What is AI Bias? Understanding Biases in AI and How to Control Them
AI bias is the phenomenon where artificial intelligence models produce biased, unfair results for a specific group of users due to learning from data that contains existing human prejudices. As businesses expand the application of LLMs into real-world operations, identifying and controlling AI bias is no longer just an academic story but has become a mandatory requirement to protect brand reputation and comply with ethical standards. In this article, we will analyze the technical roots of AI bias and the defensive layers that help system engineers mitigate risks in production environments.
Key Takeaways
- The Essence of AI Bias: Understand that AI Bias is not a "rebellion" of machines, but a reflection of hidden prejudices from humans and input data, leading to systematic biased decisions.
- Infiltration Stages: Master the 3 blind spots (collection, labeling, training) where bias can creep into the system, especially the danger from Proxy variables causing subtle discrimination.
- The Evolution of Bias: Clearly distinguish risks between traditional Machine Learning (numerical/authorization bias) and modern LLMs (linguistic, cultural, gender stereotypes, and data poisoning risks).
- Multi-layered Defense Strategy:
- Data Layer: Use Oversampling techniques and measurement libraries to quantify model fairness with actual code.
- Application Layer: Apply Role-based prompts to force AI to maintain neutrality, set up output filters (Guardrails), and implement Context Isolation to avoid cross-contamination of bias between user groups.
- Standard Compliance: Realize that controlling AI Bias is no longer an option but a prerequisite to meet international risk management frameworks such as NIST and the EU AI Act.
- FAQ Resolution: Clarify how to detect bias, why LLMs default to associating "CEO" with "he," and why context isolation is the "key" to safe AI operation in multi-user enterprise environments.
The Essence of AI Bias
AI Bias (Artificial Intelligence Bias) is a systematic error in the output of machine learning algorithms. This occurs when a model makes unfair or discriminatory decisions against a specific demographic group due to errors in training data or system design.
The consequences of algorithmic bias often manifest in the system favoring a predefined group while disadvantaging another. In computer science, this phenomenon is the clearest evidence for the "Garbage in, Garbage out" principle. No matter how complex your Neural Network architecture is, if the input data is full of prejudice, the predicted results will inevitably be biased, creating algorithmic bias.
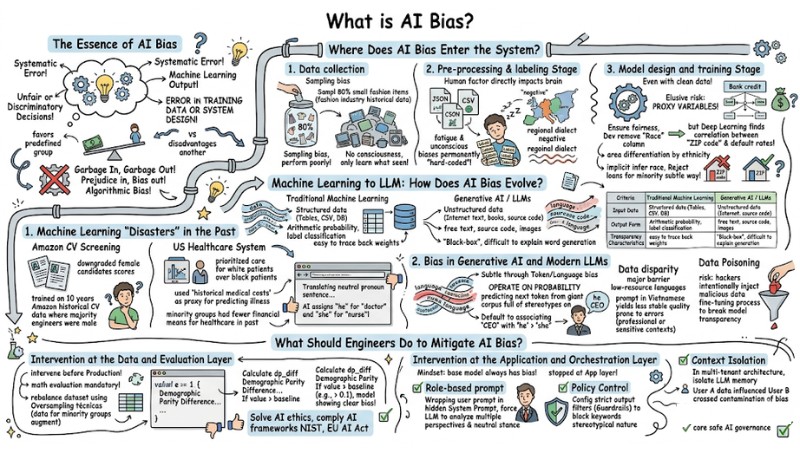
Where Does AI Bias Enter the System?
AI bias is not naturally born; it infiltrates the system's data processing flow through 3 core stages:
- Data collection.
- Pre-processing and labeling.
- Model design and training.
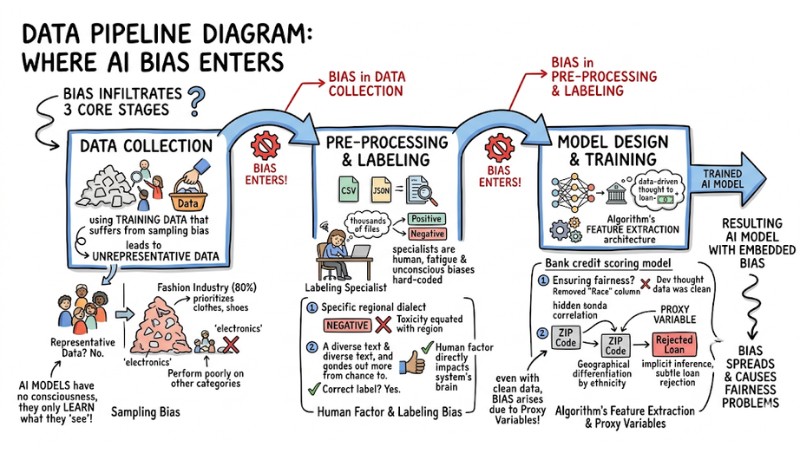
3 Infiltration Pathways of AI Bias
1. Collection Stage
The most serious error at this step is using training data that suffers from sampling bias, leading to unrepresentative data.
