What is MLOps? Building a Standard Machine Learning Pipeline

MLOps (Machine Learning Operations) is a set of practices and tools that help bring machine learning models from a local environment to a production environment in a stable, automated, and monitorable manner. This method standardizes the entire Machine Learning Pipeline (from data, training, and deployment to monitoring and retraining) so that models create sustainable value for businesses, rather than just focusing on accuracy in a local environment. In this article, we will analyze the reasons why AI projects fail and how to standardize data flows so you can clearly understand what MLOps is.
Key Takeaways
- Nature of MLOps: Understand MLOps as the strategic intersection of Machine Learning, Data Engineering, and DevOps aimed at standardizing the AI development lifecycle, shifting from "running models on Notebooks" to "sustainable AI operations in Production."
- Decoding Operational Pain Points: Master the reasons why AI projects fail due to Siloed Teams, OOM (Out of Memory) errors during scaling, and model performance degradation caused by Data Drift & Concept Drift over time.
- Distinguishing DevOps from MLOps: Identify the vital difference: DevOps manages Code, while MLOps must manage the complex trinity of Code, Data, and Model, along with automated Continuous Training (CT) loops.
- 4-Phase MLOps Architecture: Establish a professional pipeline including: Data Standardization -> Training and Experiment Tracking -> Deployment -> Monitoring and Automated Retraining.
- Tech Stack Toolkit: Master the modern tool ecosystem: DVC (large-scale data versioning), Kubeflow/Airflow (workflow orchestration), and Docker/K8s (GPU infrastructure optimization).
- Evolution to LLMOps and AgentOps: Understand the shift from managing Tensors/Weights to LLMOps (Fine-tuning, RAG, Token optimization) and AgentOps (coordinating autonomous AI groups, security in Multi-tenant environments).
- FAQ Resolution: Clarify MLOps' role in bridging the gap between Data Scientists and Backend engineers, how to handle Data Drift with Continuous Training, and why MLOps is the "bridge" bringing AI from experimentation to actual profit.
Definition of MLOps and the Pains of Traditional Machine Learning
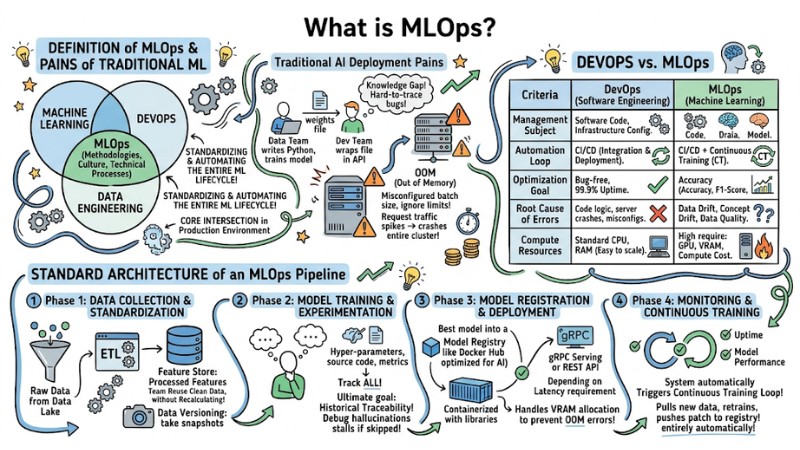
MLOps (Machine Learning Operations) is a set of methodologies, culture, and technical processes aimed at standardizing and automating the entire machine learning system development lifecycle (ML Lifecycle). It is the core intersection of Machine Learning, DevOps, and Data Engineering in a production environment.
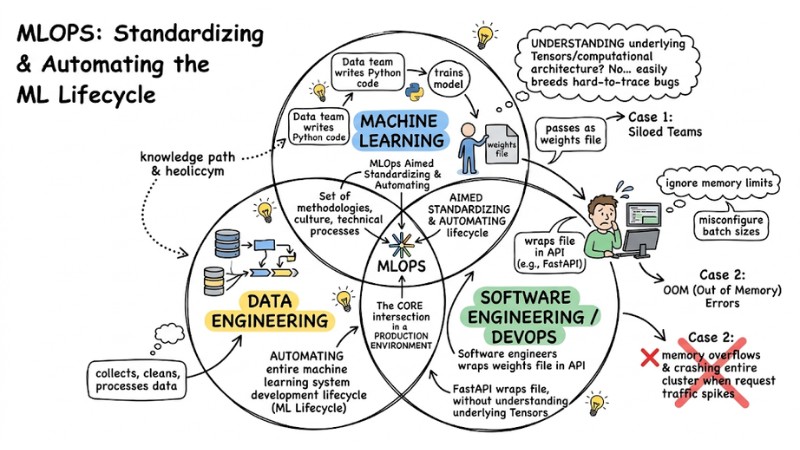
MLOps is the core intersection of Machine Learning, DevOps, and Data Engineering
Why are technology companies eager to apply MLOps? Look at the "pains" of traditional AI deployment:
- Siloed Teams: The Data team writes Python code and trains the model, then passes it to the Software Engineering team as a weights file. The Dev team simply wraps that file in an API (like FastAPI) without understanding the underlying Tensors or computational architecture, creating a knowledge gap that easily breeds hard-to-trace bugs.
