Prompt Caching: How to Effectively Optimize LLM API Latency and Costs

Escalating API Input Token bills and high latency, especially with Time-to-First-Token (TTFT), are always two major pain points when scaling AI Agent or RAG systems. To solve this problem thoroughly, Prompt Caching was born and has become a mandatory standard in modern GenAI architecture. In this article, I will dive deep into the internal operating mechanism of LLM caching, while providing practical prompt structure templates for you to apply directly into your source code.
Key Points
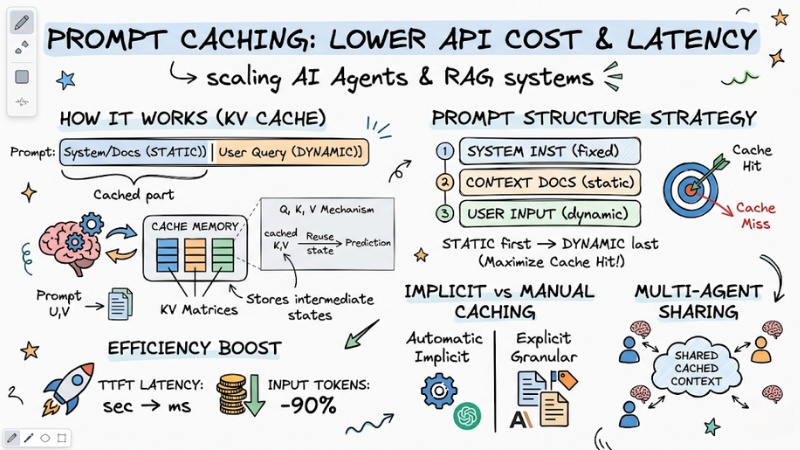
- The nature of Prompt Caching: Understand how LLMs store intermediate computation states (KV Cache) to reuse static context, helping to cut costs and inference time.
- KV Matrices mechanism: Master the operating principle of Key-Value matrices in Transformer architecture—the key to eliminating TTFT latency.
- Prompt structure strategy: Apply the "Static first - Dynamic last" rule to optimize the Cache Hit rate, ensuring stable system performance.
- OpenAI vs. Anthropic comparison: Distinguish between implicit (Implicit) and manual (Granular) caching methods to integrate APIs accurately.
- Economic efficiency: Quantify the potential to save up to 90% of Input Token costs and reduce TTFT latency from seconds to milliseconds.
- Multi-Agent Application: How to share caches between Agents to optimize the analysis of large shared documents.
- FAQ resolution: Clarify the factors causing Cache Misses (such as changing Temperature parameters) and the roadmap for implementing caching for enterprise RAG systems.
Understanding Prompt Caching
What is Prompt Caching?
Prompt Caching is a technique that stores static parts of a prompt (such as system instructions, reference documents) in the memory of an LLM model. Thanks to this, in subsequent calls, the model does not need to recompute the entire context from scratch but reuses intermediate results, significantly reducing input token costs and response latency.
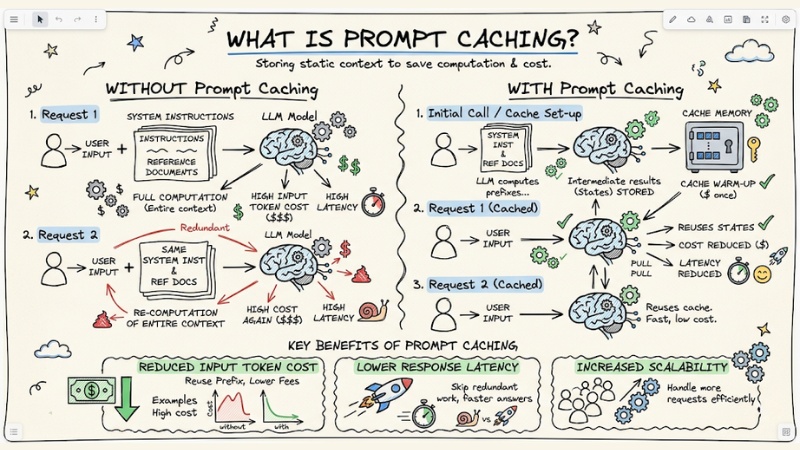
Prompt Caching is a technique that stores static parts of a prompt in the LLM's memory.