Example:*** *If you train a product recommendation model for an e-commerce platform but 80% of the historical data comes only from the fashion industry, the model will tend to prioritize recommending clothes and shoes, and perform poorly when suggesting products in other categories like electronics or home appliances. AI models have no consciousness; they only learn from exactly what they "see" in the training data.
2. Pre-processing and Labeling Stage
This is the stage where the human factor directly impacts the system's brain through the data labeling process. Labeling specialists are, after all, human. When they have to analyze and label thousands of JSON or CSV files every day, their fatigue and unconscious biases are permanently "hard-coded" into the system.
If a labeling specialist is biased and consistently labels sentences using a specific regional dialect as "negative," the model will equate that region with toxicity.
3. Design and Training Stage
Even if an engineer has a perfectly clean dataset, data bias can still arise due to the algorithm's feature extraction architecture. The most elusive risk at this stage is the phenomenon of Proxy variables.
Example: For a bank credit scoring model: To ensure fairness, the Dev actively removed the "Race" column from the dataset. However, the Deep Learning algorithm automatically found a hidden correlation between the "ZIP code" column and default rates. Since geographical areas often have population differentiation by ethnicity, the model used the ZIP code as a proxy variable to implicitly infer race, thereby continuing to reject loans for minority groups in an extremely subtle way.
From Machine Learning to LLM: How Does AI Bias Evolve?
The shift from Machine Learning models predicting numbers to Large Language Models (LLMs) generating text has completely changed the morphology of bias.
| Criteria | Traditional Machine Learning | Generative AI / LLMs |
|---|---|---|
| Input Data | Structured data (Tables, CSV, Database). | Unstructured data (Internet text, books, source code). |
| Output Form | Arithmetic probability, label classification. | Free text, source code, images. |
| Transparency | Easy to trace back weights. | Black-box, difficult to explain word generation. |
| Bias Characteristics | Bias in authorization, score prediction. | Linguistic stereotypes, cultural hallucinations, gender bias. |
1. Machine Learning "Disasters" in the Past
Before the era of Generative AI, algorithmic bias primarily resulted in resource allocation consequences based on numbers.
- Amazon CV Screening: An automated recruitment algorithm downgraded the scores of female candidates' resumes. The reason was that the system was trained on 10 years of Amazon historical CV data, where the majority of hired engineering personnel were male.
- US Healthcare System: A risk prediction algorithm prioritized care for white patients over black patients. The mistake lay in the system using "historical medical costs" as a proxy for predicting illness, ignoring the fact that minority groups often had fewer financial means to pay for healthcare in the past.
2. Bias in Generative AI and Modern LLMs
With LLMs, bias appears subtly through Token/Language bias. Because LLMs operate based on the probability of predicting the next token from a giant corpus full of stereotypes on the Internet, they default to associating the keyword "CEO" with the pronoun "he" instead of "she."
Particularly, data disparity creates a major barrier for low-resource languages like Vietnamese. Since most LLM models are trained primarily on English data, prompting in Vietnamese often yields less stable response quality and is more prone to errors compared to English, especially in professional or sensitive contexts. Additionally, LLMs face the risk of Data Poisoning - where hackers intentionally inject malicious data during the Fine-tuning process to break the model's transparency.
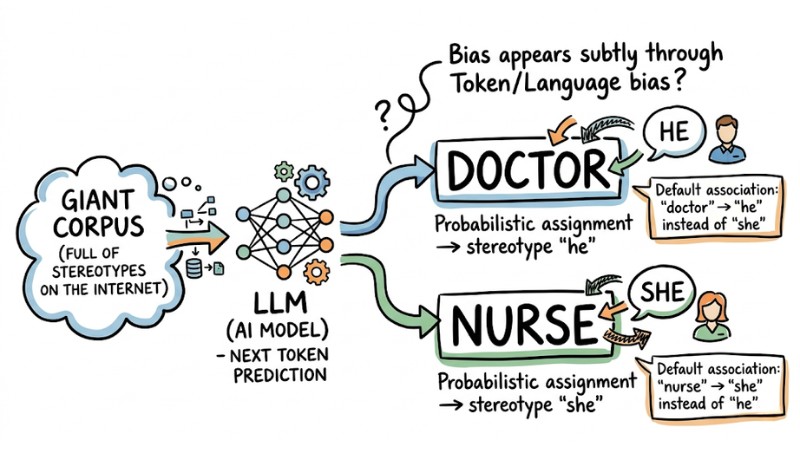
An example of AI Bias on an LLM model
What Should Engineers Do to Mitigate AI Bias?
You cannot expect a Foundation Model to be completely "zero-bias." To control risks, the system must be designed based on a multi-layered defense architecture.