- OOM (Out of Memory) Errors: When deploying to a server, software engineers might misconfigure batch sizes or ignore memory limits. This leads to models consuming RAM beyond thresholds, causing memory overflows and crashing the entire cluster when request traffic spikes.
The Drift Effect: When AI Models Degrade Over Time
Traditional software, once compiled, runs stably according to static logic. In contrast, AI systems are dynamic by nature. Model performance will gradually decrease over time (Model Degradation) due to two main causes:
- Data Drift: The statistical distribution of input data in the real world deviates from the original dataset used to train the model.
- Concept Drift: The logical relationship between Input and Output changes (e.g., the definition of "fraudulent transaction" must be constantly updated according to new hacker tactics).
Understanding what MLOps is helps you build a system capable of automatically identifying these data changes for timely remediation.
Distinguishing DevOps and MLOps
Many developers mistakenly believe that simply setting up CI/CD for an AI project completes MLOps. This is a serious error in systems thinking.
While DevOps primarily manages Code, MLOps must solve a more complex problem with three factors: Code, Data, and Model. The core and vital difference between DevOps and MLOps is the concept of Continuous Training (CT). Software does not fix its own code, but AI must automatically ingest new data to update its weights.
| Technical Criteria | DevOps (Software Engineering) | MLOps (Machine Learning) |
|---|---|---|
| Management Subject | Software Code, Infrastructure Config. | Code, Data, Model. |
| Automation Loop | CI/CD (Continuous Integration & Deployment). | CI/CD + Continuous Training (CT). |
| Optimization Goal | Bug-free software, 99.9% Uptime. | Accuracy (Accuracy, F1-Score, Loss). |
| Root Cause of Errors | Code logic errors, server crashes, misconfigs. | Data Drift, Concept Drift, Data Quality. |
| Compute Resources | Standard CPU, RAM (Easy to scale). | High requirements for GPU, VRAM, Compute Cost. |
| Monitoring | Latency, Memory usage, Error Rate. | Similar to DevOps + Model Performance. |
Differences in Testing and Versioning:
- Testing Process: In DevOps, you write Unit Tests or Integration Tests to ensure functions run correctly. However, MLOps is more demanding. You must perform Data Validation (checking data distribution, missing values), then run Shadow Deployment (deploying a new model hidden alongside the old one) to verify prediction accuracy in production.
- Versioning: Using Git is the gold standard of DevOps. However, Git becomes ineffective with datasets hundreds of GB in size or massive weights files. MLOps mandates Semantic Versioning for Data and Model. Thanks to this, engineers ensure Reproducibility (recreating exact training results based on past data and code versions).
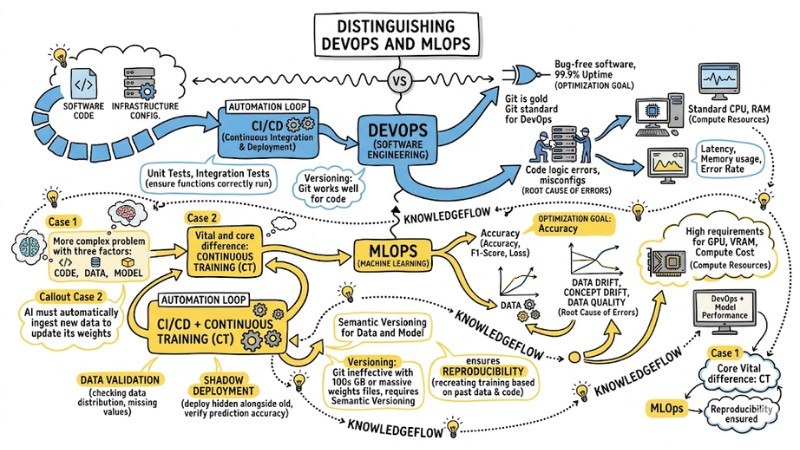
Distinguishing between DevOps and MLOps
Standard Architecture of an MLOps Pipeline
To limit the risk of system "collapse" during scaling, data engineers typically follow reference architectures from AWS or GCP instead of cramming all preprocessing and training into a single notebook file.
