What Are Tokens? Types of Tokens and How to Optimize Token Costs Effectively

When it comes to the concept of tokens in the IT industry, depending on whether you are a security engineer, a blockchain developer, or a data expert, this term carries completely different definitions. In this article, I will focus on decoding the unique concept of tokens in the field of AI and LLM systems. In this article, I will explore with you in detail the benefits, limitations, and the most effective ways to optimize token costs!
Key points
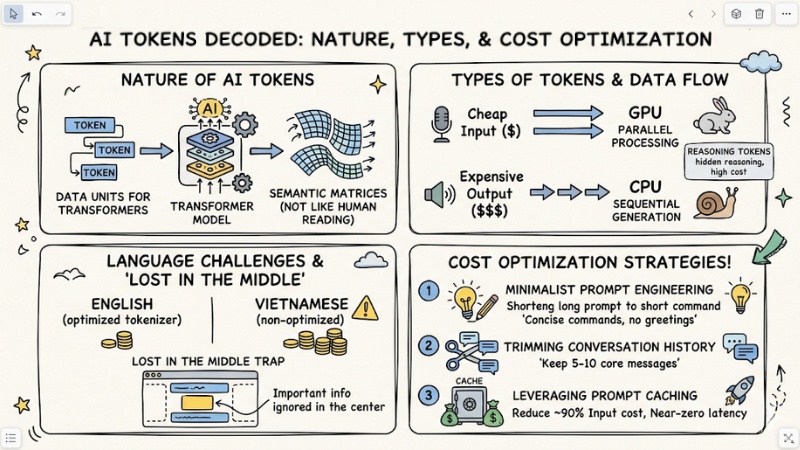
- The nature of AI Tokens: Understand that a Token is the base data unit that Transformer models use to process semantic matrices, rather than reading and understanding text like humans.
- Language challenges: Recognize the cost disparity between English and Vietnamese due to the tokenizer characteristics of current LLM models.
- Classification and cost: Clearly distinguish between Input tokens (processed in parallel, cheap) and Output tokens (processed sequentially, expensive, resource-intensive). Master the concept of Reasoning tokens (hidden reasoning) in deep-thinking models.
- Context Window: Understand the context limit but avoid the "Lost in the middle" trap – the phenomenon where AI forgets important information located in the middle of a long document.
- Optimization strategy: Apply 3 backbone techniques: Minimalist Prompt Engineering, trimming conversation history at the Backend, and leveraging Prompt Caching.
- FAQ resolution: Master cost estimation, the risks of context limits, and the nature of the Tokenization process in modern AI systems.
Quick classification: 3 types of Tokens in the IT industry
To save you time looking up documentation, here are the fundamental differences in the nature of the 3 most common types of tokens today:
| Token Type | Technical Nature | Practical Application |
|---|---|---|
| Security token | Encryption used to authenticate access rights (Example: JSON Web Token - JWT, OAuth). | Authenticating users when calling API, logging into internal systems. |
| Crypto Token | Digital assets issued and operated on an existing Blockchain platform. | Used in financial transactions, ERC-20 standard smart contracts. |
| AI Token | Base data unit (e.g., word, syllable, pixel) used as input or output for machine learning models. | Calculating AI API calling costs, quantifying input data for LLM models. |
What is an AI Token? The nature of Tokenization
Definition
In the field of artificial intelligence, a Token is the base data unit tokenized from input text, images, or audio, helping AI models read, understand, predict, and process information in the form of arithmetic sequences.
In terms of architectural nature, Transformer models do not understand text the way humans do. They are just machines that process mathematical matrices. Therefore, before a piece of text is fed into a model, it must pass through a separator called a Tokenizer. This component is responsible for chopping up text (Tokenization) and assigning each piece a unique arithmetic identifier.
Example: In English, the word "darkness" might not be recognized by an AI as a complete word. The tokenizer might cut it into two separate tokens: "dark" (ID: 217) and "ness" (ID: 655). These IDs are then converted into arithmetic vectors for the system to calculate semantics based on spatial matrices.
Note: The specific ID codes (217 and 655) depend on the vocabulary of each tokenizer and are not used consistently across all AI systems.