1. Intervention at the Data and Evaluation Layer
Before putting a system into a production environment, evaluating the model mathematically is a mandatory requirement. At the data layer, engineers often use Oversampling techniques (augmenting data for minority groups) to rebalance the dataset.
To measure with actual code, you can use the Fairlearn or AI Fairness 360 libraries in Python. Below is an example of how to measure demographic disparity:
from fairlearn.metrics import demographic_parity_difference
from sklearn.metrics import accuracy_score
# y_true: Actual results, y_pred: AI predicted results
# sensitive_features: Data column containing sensitive variables (e.g., Gender, Race)
# Calculate the difference in positive prediction rates between groups
dp_diff = demographic_parity_difference(
y_true=y_true,
y_pred=y_pred,
sensitive_features=sensitive_features
)
print(f"Demographic Parity Difference: {dp_diff:.4f}")
# Note: If this value is greater than a baseline (e.g., > 0.1),
# the model is showing clear signs of bias against a sensitive group.
These tests not only solve the AI ethics problem but also serve as the foundation for your system to comply with AI risk management frameworks from NIST (USA) and prepare for strict regulations from the EU AI Act.
2. Intervention at the Application and Orchestration Layer
The most important mindset for an engineer is: "The base model always has bias; it must be stopped at the App layer." Technical measures can include:
- Role-based prompt: Wrapping the user's prompt in a hidden System Prompt, forcing the LLM to analyze problems from multiple perspectives and maintain a neutral stance.
- Policy Control: Configuring strict output filters (Guardrails) to block keywords of a stereotypical nature.
- Context Isolation: In a Multi-tenant architecture, if the LLM's memory is not isolated, User A's data will implicitly influence User B, causing cross-contamination of bias. Encrypting and allocating separate Context spaces for each user is the core of safe AI governance.
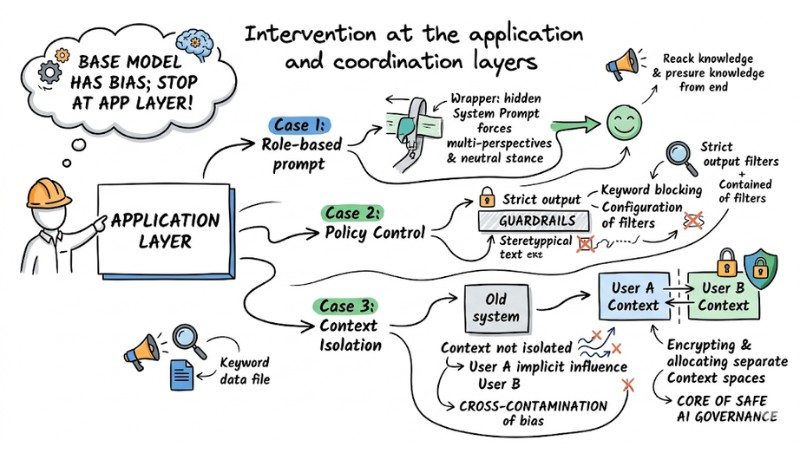
Intervention at the application and coordination layers
Frequently Asked Questions about AI Bias
What is AI bias?
AI bias is a systematic error in the results of an AI model, arising when algorithms reflect human prejudices or training data is unrepresentative. This leads to unfair decisions and discrimination based on gender, race, or other sensitive characteristics.
What are the main causes of bias in AI models?
Bias enters through three stages:
- Unrepresentative training data (lack of diversity in datasets).
- Human subjectivity during labeling.
- The use of "proxy variables."
How to detect and measure AI bias in a system?
Engineers typically use specialized libraries like Fairlearn or AI Fairness 360 to evaluate model fairness across different demographic groups. Periodic monitoring through "challenge" testing is a mandatory step in AI risk management.
Why are LLMs easily affected by linguistic bias?
LLMs learn probabilities from giant corpora created by humans, where vocabulary stereotypes inherently exist (e.g., defaulting to combining "doctor" with males). This causes the model to automatically reproduce and amplify existing gender or cultural prejudices.
What technical solutions help businesses mitigate AI bias risks?
Businesses should apply a multi-layered strategy: Pre-process data to balance samples; use Role-based prompt techniques to force model neutrality; and implement Context Isolation architecture to ensure user data is not cross-contaminated, helping the system operate safely and transparently.
Read more:
- What is Natural Language Processing (NLP)? Roles and Real-world Applications
- What Is an Orchestration Layer? Understanding Its Importance in System Architecture
- Prompt Caching: How to Effectively Optimize LLM API Latency and Costs
Viewed holistically, AI bias is not an error born from a "rebellion" of the machine, but rather a true mirror reflecting the hidden prejudices within human data. AI risk management cannot be solved completely just by cleaning CSV files, but requires an architecture design mindset that spans from algorithmic evaluation to application context management.