A professional Machine Learning Pipeline, ready for production, is always separated into 4 independent but tightly linked stages as follows:
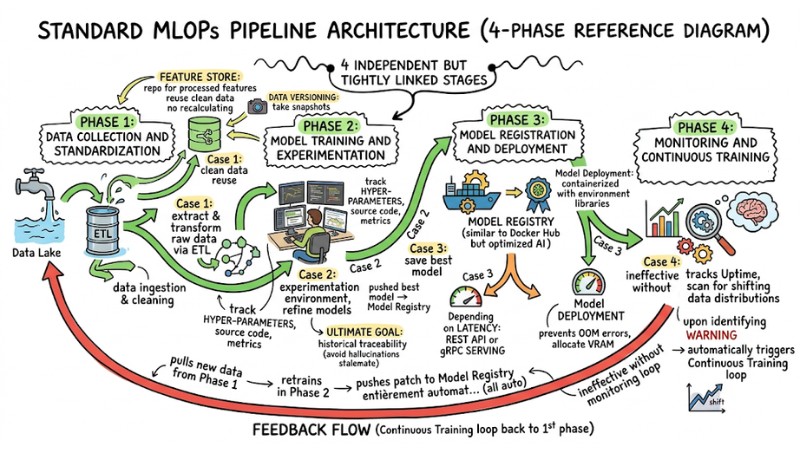
Standard architecture of a MLOps Pipeline
Phase 1: Data Collection and Standardization
This is the data ingestion and cleaning step. Raw data from the Data Lake is extracted and transformed through ETL processes. The architectural highlight in this phase is the Feature Store – a repository for processed features. This tool helps internal teams reuse clean data without recalculating from scratch. Data Versioning is also activated to "take snapshots" of the data.
Phase 2: Model Training and Experimentation
The experimentation environment is where Data Scientists refine AI models. This process must track all Hyper-parameters, source code, and metrics. The ultimate goal of the Machine Learning Pipeline at this step is historical traceability. If skipped, debugging a model experiencing hallucinations in production becomes a stalemate.
Phase 3: Model Registration and Deployment
After training, the best model is not pushed directly but saved in a Model Registry (a repository similar to Docker Hub but optimized for AI). When ready, the Model Deployment process takes place. The model is containerized with environment libraries. Depending on Latency requirements, Model Deployment can serve as a REST API or high-speed gRPC Serving. This phase also handles VRAM allocation to prevent OOM errors.
Phase 4: Monitoring and Continuous Training
An MLOps system is ineffective without a monitoring loop. This phase tracks not only Uptime but also scans continuously for signs of shifting data distributions. Upon identifying a warning, the system automatically triggers a Continuous Training loop. It pulls new data from Phase 1, retrains in Phase 2, and pushes the patch to the Model Registry entirely automatically.
Typical Tech Stack for an MLOps Engineer
The AI tool ecosystem changes almost daily, but a Senior MLOps engineer prioritizes placing each tool in the right phase of the entire pipeline. Below are standard MLOps tool groups used in a complete ecosystem architecture.
- Data and Source Version Control: DVC (Data Version Control) or Pachyderm are suitable solutions for storing massive data snapshots that traditional Git cannot handle.
- Experiment Tracking: MLflow or Weights & Biases (W&B) are often used in Phase 2 to save the entire history of hyperparameter adjustments and loss functions.
- Orchestration: Apache Airflow or Kubeflow act as the conductors, deciding which tasks run in parallel or sequentially in the pipeline.
- Containerization and Infrastructure: Docker and Kubernetes (K8s) help allocate GPU resources flexibly, ensuring consistent environments from local to cloud.
