AI Agent Best Practices: A Guide to Building Autonomous Systems

Building an AI Agent requires a mindset shift from static process programming to designing systems capable of reasoning and self-adaptation. To successfully deploy AI Agents in an enterprise environment, you need to ensure a combination of Large Language Model (LLM) flexibility and the rigorous control of traditional software engineering.
Key Takeaways
- Systems Design Thinking: Transition from static process programming to self-adaptive reasoning models, combining LLM flexibility with rigorous software engineering control.
- Core Architecture: Master the roles of the Brain (LLM), Tools (execution skills), and Memory (context), alongside the Plan-Act-Reflect loop for logical Agent operation.
- Tool Optimization: Use Schemas (JSON/Pydantic) to strictly define APIs, helping the Agent interact accurately and minimize parameter errors.
- Evaluation Knowledge: Establish a "Golden Dataset" and "LLM-as-a-judge" technique to comprehensively evaluate both the reasoning process and final results.
- Governance and Monitoring: Build tracing systems, version management, and set up "Guardrails" to ensure corporate safety.
- Best Practices & Mistakes: Avoid overusing Agents for simple tasks, always have Fail-safe mechanisms, and perform periodic regression testing to ensure stability.
- FAQ: Understand the difference between Prompt Engineering and Agent Design, as well as strategies for choosing the right framework (LangChain/CrewAI) for actual needs.
Core Difference: AI Agent vs. Workflow
Understanding the nature of the work is the first step to avoid wasting resources on overly complex solutions.
| Feature | Traditional Workflow | AI Agent |
|---|---|---|
| Mechanism | Fixed logic chain (Input → A → B → Output). | System decides its own steps (Goal → Reasoning → Action). |
| Predictability | Very high. | Low (context-dependent). |
| Adaptability | None. | Self-adjusts based on new data. |
| Best For | Repetitive tasks, standard processes. | Tasks requiring judgment, multi-step. |
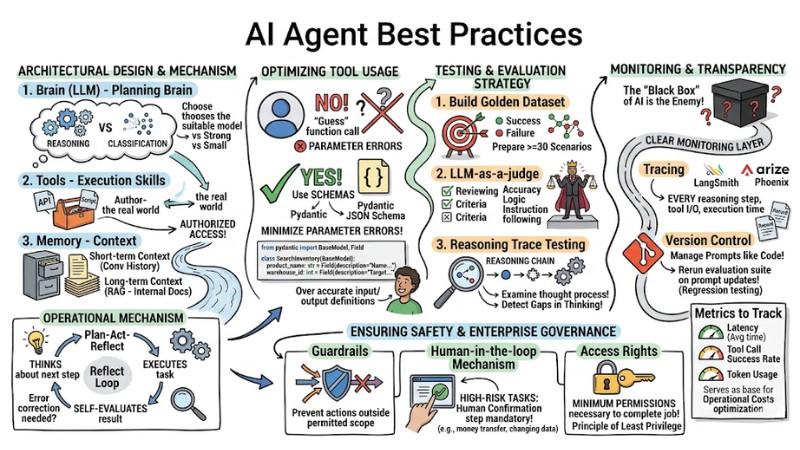
Architectural Design: Principles for Building the Foundation
An effective AI Agent operates based on three main layers: Brain (LLM), Tools (execution skills), and Memory (context).
- Brain (LLM): Acts as the planning brain. You need to choose a model suitable for the task complexity (e.g., strong models for reasoning, small models for classification).
- Tools: These are the API functions or scripts that the Agent is authorized to access.
- Memory: Manages short-term context (conversation history) and long-term context (enterprise knowledge via RAG - retrieving information from internal documents).
Operational Mechanism: Always apply the Plan-Act-Reflect loop so the Agent thinks about the next step, executes the task, and then self-evaluates the result to decide if error correction is needed.
