15 Important Multi-Agent Metrics for Evaluating AI Agent Systems

Multi-Agent architectures allow multiple AI agents to collaborate to solve complex problems, but they also increase the risk of cascading failures without Multi-Agent Metrics mechanisms to measure and control them. This article introduces a set of 15 Multi-Agent Metrics to evaluate performance and 5 practical evaluation frameworks that help engineers and technical managers systematically monitor, optimize, and control Multi-Agent systems.
Key Takeaways
- Multi-Agent Measurement Concept: Understand why single metrics like response time or token cost are no longer sufficient to measure a complex multi-agent system, where a small error can create a chain effect.
- 15 Important Multi-Agent Metrics: Master a set of metrics divided into 4 essential groups: Outcome quality, interaction flow, tool usage efficiency, and system security, helping you comprehensively monitor AI health.
- Evaluation Tools: Explore the pros and cons of 5 popular platforms to make the right decision for your problem.
- Practical Challenges: Identify 3 major barriers when implementing evaluation: Handling massive log volumes, controlling unpredictable emergent behaviors, and optimizing scoring costs using the LLM-as-a-Judge model.
- FAQ: Get answers to questions about the most important metrics when starting out, how to prevent Agents from fabricating information when communicating with each other, and the self-correction capabilities of current evaluation systems.
Measuring Multi-Agent System Performance
The Concept of Multi-Agent Performance Measurement
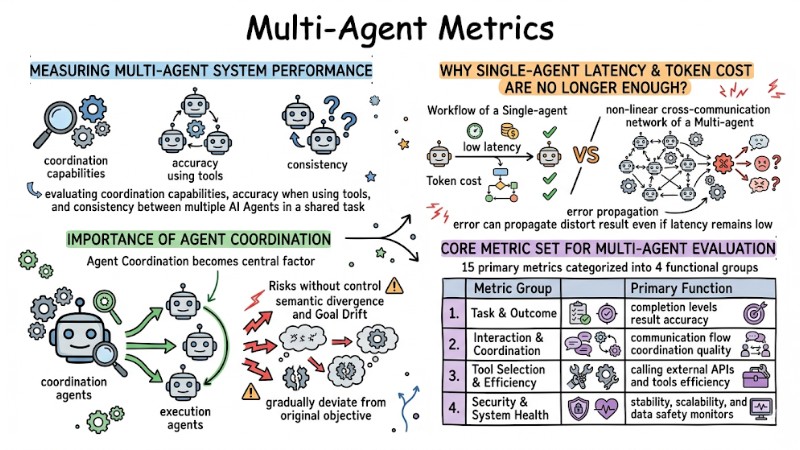
Multi-Agent performance measurement is the process of evaluating coordination capabilities, accuracy when using tools, and consistency between multiple AI Agents in a shared task. This section focuses on explaining why Single-Agent metrics are no longer enough, while clarifying the role of Agent Coordination in Multi-Agent LLM architectures.
Why Single-Agent Latency and Token Cost Are No Longer Enough?
In a Single-Agent system, the processing flow is typically linear, so it can be monitored primarily by response time and token cost. When moving to Multi-Agent with non-linear interactions, an error in one agent can propagate through many nodes and distort the entire result even if latency remains low; therefore, additional metrics tied to how agents coordinate with each other are required.
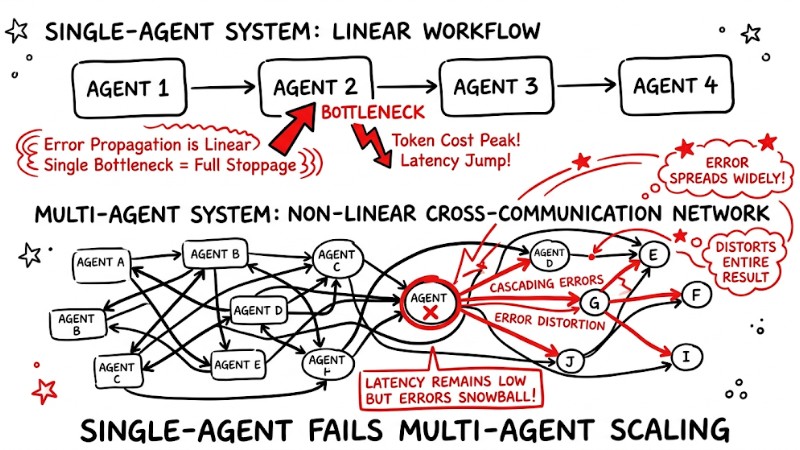
Workflow of a Single-agent and the non-linear cross-communication network of a Multi-agent
The Importance of Agent Coordination in the System
Because performance depends not only on individual agents but also on how they coordinate, Agent Coordination becomes the central factor in all Multi-Agent performance measurements. Multi-agent systems often include coordination agents and execution agents; if the coordination agent does not strictly control the conversation flow, the system risks semantic divergence and Goal Drift, causing behavior to gradually deviate from the original objective.