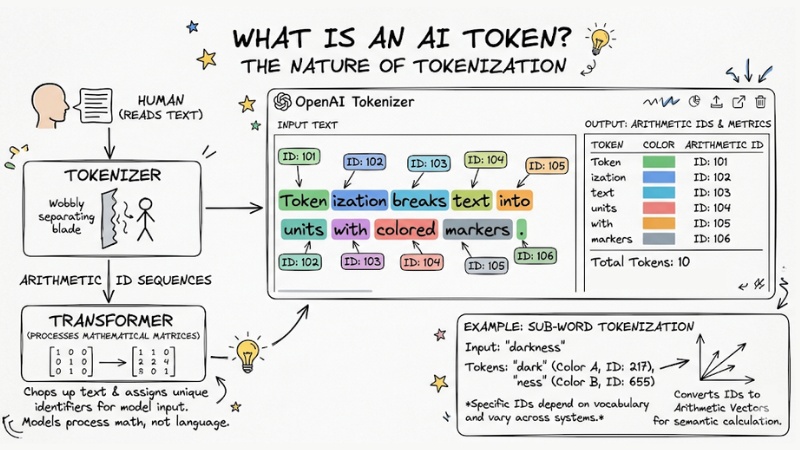
A token is the base data unit tokenized from input text, images, or audio
Multimodal processing
Today, tokens are not just limited to text. With the explosion of multimodal generative AI, systems use different types of tokens:
- Vision token: Chops images into pixel or voxel patches for visual recognition.
- Audio token: Converts sound waves into semantic vectors so models can "hear" and respond in real-time.
The language disadvantage: English vs. Vietnamese
When deploying AI projects in the Vietnamese market, one of the biggest "pain points" for engineers is API costs. Why are API calls in Vietnamese always more expensive and slower than in English?
The answer lies in the non-fixed length property of tokens. Popular current models (like GPT-4 or Claude) are trained primarily on English datasets. Therefore, their Tokenizer dictionaries are optimized to recognize English: Usually 1 word ≈ 1.33 tokens (or 1 token ≈ 0.75 words) in English, due to the subword tokenization mechanism.
However, with Vietnamese, because vocabulary often consists of compound words and is less common in training sets, AI has to chop a word into many individual characters or syllables. This causes a spike in computational costs and latency.
| Language | Sample sentence | Word count | Token count (Estimate) | Token/Word Ratio |
|---|---|---|---|---|
| English | "I love programming in Golang" | 5 words | 5 - 7 tokens | ~1.0–1.4 |
| Vietnamese | "Tôi thích lập trình bằng Golang" | 6 words | 8 - 12 tokens | ~1.6–2.0 |
Quick estimation rules:
- English: 1 Token ≈ 0.75 words (100 tokens ~ 75 words).
- Vietnamese: 1 Word ≈ 1.5 to 2.5 tokens (Depending on the complexity of specialized vocabulary).
The economics of Tokens: Input, Output, and Context Window
Token classification
To optimize AI architecture, you must understand how providers price and allocate computational resources based on Data flow.
- Input tokens: The amount of data you send to the AI via prompts. This process is handled in parallel on the GPU, is extremely fast, and consumes few resources. Therefore, the price of Input tokens is usually very cheap.
- Output tokens: The result the AI returns. This generation process (Inference) must happen sequentially—the preceding word determines the next word. Because they cannot be processed in parallel, Output tokens take a lot of computation time, leading to prices 3 to 5 times more expensive than Input.
- Reasoning tokens: Appear in models requiring deep reasoning (e.g., o1). The system automatically generates thousands of hidden tokens during the "thinking" process to resolve logic before outputting the final result. This increases accuracy but burns a lot of costs.
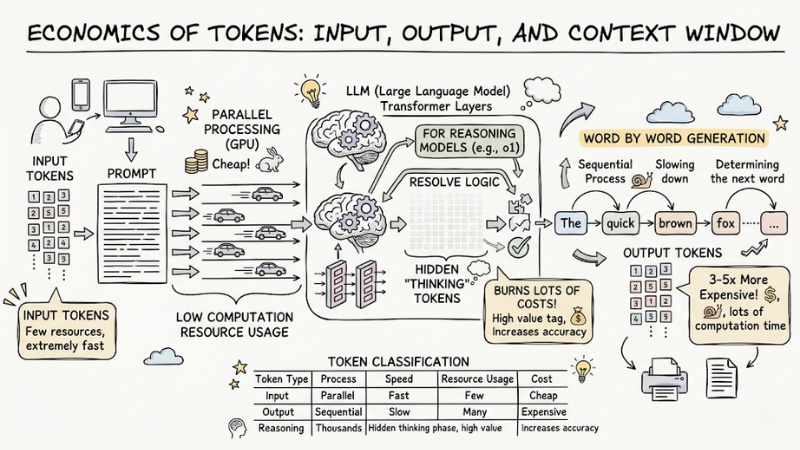
Data Flow architecture diagram illustrating Input processed in parallel passing through the LLM and outputting Output sequentially
Context Window
The Context window is the total limit on the number of tokens (including both Input and Output) that an AI can remember in one session. Currently, models like Claude 3.5 Sonnet support up to 200k tokens.