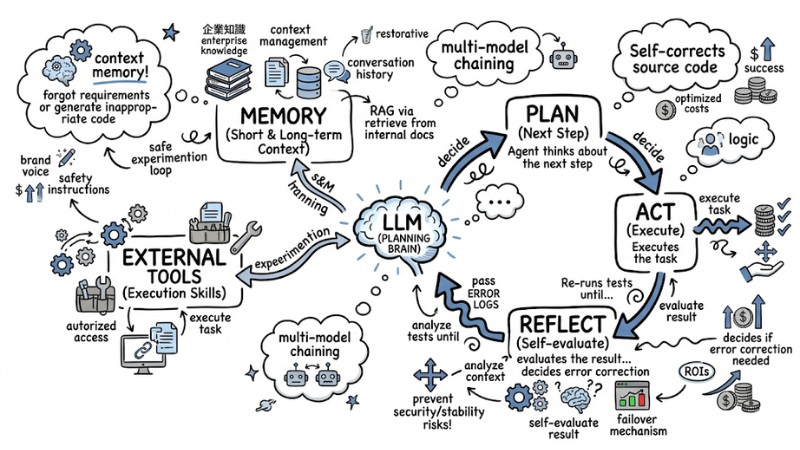
Plan-Act-Reflect model with LLM and connecting external tools
Optimizing Tool Usage
Instead of letting the Agent "guess" how to call a function, you should use Schemas (data structures) so the Agent interacts accurately with your system. Use JSON Schema or Pydantic to clearly define inputs and outputs, thereby minimizing common parameter errors when the LLM attempts to self-interpret the API.
# Example: Defining Tool Schema using Pydantic
from pydantic import BaseModel, Field
class SearchInventory(BaseModel):
product_name: str = Field(description="Name of the product to look up")
warehouse_id: int = Field(description="Target warehouse ID")
Testing and Evaluation Strategy
Unlike standard software, an Agent must be evaluated based on a "Golden Dataset" (a set of standard sample scenarios). Specifically:
- Build a Golden Dataset: Prepare at least 30 scenarios including both success and failure cases.
- LLM-as-a-judge: Use a more powerful LLM to evaluate the Agent's output based on specific criteria (accuracy, logic, instruction following).
- Reasoning Trace Testing: Instead of just checking the final result, examine the reasoning process to detect gaps in the Agent's thinking.
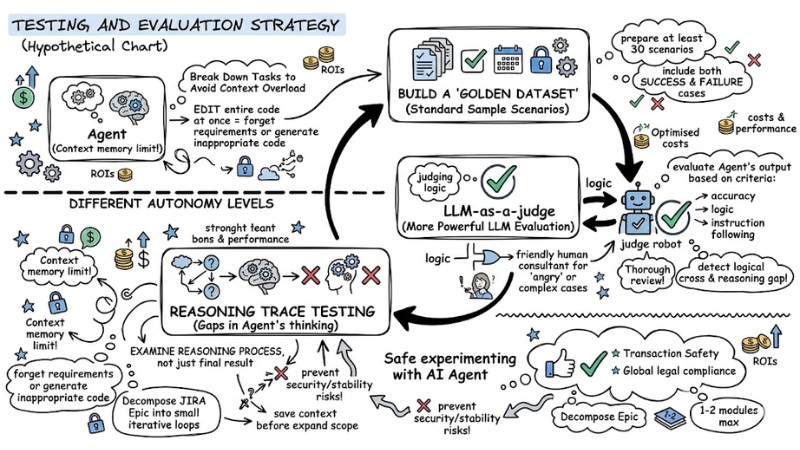
Testing and evaluation strategy
Monitoring and Maintaining Transparency
The "black box" of AI is the enemy of the enterprise; if you cannot see inside, you cannot understand why an Agent made a wrong decision. Therefore, you need to build a clear monitoring layer:
- Regarding Tracing: Use tools like LangSmith or Arize Phoenix to record every reasoning step, tool input/output, and execution time.
- Regarding Version Control: Manage versions for Prompts just like managing code versions (Git). When updating a prompt, you must rerun the evaluation suite (regression testing) to ensure old features aren't broken.
- Metrics to Track:
- Latency: Average time for the Agent to respond, directly impacting user experience.
- Tool call success rate: The rate of successful tool calls, helping early detection of integration or schema errors.
- Token usage: Tokens consumed per task, serving as the basis for optimizing AI Agent system operational costs.
Ensuring Safety and Enterprise Governance
To deploy an AI Agent in a business environment safely and controllably, you must design "guardrails" around it, rather than just focusing on task processing capabilities:
- Guardrails: Establish input/output filters to prevent the Agent from performing actions outside its permitted scope.
- Human-in-the-loop mechanism: For high-risk tasks (such as transferring money or changing system data), a human confirmation step is mandatory before execution.
- Access Rights: Provide the Agent only with the minimum permissions necessary to complete the job (Principle of Least Privilege).