Core Metric Set for Multi-Agent Evaluation
To control KPIs in an Autonomous Agent system, 15 primary metrics can be used, categorized into 4 functional groups. Each group focuses on a specific aspect including outcome quality, internal interaction, tool usage efficiency, and overall system health.
| Metric Group | Primary Function |
|---|---|
| 1. Task & Outcome | Measures completion levels and result accuracy. |
| 2. Interaction & Coordination | Evaluates communication flow and coordination quality. |
| 3. Tool Selection & Efficiency | Checks efficiency when calling external APIs and tools. |
| 4. Security & System Health | Monitors stability, scalability, and data safety. |
Group 1: Result and Accuracy Metrics (Task & Outcome Metrics)
This group of metrics focuses on measuring output quality and the relevance of the answer compared to the request and source data.
- Action completion: Measures whether the system completely resolves the user's request or stops midway due to logic errors.
- Factual groundedness: Evaluates whether the agent's answer is based on factual data or if Hallucination occurs.
- Context adherence: Especially important in RAG evaluation, measuring the ratio of response content correctly drawn from the provided documents.
- Instruction adherence: Checks if the agent correctly follows requirements in the System Prompt, e.g., requesting JSON return but receiving plain text instead.
- Completeness: Evaluates the extent to which the agent misses important information in the data repository when synthesizing the answer.
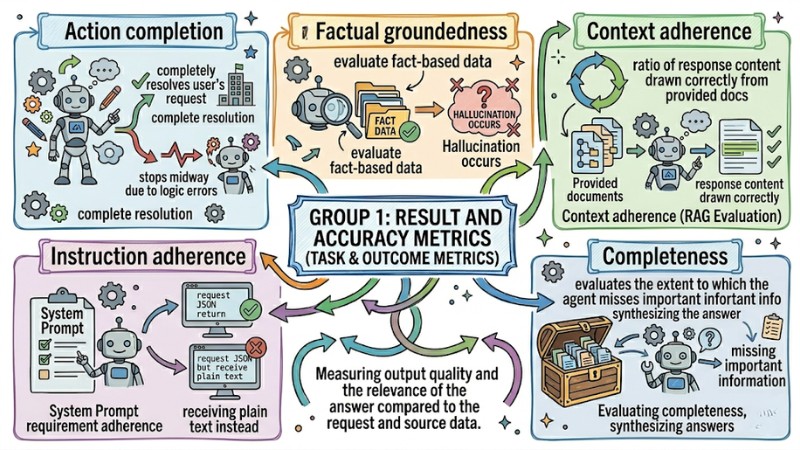
Result and Accuracy Metrics
Group 2: Interaction and Process Metrics (Interaction & Coordination Metrics)
This group of metrics reflects how agents coordinate with each other throughout the task-solving journey.
- Agent flow: Tracks the logic in the activation and handoff sequence between agents.
- Agentic trajectories: Evaluates the path from receiving the request to returning the result; short and logical trajectories demonstrate effective reasoning strategies.
- Feedback loop efficiency: Measures the number of turns required for an agent to self-correct and provide a correct result after being rejected.
- Dynamic multi-turn state transitions: Measures the ability to maintain and update context in multi-turn conversations with changing user intent.
- Conversation quality: Scores the level of coherence, naturalness, and user satisfaction throughout the entire session.