Prompt Caching is not regular caching
When mentioning caching, developers often immediately think of Exact-match caching techniques using Redis or Memcached. With this traditional architecture, the system stores the entire input string as the Key and the output text string as the Value. If the user sends a slightly different question, even if just by a comma, the system will report a Cache Miss and recompute everything from scratch.
However, the way the LLM inference process is optimized works completely differently. Large language models do not store pure text strings. When you send a prompt, data passes through a Tokenizer to convert it into arithmetic IDs, which are then mapped into multidimensional vectors in Embedding space. Here, the model begins performing complex matrix operations to understand context. What is actually stored is the intermediate computation state of these neural networks.
Additionally, changing configuration parameters like Temperature, Top-P, or Max Tokens in the API payload will immediately change the signature of the request. The provider's gateway system will evaluate this as a new processing flow and completely invalidate the previous cache.
Understanding KV Matrices
KV Cache (Key-Value Caching) in LLMs is a mechanism that stores Key (K) and Value (V) matrices computed from previous tokens in the Transformer architecture, helping to speed up inference. Instead of reprocessing the entire context from the beginning, the model only needs to calculate the Query (Q) vector for the latest token and compare it with the KV buffer to predict the next word.
To visualize it, view the Attention mechanism as a detective reading a 1000-page mystery novel.
- Instead of reading from page 1 to page 1000 every time they reach page 1001 to recall relevant details (recomputing from scratch),
- This detective creates "character linkage notes" (these are the KV Matrices).
- When reading a new word on page 1001 (Query), the detective just needs to pull out the notebook (Key-Value) to compare if this word has a close connection with any previous characters.
By reusing KV Matrices, LLMs bypass billions of redundant matrix multiplications. The longer the input context provided, the more significant the efficiency Prompt Caching brings.
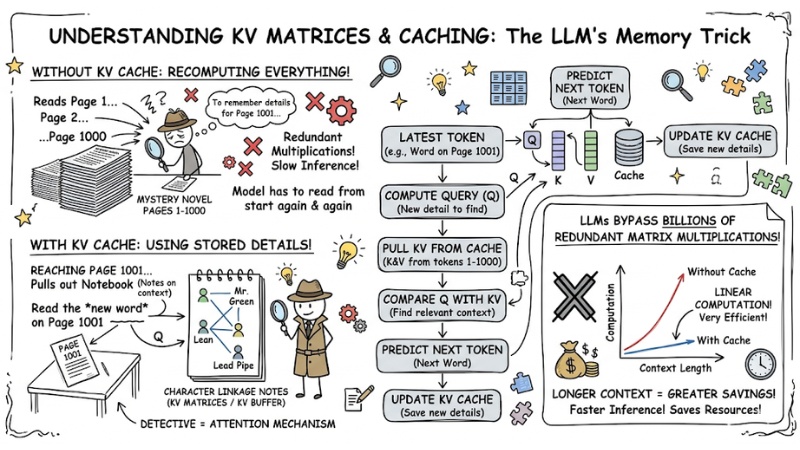
KV Cache (Key-Value Caching) in LLM
The art of prompt structuring to optimize Cache Hit
Static first - Dynamic last principle
To handle context consistently with the caching mechanism, you must manage the LLM Context Window in the correct linear order. The cache is built from the first token to the last token in a single direction. Any change at the beginning of the input sequence will destroy all cache nodes behind it.
Here are 4 golden rules for shaping an optimal prompt structure:
- System Instructions: Place fixed system instructions, role-play, and rules at the very top.
- Static RAG Context: Insert background documents, PDFs, and enterprise processes that rarely change in the second position.
- Sample Examples: Provide sample examples (Input/Output) with fixed formatting next.
- Dynamic Queries: Constantly changing variables like
User Input,Session ID, ordatetime.now()MUST be placed in the final position.