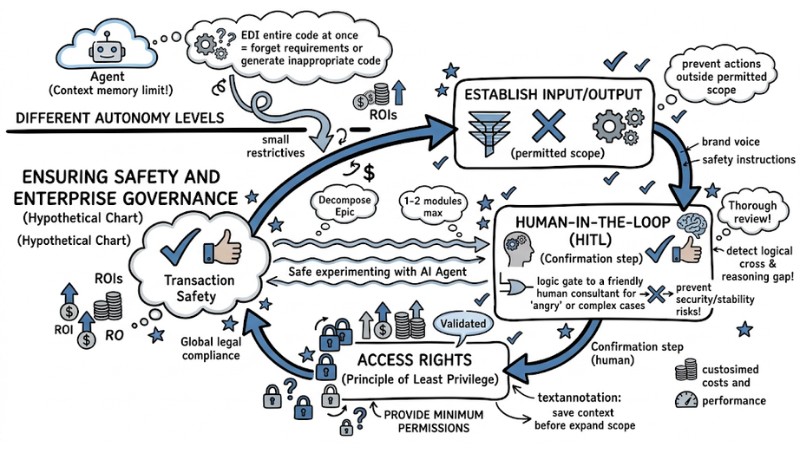
Ensuring Safety and Enterprise Governance
Common Mistakes to Avoid
In the process of building and deploying AI Agents, there are several "traps" you should avoid from the start:
- Abusing Agents: Don't try to turn everything into an Agent. If a process can be handled cleanly with traditional code, use code to ensure simplicity and control.
- Lacking Fail-safe mechanisms: The Agent must know to stop and report errors if confidence is low, rather than attempting to guess.
- Ignoring Regression Testing: Every change in a prompt can cause unintended results elsewhere. Test continuously.
In-depth FAQ on AI Agent Best Practices
What is the difference between Prompt Engineering and Agent Design?
Prompt Engineering focuses on optimizing input content for the best results. Agent Design includes Prompt Engineering but focuses on the system (planning, tool management, memory, and error feedback).
Should I use LangChain or CrewAI?
If you need to build complex and flexible workflows, LangChain provides deep control. If you want to build multi-agent systems that coordinate with each other, CrewAI is a more optimal choice.
How do I know if a task truly needs an Agent?
If the task requires judgment, the ability to integrate multiple data sources, and results that cannot be defined by rigid logic, then it is a good opportunity to use an AI Agent.
When should I build an AI Agent instead of using a Workflow?
You should build an AI Agent when the task requires flexibility, decision-making based on complex context, or the need to adapt rather than following a fixed process.
What are the basic principles when designing AI Agent architecture?
The basic principle is layering the architecture into "Brain" (LLM), "Tools" (skills), and "Memory" (context), while applying the "Plan-Act-Reflect" loop to help the Agent reason before execution.
How to optimize tool usage for an AI Agent?
Prioritize "Schema First" design, using Pydantic or JSON Schema to strictly define tool inputs/outputs, ensuring determinism and avoiding parameter deviation.
What is an effective testing strategy for an AI Agent?
Build a "Golden Dataset" with at least 30 scenarios, including success, edge, and failure cases. Evaluate the reasoning process, not just the final result.
Why is observability important for AI Agents?
Observability helps debug effectively by tracking the reasoning, decision, and tool usage processes in detail. It is also necessary for cost control and continuous performance improvement.
How to ensure safety and governance for AI Agents?
Apply "Guardrails" to filter inputs/outputs, restrict access rights, and use "Human-in-the-loop" mechanisms for high-risk decisions to enhance approval and oversight.
What common mistakes should be avoided when building an AI Agent?
Avoid excessive overuse of Agents, lacking "Fail-safe" mechanisms when encountering problems, and forgetting to perform periodic regression testing.
Read more:
- How to Write Expert-Level Prompts for AI Agents Handling Complex Tasks
- How to Transition from Single-Agent to Multi-Agent Systems
- Detailed Guide to Effectively Deploying AI Agents in Production
In summary, an AI Agent only truly provides value when designed as a system with a clear architecture, strict monitoring, and specific responsibility boundaries. If you correctly combine Brain–Tools–Memory, apply Plan–Act–Reflect, Schema First, Golden Dataset, along with guardrails and human-in-the-loop, you will have an Agent reliable enough for enterprise deployment, rather than just an experiment.
Tags