiện lỗi khi mục tiêu hoặc yêu cầu người dùng thay đổi trong lúc hội thoại.
- Nhược điểm: Thiết lập phức tạp, thường yêu cầu hiểu biết sâu về mô hình quyết định tuần tự như POMDP.
- Phù hợp với: Các dự án xây dựng trợ lý ảo hoặc agent chăm sóc khách hàng cần mô phỏng kịch bản thực tế nhiều bước.
4. Orq.ai
Orq.ai là nền tảng điều phối và quan sát cho ứng dụng LLM đa tác nhân, cung cấp cả đánh giá tự động và hỗ trợ đánh giá thủ công từ con người. Nền tảng này tập trung vào quản lý vòng đời LLM, thiết lập guardrails và theo dõi toàn bộ hành trình tác vụ.
- Ưu điểm: Giao diện trực quan, có thư viện prompt và tập Evaluator phong phú, hỗ trợ nhiều mô hình khác nhau.
- Nhược điểm: Có thể dư tính năng và hơi nặng nếu chỉ cần một pipeline đánh giá đơn giản.
- Phù hợp với: Product Manager và đội ngũ vận hành muốn triển khai guardrails và monitoring mà không cần viết quá nhiều mã.
5. LangGraph kết hợp DeepEval
LangGraph cung cấp cách mô hình hóa luồng Multi-Agent dưới dạng đồ thị, trong khi DeepEval là thư viện mã nguồn mở để viết test và metric đánh giá bằng Python. Sự kết hợp này phù hợp với đội ngũ kỹ thuật muốn kiểm soát chi tiết từng bước đánh giá trong code.
- Ưu điểm: Miễn phí, khả năng tùy biến cao, DeepEval hỗ trợ nhiều metric cho RAG và agent evaluation tích hợp vào test suite.
- Nhược điểm: Đòi hỏi kỹ năng lập trình Python tốt và cần tự xây dựng cơ chế logging, lưu trữ và dashboard.
- Phù hợp với: Kỹ sư phần mềm muốn làm chủ toàn bộ mã nguồn, kiến trúc đánh giá và tích hợp chặt chẽ với CI/CD nội bộ.
# Ví dụ khai báo một metric kiểm tra tính thực tế bằng DeepEval
from deepeval.metrics import FactualConsistencyMetric
from deepeval.test_case import LLMTestCase
metric = FactualConsistencyMetric(threshold=0.7)
test_case = LLMTestCase(
input="Tác nhân A đã làm gì?",
actual_output="Tác nhân A đã gọi API thời tiết.",
context=["Log hệ thống: Tác nhân A truy xuất API thời tiết lúc 10:00"]
)
metric.measure(test_case)
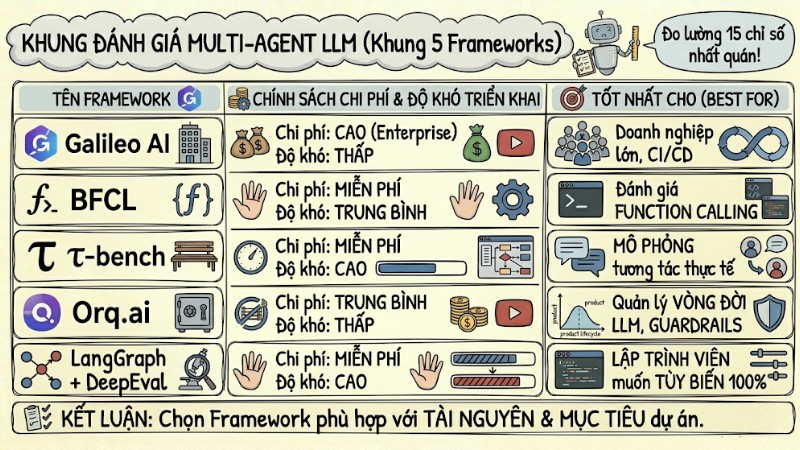
Khung đánh giá Multi-Agent LLM
Thách thức khi xây dựng benchmark cho AI Agentic Engineering
Khi thiết kế benchmark cho hệ thống AI đa tác nhân, cần xử lý đồng thời vấn đề quan sát, hành vi phát sinh và chi phí đánh giá. Ba nhóm thách thức dưới đây thường xuất hiện trong các dự án triển khai thực tế.
AI Observability Platforms và giám sát thời gian thực
Khi hệ thống có nhiều agent giao tiếp liên tục, lượng log và trace sinh ra rất lớn và phân tán theo nhiều bước suy luận khác nhau. Việc kết nối các dấu vết này thành chuỗi truy vết đầu cuối thống nhất mà vẫn giữ độ trễ vận hành ở mức chấp nhận được là một trong những thách thức chính của các nền tảng AI observability.
Đánh giá các động lực phát sinh (Emergent Dynamics)
Hành vi phát sinh xuất hiện khi các agent kết hợp với nhau tạo ra chiến lược giải quyết vấn đề mà thiết kế ban đầu không mô tả chi tiết. Một phần trong số đó cải thiện chất lượng kết quả, nhưng cũng có nhiều trường hợp dẫn tới lỗi khó dự đoán, nên cần bổ sung các lớp kiểm soát quyết định hoặc lớp override mang tính quyết định để giới hạn phạm vi hành động của agent trong những vùng an toàn đã được xác định trước.