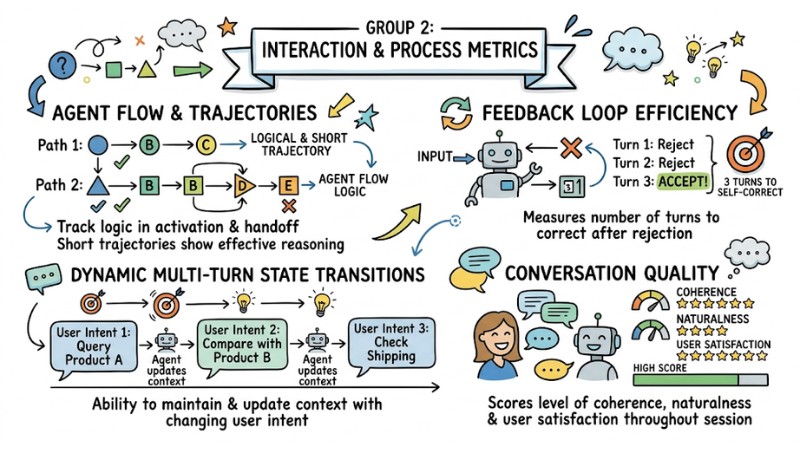
Interaction and Process Metrics
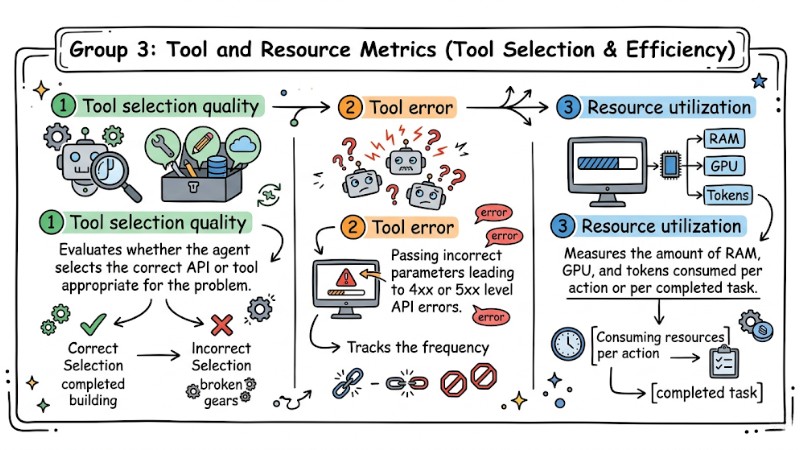
Group 3: Tool and Resource Metrics (Tool Selection & Efficiency)
This group of metrics indicates how efficiently the system uses APIs and computing resources.
- Tool selection quality: Evaluates whether the agent selects the correct API or tool appropriate for the problem.
- Tool error: Tracks the frequency of agents passing incorrect parameters leading to 4xx or 5xx level API errors.
- Resource utilization: Measures the amount of RAM, GPU, and tokens consumed per action or per completed task.
Real-world Example: An agent is assigned the task of fetching weather data but repeatedly passes incorrect date formats to the API; the system returns an error and the agent automatically recalls the API hundreds of times per minute, wasting resources and unnecessary token costs. Setting alerts based on the Tool error metric helps detect abnormal loops early and prevents this wasteful behavior.
Tool and Resource Metrics
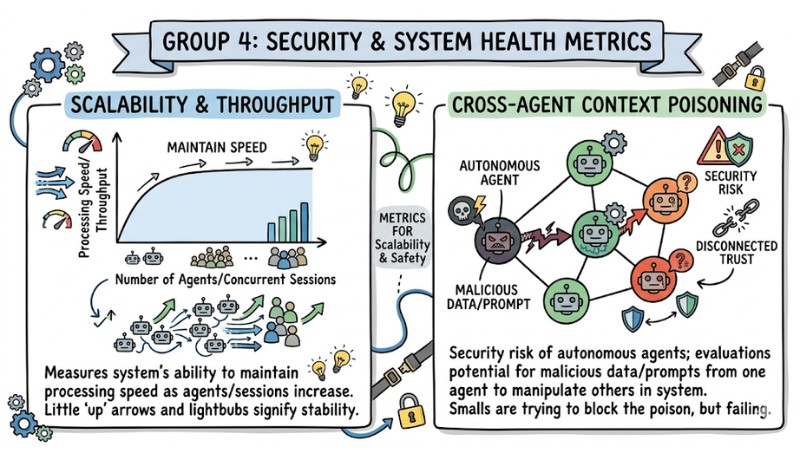
Group 4: Security and System Health Metrics (Security & System Health)
This group of metrics focuses on the long-term stability and safety of the multi-agent system as it scales.
- Scalability & Throughput: Measures the system's ability to maintain processing speed as the number of agents or concurrent sessions increases.
- Cross-agent context poisoning: Measures the security risk of autonomous agents, evaluating the possibility that malicious data or prompts from one agent affect and manipulate the decisions of other agents within the same system.