The most common mistake many users make is concatenating real-time data into the System Prompt. Example: You are an AI. Today is {datetime.now()}. Because the time variable changes every second, the system must continuously recompute KV Matrices from scratch, rendering the cache meaningless.
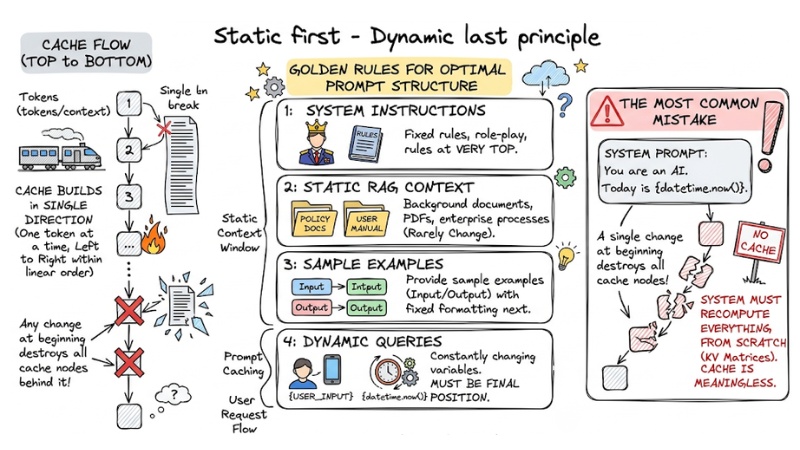
Static first - Dynamic last principle
Comparing Prompt Caching mechanisms: Automatic OpenAI vs. Manual Anthropic
Currently, the two giants are approaching caching with two opposing philosophies, requiring different code adjustments:
- OpenAI (GPT-4o): Operates entirely implicitly. The API automatically identifies long prompt segments (usually over 1024 tokens) and caches them if the subsequent request matches the beginning part. The advantage is easy integration, with no code changes required. The disadvantage is a lack of control; sometimes caches are evicted early due to high server load without the dev knowing.
- Anthropic (Claude 3.5): Requires manual configuration for Granular cache control. You must proactively attach a
cache_control: {"type": "ephemeral"}flag to the JSON message array at the desired breakpoint. The advantage is thorough cost optimization, ensuring a 100% Cache Hit rate. The disadvantage is that it requires developers to carefully count and track tokens.
Below is an example of message array structure in Python:
# [BAD PRACTICE] - Causes continuous Cache Miss due to time variable at the top
bad_messages = [
{"role": "system", "content": f"Today is {datetime.now()}. You are a support bot."},
{"role": "user", "content": "Company policy document: [10,000 words...]"},
{"role": "user", "content": "Can I take a day off tomorrow?"}
]
# [GOOD PRACTICE] - Ensures 100% Cache Hit for System and Document parts
good_messages = [
{"role": "system", "content": "You are a support bot."}, # Static
{"role": "user", "content": "Company policy document: [10,000 words...]"}, # Static (Attach cache breakpoint here if using Anthropic)
{"role": "user", "content": f"Today is {datetime.now()}. Can I take a day off tomorrow?"} # Dynamic - Placed last
]
Practical problem: Impact on cost and latency
Why are API providers willing to offer deep discounts when a cache hit occurs? The answer lies in GPU resources. Reusing the cache allows skipping the most computationally expensive inference stage. You save compute for them, and they lower the price for you.
Important note: This discount policy only applies to Input tokens. The cost generated by Output tokens remains unchanged because the model must still create new responses automatically.
| Evaluation Criteria | Without Prompt Caching (Cache Miss) | Applying Prompt Caching (Cache Hit) |
|---|---|---|
| Inference cost per 1 million Input Tokens | $5.00 (Standard price). | $0.50 (90% cost reduction). |
| Startup latency - Time-to-First-Token (TTFT) | ~2,500ms (For 50k tokens prompt). | ~150ms - 200ms (Response is nearly instant). |
| Tokens processed (New computation) | 100% of input sequence length. | Only calculated from the final User Query. |
Given the above data, applying caching is no longer an optional feature but has become a core standard for any enterprise-grade RAG system.