Tối ưu hóa chi phí đánh giá với LLM-as-a-Judge
Việc sử dụng đánh giá thủ công theo mô hình Human-in-the-loop cho mọi tương tác trong hệ thống multi-agent thường tốn kém và khó mở rộng. Cách tiếp cận phổ biến là triển khai một mô hình nhỏ đóng vai trò giám khảo tự động (LLM-as-a-Judge) để chấm điểm hành vi của các agent khác, đồng thời thiết kế quy trình kiểm tra định kỳ nhằm đảm bảo độ ổn định và nhất quán của kết quả đánh giá từ mô hình này.
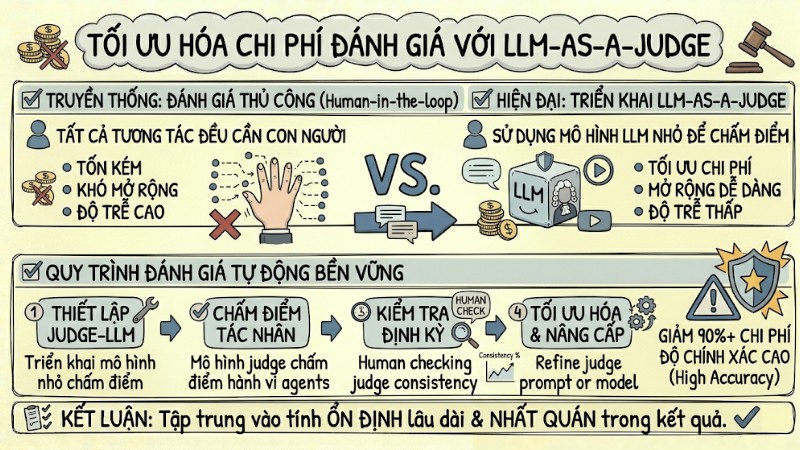
Tối ưu hóa chi phí đánh giá với LLM-as-a-Judge
Giải đáp thắc mắc thường gặp về Multi-Agent Metrics
Đâu là metric quan trọng nhất khi mới bắt đầu xây dựng Multi-Agent?
Khi mới bắt đầu, nên ưu tiên theo dõi Action Completion để biết hệ thống có hoàn thành đúng nhiệm vụ hay không và Tool Error để phát hiện sớm lỗi khi gọi API hoặc công cụ. Nếu hai chỉ số này chưa đạt mức chấp nhận được thì các metric nâng cao về hội thoại hoặc trải nghiệm người dùng chưa cần đầu tư nhiều.
Làm sao để tránh việc các Agent "bịa" ra thông tin khi nói chuyện với nhau?
Có thể áp dụng Context Adherence tại từng điểm giao tiếp bằng cách dùng một mô hình nhỏ kiểm tra xem phản hồi của agent có bám đúng dữ liệu đầu vào từ agent trước đó hay không. Ngoài ra, nên giới hạn phép suy luận tự do và yêu cầu agent luôn trích dẫn nguồn hoặc bằng chứng trong các bước trao đổi nội bộ.
Các hệ thống đánh giá hiện tại có thể tự động sửa lỗi cho Agent không?
Phần lớn framework đánh giá hiện nay chủ yếu thực hiện giám sát, phát hiện lỗi và chặn hành vi rủi ro thông qua guardrails. Để sửa lỗi tự động, vẫn cần thiết kế Feedback Loop rõ ràng và duy trì Human-in-the-loop để xem xét các trường hợp khó hoặc hiệu chỉnh prompt và rule cho phù hợp.
Interoperability giữa các framework đánh giá như thế nào?
Hiện tại khả năng tương tác giữa các nền tảng đánh giá còn hạn chế vì mỗi công cụ sử dụng định dạng log, schema sự kiện và API riêng. Khi muốn chuyển dữ liệu đánh giá từ nền tảng này sang nền tảng khác, thường phải xây dựng lớp chuyển đổi hoặc pipeline tích hợp tùy chỉnh.
Xem thêm:
- AI Agent hoạt động như thế nào: Cơ chế tự chủ và vận hành
- 7 Coding Agent Use Cases thực tế giúp tối ưu quy trình
- Agent Swarm là gì? Cách Agent Swarm tự động hóa quy trình
Ứng dụng Multi-Agent Metrics kết hợp với các framework đánh giá chuyên dụng giúp phát hiện sớm lỗi dây chuyền, giám sát hành vi phát sinh và duy trì chất lượng suy luận của hệ thống trong môi trường sản xuất. Khi thiết lập được bộ KPI rõ ràng và lựa chọn đúng công cụ quan sát, đội ngũ sản phẩm có thể mở rộng kiến trúc Multi-Agent một cách an toàn hơn, đồng thời tối ưu chi phí vận hành và độ tin cậy của toàn bộ hệ thống.
Thẻ