Security and System Health Metrics
Multi-Agent LLM Evaluation Frameworks
To measure the 15 metrics above consistently, specialized evaluation frameworks should be used instead of manual methods. Below are 5 popular choices, considered by cost, implementation difficulty, and suitability for each project type:
| Framework Name | Cost | Implementation Difficulty | Best For |
|---|---|---|---|
| Galileo AI | High (Enterprise) | Low | Large enterprises, CI/CD |
| BFCL | Free | Medium | Function calling evaluation |
| τ-bench | Free | High | Real-world interaction simulation |
| Orq.ai | Medium | Low | LLM lifecycle management, Guardrails |
| LangGraph + DeepEval | Free | High | Developers wanting 100% customization |
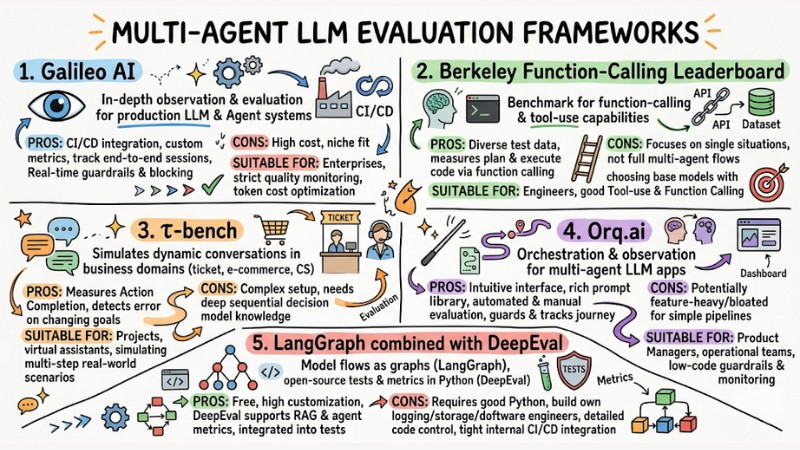
1. Galileo AI
Galileo AI is an in-depth observation and evaluation platform for LLM and Agent systems in production environments. This platform supports setting custom metrics, tracking end-to-end interaction sessions, and integrating directly with CI/CD workflows.
- Pros: Available leaderboard evaluating multiple LLMs, integrates into CI/CD pipelines, supports setting guardrails and blocking inappropriate content in real-time.
- Cons: High cost, usually only suitable for organizations with strict budgets and compliance requirements.
- Suitable for: Enterprise teams needing strict quality monitoring and token cost optimization.
2. Berkeley Function-Calling Leaderboard (BFCL)
BFCL is a benchmark focused on the function-calling and tool-use capabilities of large language models, widely used in the research and engineering community. The dataset includes many real-world scenarios to test accuracy in selecting functions, parameters, and coordinating multiple calls.
- Pros: Provides a diverse set of test data, measures well the ability to plan and execute code via function calling.
- Cons: Focuses heavily on single situations or short chains, not yet fully covering complex multi-agent coordination flows.
- Suitable for: Engineers needing to choose base models with good Tool-use and Function Calling capabilities before building a multi-agent system.
3. τ-bench
τ-bench is a benchmark that simulates dynamic conversations between users, agents, and toolsets in business domains such as ticket booking, e-commerce, or customer service. This framework is designed to evaluate agent behavior in environments with rules, domain-specific APIs, and policy compliance requirements.
- Pros: Measures the Action Completion metric very well, detects errors when user goals or requests change during conversation.
- Cons: Complex setup, usually requiring deep understanding of sequential decision models like POMDP.
- Suitable for: Projects building virtual assistants or customer care agents needing to simulate multi-step real-world scenarios.
4. Orq.ai
Orq.ai is an orchestration and observation platform for multi-agent LLM applications, providing both automated evaluation and support for manual evaluation from humans. The platform focuses on LLM lifecycle management, setting guardrails, and tracking the entire task journey.
- Pros: Intuitive interface, rich prompt library and Evaluator set, supports many different models.
- Cons: May be feature-heavy and slightly bloated if only a simple evaluation pipeline is needed.
- Suitable for: Product Managers and operation teams wanting to deploy guardrails and monitoring without writing too much code.
5. LangGraph combined with DeepEval
LangGraph provides a way to model Multi-Agent flows as graphs, while DeepEval is an open-source library for writing tests and evaluation metrics in Python. This combination is suitable for technical teams wanting detailed control over every evaluation step in code.
- Pros: Free, high customization, DeepEval supports many metrics for RAG and agent evaluation integrated into test suites.