Technical Note: Do not maximize the Context window if not necessary. When you cram too many documents into a prompt, LLM models often encounter the "Lost in the middle" phenomenon (information omission hallucination) - AI tends to remember the beginning and end of a document well, but forgets important information located in the middle.
How to optimize token costs when deploying in practice
To avoid API budgets "evaporating" uncontrollably when scaling up applications, engineering teams need to apply the following techniques:
- Minimalist Prompt Engineering: Write concise commands that get straight to the point. Remove unnecessary conjunctions and greetings (e.g., "Please...", "Hello AI") to save input tokens.
- Trimming conversation history: Instead of resending an entire conversation thread of 50 messages for every API call, set up backend logic to only keep the last 5-10 messages containing the core context.
- Integrate Prompt Caching: This is the current "heavy artillery" technique. By caching repeated context (e.g., complex system prompts or RAG documents), you can reduce Input token costs by up to 90% and bring Time-to-first-token latency to near zero.
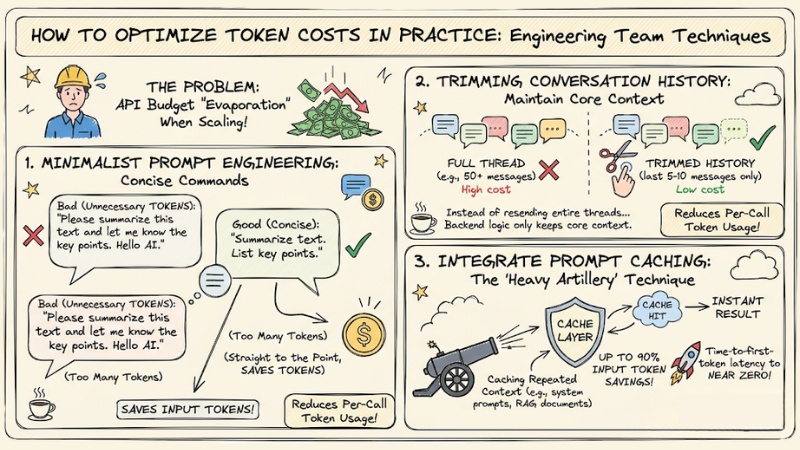
How to optimize token costs when deploying in practice
Frequently asked questions about tokens in AI
What is an AI token?
In AI, a token is the smallest data unit that a large language model (LLM) uses to process text. Instead of reading words, the model tokenizes data into arithmetic code segments to calculate probabilities and predict content.
Why does Vietnamese cost more tokens than English?
Because most AI models are trained primarily on English datasets, tokenizers struggle with the structure of the Vietnamese language. As a result, a Vietnamese word is often tokenized into 2-3 tokens, causing API costs to increase significantly.
What is the difference between Input tokens and Output tokens?
Input tokens are data you send for AI processing (parallel processing, low cost). Output tokens are results the AI generates, word by word in sequence (sequential processing, higher cost, and higher computational resource requirement).
How to estimate token costs for an application?
The rule of thumb for token costs is: 1 English word is equivalent to about 1 token, while 1 Vietnamese word on average takes 1.5 to 2 tokens. You should add 20% extra capacity as a buffer for system requests and conversation history.
What is a Context Window and why should you pay attention to it?
The Context Window is the maximum limit on the number of tokens a model can remember in one session. When this limit is exceeded, AI forgets information in the middle or beginning of the conversation, a phenomenon called "Lost in the middle".
What is Prompt Caching and does it help reduce costs?
Prompt Caching is a technique of storing fixed prompt parts (like system prompts or long documents) in cache memory. Instead of processing from scratch, the AI reuses this data, helping to reduce costs by up to 90% and speed up response times.
How to optimize the number of tokens used?
- Write concise prompts and omit redundant words.
- Only resend the most critical conversation history segments.
- Use Prompt Caching for repeated input data.
- Choose models with effective tokenizers for the target language.
See more:
- What Is Machine Learning? Core Principles and Real-World Applications
- What is MCP Transport? Understanding the Transmission Mechanisms of the Model Context Protocol
- What Is an Orchestration Layer? Understanding Its Importance in System Architecture
In essence, tokens are the "fuel" operating every machine learning model today. Mastering the Tokenization mechanism, the language cost disparity, and optimizing Input/Output flows is not just theoretical knowledge, but a survival skill for modern Data Scientists and Backend Developers to ensure system performance (ROI).