- Model Serving: TensorFlow Serving, TorchServe, or FastAPI are optimized solutions for maximizing throughput and minimizing API latency.
import mlflow
# Initialize MLflow tracking
mlflow.set_experiment("Fraud_Detection_Pipeline")
with mlflow.start_run():
# Log hyperparameters
mlflow.log_param("batch_size", 64)
mlflow.log_param("learning_rate", 0.001)
# Simulate training process
accuracy = train_model()
# Log metrics
mlflow.log_metric("accuracy", accuracy)
# Save model to internal Model Registry
mlflow.sklearn.log_model(sk_model=model, artifact_path="model_output")
Future Evolution: From MLOps to LLMOps and AgentOps
Core AI technology is changing rapidly, especially following the wave of Large Language Models (LLMs), forcing traditional MLOps approaches to adapt. This is because training models from scratch at a cost of millions of dollars is increasingly impractical.
The LLMOps era shifts focus to fine-tuning (LoRA, QLoRA), RAG, and Prompt Engineering, where the problem is not just managing Tensors, but also controlling context windows, token costs, and mitigating hallucinations.
Further ahead, AgentOps emerges as the next evolutionary layer: instead of a single model, the system must operate an entire team of AI Agents. This poses new challenges for task delegation, context sharing, and security in multi-tenant enterprise environments.
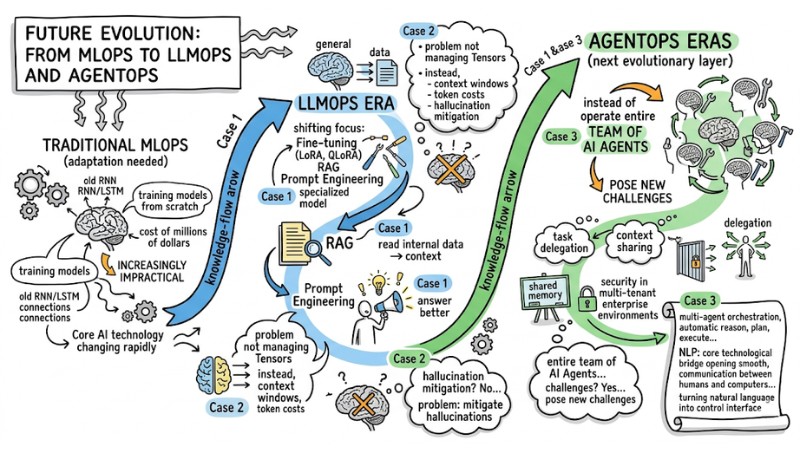
Future Evolution: From MLOps to LLMOps and AgentOps
Frequently Asked Questions about MLOps
What is MLOps?
MLOps (Machine Learning Operations) is a standardized set of processes that helps automate the machine learning lifecycle, from development and testing to deployment. It combines DevOps culture, data engineering, and machine learning science to ensure models operate stably and accurately in real-world environments.
Why implement MLOps in an AI project?
MLOps helps solve the "disillusionment" of moving AI from a Jupyter Notebook to a production environment. It automates management, helps early detection of performance degradation (Data Drift), ensures reproducibility, and minimizes operational errors caused by discrepancies between training and real-world environments.
What is the main difference between DevOps and MLOps?
The main difference lies in the scope and system management over time. DevOps primarily handles the code lifecycle of software, whereas MLOps must also manage data and models, requiring a Continuous Training mechanism to retrain models automatically when real-world data changes.
What are the most popular MLOps tools today?
Standard tools include:
- Data Versioning: DVC, LakeFS.
- Experiment Tracking: MLflow, Weights & Biases.
- Workflow Orchestration: Airflow, Kubeflow.
- Containerization & Serving: Docker, Kubernetes, FastAPI, TF Serving.
How to handle Data Drift in MLOps?
You need to establish a continuous monitoring system to track input data distributions. When real-world data deviates from training data, the system automatically triggers a "Continuous Training" process to retrain the model with new data, ensuring accuracy.
What is the difference between MLOps and LLMOps/AgentOps?
MLOps manages the traditional machine learning model lifecycle, LLMOps focuses on fine-tuning and prompt optimization for LLMs, while AgentOps is a higher level focused on managing, coordinating, and securing autonomous AI Agents that perform complex tasks in groups via protocols like MCP.
Read more:
- What is an AI-First Mindset? Benefits and Enterprise Applications
- What is AI Bias? Understanding Biases in AI and How to Control Them
- What is Deep Learning? Applications, Future Trends, and Essential Knowledge
In summary, MLOps is the operational framework that helps machine learning models function effectively not just on a notebook but in a production environment, facing changing data and system scaling pressures. Businesses that master MLOps (from the 4-stage pipeline, testing, and versioning to monitoring, alongside new generations like LLMOps and AgentOps) will have a clear advantage in turning AI from experimentation into real, sustainable business value.