- Cons: Requires good Python programming skills and requires building your own logging, storage, and dashboard mechanisms.
- Suitable for: Software engineers wanting to own the entire source code, evaluation architecture, and integrate tightly with internal CI/CD.
Multi-Agent LLM Evaluation Frameworks
Challenges in Building Benchmarks for AI Agentic Engineering
When designing benchmarks for multi-agent AI systems, observation issues, emergent behavior, and evaluation costs must be handled simultaneously. These three groups of challenges often appear in actual deployment projects.
AI Observability Platforms and Real-time Monitoring
When a system has multiple agents communicating continuously, the volume of logs and traces generated is massive and distributed across many different reasoning steps. Connecting these traces into a unified end-to-end trace chain while maintaining operational latency at an acceptable level is one of the main challenges for AI observability platforms.
Evaluating Emergent Dynamics
Emergent behavior appears when agents combine to create problem-solving strategies that the original design did not describe in detail. Some of these improve result quality, but many cases lead to unpredictable errors; therefore, additional decision control layers or deterministic override layers are needed to limit agent action scopes within predefined safe zones.
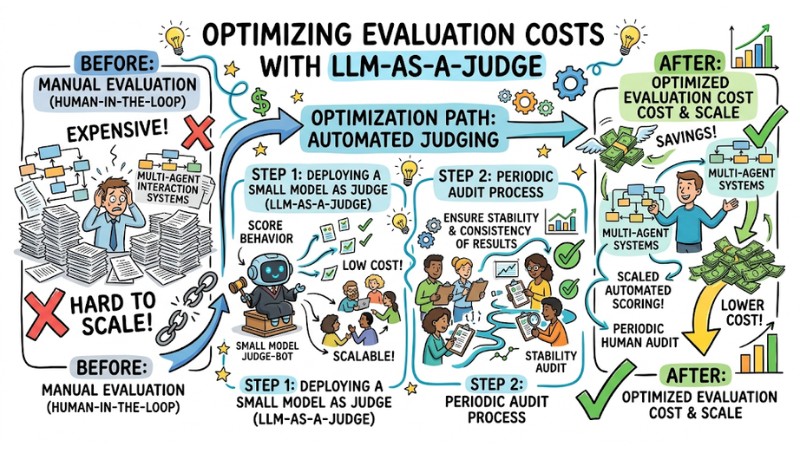
Optimizing Evaluation Costs with LLM-as-a-Judge
Using manual evaluation according to the Human-in-the-loop model for every interaction in a multi-agent system is often expensive and hard to scale. A common approach is to deploy a small model acting as an automated judge (LLM-as-a-Judge) to score the behavior of other agents, while designing periodic audit processes to ensure the stability and consistency of evaluation results from this model.
Optimize assessment costs with LLM-as-a-Judge
Answering Common Questions about Multi-Agent Metrics
What is the most important metric when starting to build Multi-Agent?
When starting out, priority should be given to tracking Action Completion to know if the system correctly completes tasks and Tool Error to detect errors early when calling APIs or tools. If these two metrics have not reached acceptable levels, advanced metrics on conversation or user experience do not yet need much investment.
How to avoid Agents "fabricating" information when talking to each other?
Context Adherence can be applied at each communication point by using a small model to check if the agent's response strictly adheres to the input data from the previous agent. Additionally, free reasoning should be limited and agents should be required to always cite sources or evidence in internal exchange steps.
Can current evaluation systems automatically fix errors for Agents?
Most current evaluation frameworks primarily perform monitoring, error detection, and block risky behavior through guardrails. To fix errors automatically, a clear Feedback Loop still needs to be designed and Human-in-the-loop maintained to review difficult cases or calibrate prompts and rules appropriately.
How is the Interoperability between evaluation frameworks?
Currently, interoperability between evaluation platforms is limited because each tool uses its own log formats, event schemas, and APIs. When wanting to transfer evaluation data from one platform to another, a conversion layer or custom integration pipeline usually has to be built.
Read more:
- How AI Agents work: Autonomy and Functional Mechanisms
- 7 Practical Coding Agent Use Cases to Optimize Your Workflow
- What is Agent Swarm? How Agent Swarm Automates Workflows
Applying Multi-Agent Metrics combined with specialized evaluation frameworks helps detect cascading failures early, monitor emergent behavior, and maintain the reasoning quality of the system in production environments. Once a clear set of KPIs is established and the right observation tools are selected, product teams can scale Multi-Agent architectures more safely, while optimizing operational costs and the reliability of the entire system.