Prompt Caching in Multi-Agent architecture
When building distributed AI Multi-Agent systems, the issue goes beyond a single API request. Suppose you have a team of 5 agents that need to coordinate to analyze a 100-page financial report PDF. If the architecture design is poor, each agent will automatically send a copy of that PDF to the LLM.
The solution using Prompt Caching in Multi-Agent architecture is to use LLM caching to "share context" among multiple agents so everyone can leverage the static context (documents, policies, system instructions) instead of each agent sending and recomputing the context from scratch.
Thanks to this, a team of agents can read the same set of documents while maintaining a high Cache Hit rate, drastically reducing input token costs and latency, especially when the system must process large files like financial reports, system logs, or internal knowledge bases.
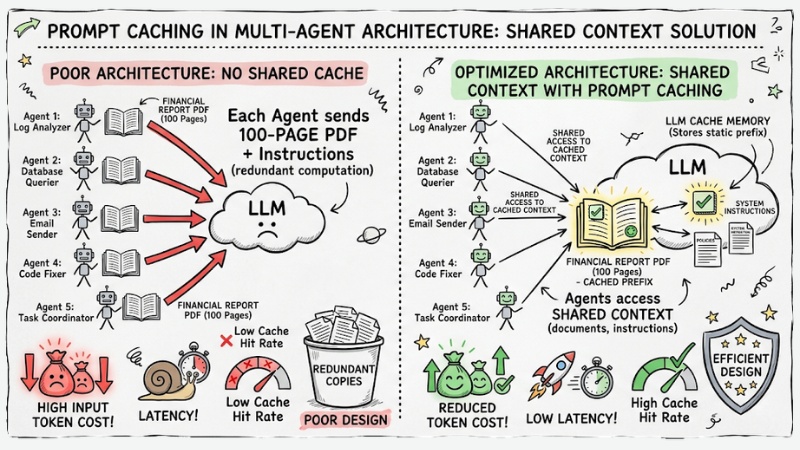
Prompt Caching in Multi-Agent architecture
Frequently asked questions about Prompt Caching
What is Prompt Caching?
In AI, Prompt Caching is a technique that stores static parts of a prompt (such as system instructions, reference documents) in the AI model's memory. Instead of processing from scratch, the system reuses intermediate computation results, helping to significantly reduce costs and latency.
What is the difference between Prompt Caching and regular Caching?
Prompt Caching stores Key-Value matrices (KV Cache) inside the Transformer architecture to avoid recomputing the attention mechanism. Meanwhile, traditional caching (e.g., Redis) stores output data as static text for fast retrieval.
How to achieve maximum "Cache Hit"?
For optimal efficiency, you need to apply the "Static first - Dynamic last" structure:
- Place System Instructions at the very top.
- Follow with fixed reference documents.
- Place dynamic queries (User Query) at the very end.
Why does changing parameters (Temperature) break the cache?
Prompt Caching requires absolute consistency in input and configuration. Because parameters like Temperature or Top-P directly affect the inference process, any small change will cause the system to fail to match the existing cache, leading to a Cache Miss.
Does Prompt Caching reduce API costs?
Prompt Caching significantly reduces costs for cached input token segments. However, you should note that this mechanism only applies to Input Tokens; the Output Tokens generated by the model remain at the same unit price depending on each LLM service provider.
See more:
- What is Generative AI? Practical applications of Generative AI
- What is Low-code? Understanding technical architecture and underlying risks
- What is Orchestration Layer? Understanding its importance in systems
Prompt Caching is an architectural breakthrough, helping to leverage KV Matrices to minimize inference costs and eliminate TTFT latency. The key to mastering this technology lies in absolute adherence to the "Static first - Dynamic last" principle during the construction of the input message array. Because of this, Prompt Caching is not just a performance optimization technique, but has become a mandatory foundation for every serious GenAI and RAG system looking to scale with reasonable costs.